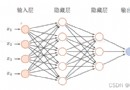
In the last article, I passed ItemLoader Saved a piece of captured data , If you want to save multiple or all captured data , Need parse Method returns a MyscrapyItem Array .
The following example will still grab the blog list page in the previous article example , But it will save all blog data of the crawl page , Include the title of each blog 、 Summary and Url.
import scrapy
from scrapy.loader import *
from scrapy.loader.processors import *
from bs4 import *
from myscrapy.items import MyscrapyItem
class ItemLoaderSpider1(scrapy.Spider):
name = 'ItemLoaderSpider1'
start_urls = [
'https://geekori.com/blogsCenter.php?uid=geekori'
]
def parse(self,response):
# To return MyscrapyItem An array of objects
items = []
# Get the blog list data of the blog page
sectionList = response.xpath('//*[@id="all"]/div[1]/section').extract()
# Process each blog list data through cyclic iteration
for section in sectionList: