As of this publication , In the web version of Jinshan document , If you need to download at the same time 2 More than files , You must open a member . It's easy to think of writing crawlers to download files one by one to achieve the purpose of batch downloading .
You can find that this is not complicated by capturing packets , Select any file and click download , monitor XHR Packet under , The following key packets can be captured :
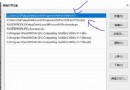
chart 1 Single file loading packet response results 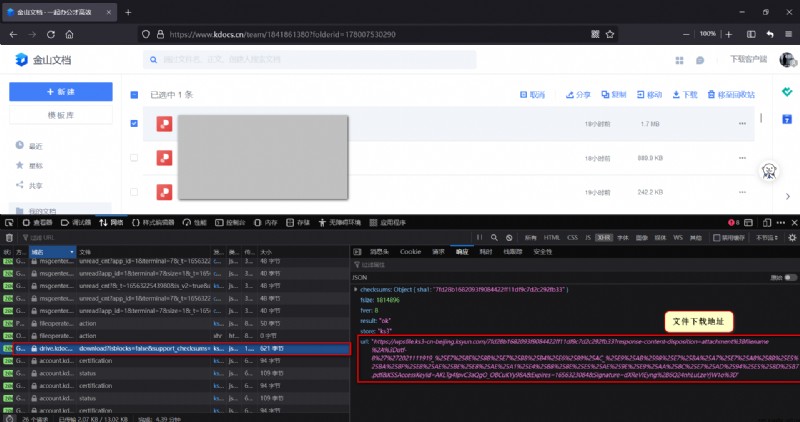
In the response result on the right of the above figure url The field is the file download address , Note that the download address does not need to be logged in , You can access and download in any state ( But there is a validity period ).
Then this thing is very simple , Let's take a look at the request field of this packet :
chart 2 Single file load packet request field 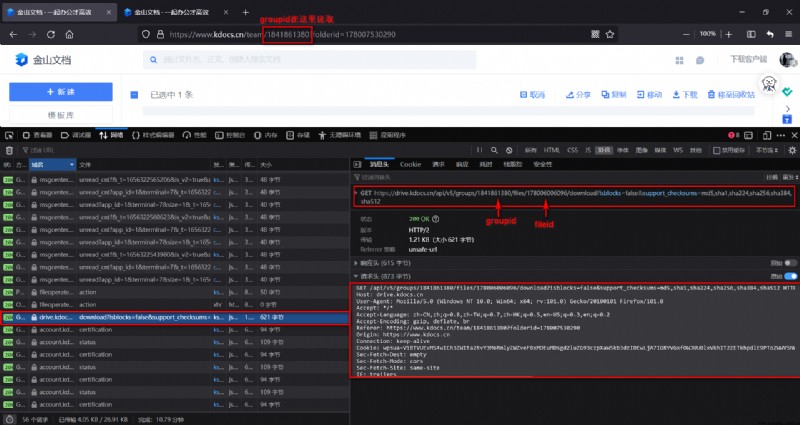
As marked in the figure , Above request URL There are only two variable fields in :groupid And fileid,groupid It's easy to get directly from the current page URL You can read .fileid There are many ways to read , In fact, one of the source code of the current page <script> All files are stored under the tag fileid( Stored in variables window.__API_CACHED__ in , Call directly in the console window.__API_CACHED__ It's fine too ):
chart 3 Page source code window.API_CACHED
This window.__API_CACHED__ For a long , It's time to <script> Take out the complete contents under the label :
chart 4 window.__API_CACHED__ Complete data structure  As shown in the figure above , Information of all documents ( Include
As shown in the figure above , Information of all documents ( Include fileid) Are saved in the field value where the red box is located ( Has been put away ).
You may feel like reading fileid too troublesome , Therefore, you can also call the one given in the red box API Interface ( You can also grab bags ):
https://drive.kdocs.cn/api/v5/groups/{
group_id}/files?include=acl,pic_thumbnail&with_link=true&offset=0&count={
count}
among {group_id} As mentioned above ,{count} That is, the number of files to be obtained , Generally, you can take as many files as there are in this folder , Of course, the login status is required to access this interface , The data returned by the interface is shown in the following figure ( File name blocked , The three red boxes show groupid, file name ,fileid):
chart 5 All file information returned by the interface 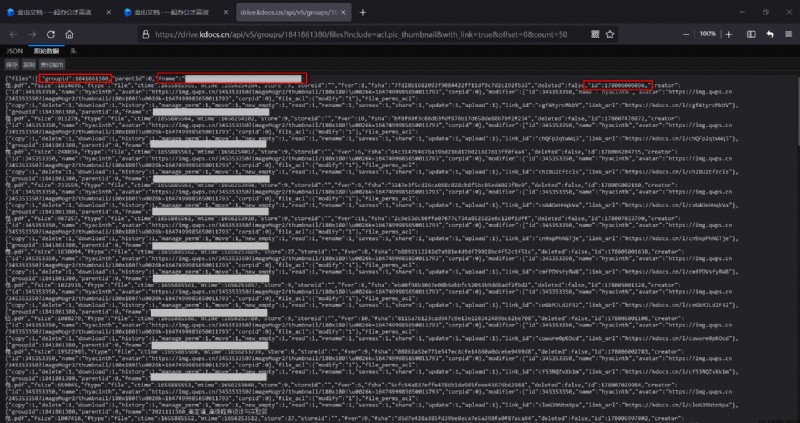
Of all documents groupid and fileid All available , It seems that the problem has been solved , But since it can be written as a blog , It's not that simple .
As the preface says , Key requests such as chart 2 Shown :
chart 2 Single file load packet request field (copy)
Based on past experience , Although the request of this packet must be in login status , But in theory, just attach all the request headers in the lower right box , You should get something like chart 1 Response result of ( That is, the download address of the file ).
Although I resend this request in the browser, I can still get chart 1 Result , It proves that the request is not burn after reading . But if you simply use requests The library makes a request , You can't get the same response :
def cookie_to_string(cookies: list) -> str:
string = ''
for cookie in cookies:
string += '{}={}; '.format(cookie['name'], cookie['value'])
return string.strip()
# Turn the request header in string form into dictionary form headers
def headers_to_dict(headers: str) -> dict:
lines = headers.splitlines()
headers_dict = {
}
for line in lines:
key, value = line.strip().split(':', 1)
headers_dict[key.strip()] = value.strip()
return headers_dict
url = f'https://drive.kdocs.cn/api/v5/groups/{
group_id}/files/{
file_id}/download?isblocks=false&support_checksums=md5,sha1,sha224,sha256,sha384,sha512'
cookies = driver.get_cookies()
headers_string = f"""Host: drive.kdocs.cn User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Accept-Encoding: gzip, deflate, br Connection: keep-alive Cookie: {
cookie_to_string(cookies=cookies)} Upgrade-Insecure-Requests: 1 Sec-Fetch-Dest: document Sec-Fetch-Mode: navigate Sec-Fetch-Site: none Sec-Fetch-User: ?1"""
r = requests.get(url, headers=headers_to_dict(headers=headers_string)) # Unable to get response results
Then this thing seems very strange , I tried for a long time , Also switch to requests.Session test , Still not ok . This shows that Kingsoft document anti crawl is indeed in place , According to the results of successful crawler implementation ,Cookie It does contain all login information , Then I guess Jinshan documents should have made some middleware restrictions on the access process , Or restrict cross domain requests , This is really very unfriendly to reptiles .
But it always needs to be solved , Then we have to turn to omnipotent selenium 了 .
This part will be parsed in combination with the code , Because there are so many pits , But it is also an improvement of reptile skills :
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: [email protected]
import re
import json
import time
import requests
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
def get_download_urls(group_id=1841861380, count=50):
# firefox_profile = webdriver.FirefoxProfile(r'C:\Users\caoyang\AppData\Roaming\Mozilla\Firefox\Profiles\sfwjk6ps.default-release')
# driver = webdriver.Firefox(firefox_profile=firefox_profile)
driver = webdriver.Firefox()
driver.get('https://account.wps.cn/') # The login page
WebDriverWait(driver, 30).until(lambda driver: driver.find_element_by_xpath('//*[contains(text(), "VIU")]').is_displayed())
driver.get('https://www.kdocs.cn/latest')
WebDriverWait(driver, 30).until(lambda driver: driver.find_element_by_xpath('//span[contains(text(), " share ")]').is_displayed())
def cookie_to_string(cookies: list) -> str:
string = ''
for cookie in cookies:
string += '{}={}; '.format(cookie['name'], cookie['value'])
return string.strip()
def headers_to_dict(headers: str) -> dict:
lines = headers.splitlines()
headers_dict = {
}
for line in lines:
key, value = line.strip().split(':', 1)
headers_dict[key.strip()] = value.strip()
return headers_dict
# driver.get(f'https://drive.kdocs.cn/api/v5/groups/{group_id}/files?include=acl,pic_thumbnail&with_link=true&offset=0&count={count}')
# time.sleep(3)
# html = driver.page_source
# windows = driver.window_handles
# print(html)
# print(len(windows))
# print(driver.current_url)
# https://drive.kdocs.cn/api/v5/groups/1841861380/files?include=acl,pic_thumbnail&with_link=true&offset=0&count=50
cookies = driver.get_cookies()
headers_string = f"""Host: drive.kdocs.cn User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Accept-Encoding: gzip, deflate, br Connection: keep-alive Cookie: {
cookie_to_string(cookies=cookies)} Upgrade-Insecure-Requests: 1 Sec-Fetch-Dest: document Sec-Fetch-Mode: navigate Sec-Fetch-Site: none Sec-Fetch-User: ?1"""
r = requests.get(f'https://drive.kdocs.cn/api/v5/groups/{
group_id}/files?include=acl,pic_thumbnail&with_link=true&offset=0&count={
count}', headers=headers_to_dict(headers=headers_string))
html = r.text
json_response = json.loads(html)
files = json_response['files']
print(f' total {
len(files)} File ')
download_urls = []
filenames = []
for file_ in files:
group_id = file_['groupid']
file_id = file_['id']
filename = file_['fname']
print(filename, group_id, file_id)
url = f'https://drive.kdocs.cn/api/v5/groups/{
group_id}/files/{
file_id}/download?isblocks=false&support_checksums=md5,sha1,sha224,sha256,sha384,sha512'
# driver.get(url)
# time.sleep(3)
# html = driver.page_source
cookies = driver.get_cookies()
headers_string = f"""Host: drive.kdocs.cn User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Accept-Encoding: gzip, deflate, br Connection: keep-alive Cookie: {
cookie_to_string(cookies=cookies)} Upgrade-Insecure-Requests: 1 Sec-Fetch-Dest: document Sec-Fetch-Mode: navigate Sec-Fetch-Site: none Sec-Fetch-User: ?1"""
r = requests.get(url, headers=headers_to_dict(headers=headers_string))
html = r.text
# print(html)
json_response = json.loads(html)
download_url = json_response['url']
print(download_url)
download_urls.append(download_url)
filenames.append(filename)
with open('d:/download_urls.txt', 'w') as f:
for download_url, filename in zip(download_urls, filenames):
f.write(filename + '\t' + download_url + '\n')
driver.quit()
get_download_urls()
It is recommended to copy the above code first , The following description will be expanded by the number of lines of code ( Do not delete commented out lines , Those are the pits ).
First of all to see 14-18 That's ok :
At first, I thought about whether to import user data only ( The application of user data in crawlers can be viewed My blog ) You can skip Kingsoft document login . It should be noted that I did not test Chrome Browser situation , however Firefox It really doesn't work , Even if I first open a window to log in to Jinshan documents ( At this point, no matter how many windows I open to access Jinshan documents , Are in login status ), Then start importing user data selenium, Still stuck on the login page . Therefore, we can only comment out 14-15 That's ok .
then 17 Line to access the login page ,18 Line is waiting for login to succeed ( During this period, you can click Wechat login , Then scan the code to confirm ).
Actually used selenium We should all know , If you time.sleep Too long ,selenium It will collapse , If you manually operate on the page ( For example, click on , slide , Input text and so on ),selenium It's going to break down . I always thought selenium After startup, the browser cannot be operated at all , Now I find that I only need to write WebDriverWait( among xpath The user name is searched ,VIU Is my user name ), Then you can click scan code to login , This is very convenient .
Next is 20-21 That's ok :
This special pit , If you log in , Direct access 37 Line interface ( namely chart 5), It does not show chart 5 Result , I'll just tell you The user is not logged in , Therefore, you can only visit the homepage of Jinshan document first . In fact, I think it is possible to restrict the process to reverse crawl .
23-35 Line is two tool functions ,cookie_to_string Yes, it will driver.get_cookies() Back to Cookie Format ( Form like [{'name': name, 'value': 'value'}, ...]) To string Cookie Add to request header ,headers_to_dict Is to rewrite the string request header copied from the browser into a dictionary ( be used for requests.get Of headers Parameters )
37-61 That's ok :
Here comes the pit , At this time, I use 37 Row access chart 5 The interface of can be seen chart 5 The data of , however 39 Yes driver.page_source Return is indeed 20 Go to the homepage of Jinshan document HTML, this TM It hurts . You can see 40 That's ok -43 OK, I did some tests , I have proved that there is really only one window at present (len(windows) by 1), also driver.current_url Display the current page URL Indeed, it is not the homepage of Jinshan document .
It's been a problem for a long time , I checked drivers The function of does not get the page JSON Method of data . I haven't noticed this response before. The result is JSON Your page can't pass driver.page_source Get page data , So I was forced to use requests Library to rewrite this logic (47-61 That's ok ).
Someone may have said , According to the preface , This request response is not and cannot be used requests Get it ? Such is the case , If it is only used alone 47-61 Line to access chart 5 Result , Indeed, what is still returning is The user is not logged in , But here I use drivers.get_cookies() Back to Cookie Information to replace... In the request header copied directly from the browser Cookie Information , It turned out to be miraculously , To be honest, I don't particularly understand the principle here , I don't know how the back-end code of Jinshan document determines whether it is a request made by a crawler .
63-66 That's ok : Get chart 5 File information data .
68-99 That's ok :
What happened here is similar to 37-61 The line is exactly the same , We want to get chart 1 Response result of ( Naturally also JSON Formatted data ), If you still use driver To access the interface , Got driver.page_source It is still on the homepage of Jinshan document HTML, So the same method is used here (requests rewrite ), You can get 96 Line file download address .
similarly , According to the situation in the preface , If you use it directly requests visit chart 2 It's not feasible , But here it is selenium After completing the login operation, it is indeed feasible .
All file download addresses are stored in d:/download_urls.txt in , Because this download address can be used even if it is not logged in , The finishing work is very simple .
with open('d:/download_urls.txt', 'r') as f:
lines = f.read().splitlines()
for line in lines:
filename, url = line.split('\t')
r = requests.get(url)
with open(f'd:/{
filename}', 'wb') as f:
f.write(r.content)
Here is an equivalent JS Code , Theoretically, you can download it by running it directly in the console , But the problem is that cross domain request errors will occur , So it seems that it's still not very good , I wonder if any friends can solve this problem .
let groups = "1842648021";
let count = 54;
let res = await fetch(`https://drive.kdocs.cn/api/v5/groups/${
groups}/files?include=acl,pic_thumbnail&with_link=true&offset=0&count=${
count}&orderby=fname&order=ASC&filter=folder`);
let files = await res.json();
files = files.files;
let urls = []
let fid, info, url;
for (let f of files) {
fid = f.id;
res = await fetch(`https://drive.kdocs.cn/api/v5/groups/${
groups}/files/${
fid}/download?isblocks=false&support_checksums=md5,sha1,sha224,sha256,sha384,sha512`, {
"method": "GET",
"mode": "cors",
"credentials": "include"
});
info = await res.json();
url = info.url;
urls.push(url);
}
console.log(" Number of files to be downloaded :", urls.length);
for (let i = 0; i < urls.length; i++) {
let url = urls[i];
let fname = files[i].fname
fetch(url).then(res => res.blob().then(blob => {
let a = document.createElement('a');
let url = window.URL.createObjectURL(blob);
let filename = fname;
a.href = url;
a.download = filename;
a.click();
window.URL.revokeObjectURL(url);
}))
}
At present, the urgent problem to be solved is selenium visit JSON How should the page read data , I think of a very bullshit method is to use from selenium.webdriver.common.keys import Keys In the direct Ctrl+A,Ctrl+C Copy the page data to get the string , Although this is stupid , But it seems feasible .
Another question is whether there is any way to use requests Without relying on selenium Complete the batch download of Jinshan documents , And why there are problems in the preface , This is really disturbing .
All in all , A mixture of requests and selenium It's really not very beautiful , I think someone should be able to come up with a more beautiful solution .