p.s. High yield Blogger , Pay attention to Neverlost !
Catalog
I.requests Introduction and installation of library
II.requests The basic syntax of the library
III.requests Library GET request
IV.requests Library POST request
IV.requests The agent of the library ip Method
V. Summary
First , Find out what is requests library :
It's a Python Third party Library , Handle URL Resources are particularly convenient , Can completely replace the previous learning urllib library , And more streamlined amount of code ( Compare with urllib library ).
So don't say much , Let's install :
1️⃣ First , We are still open pycharm, Check your python Installation position of interpreter :File - - - > Settings - - - > Project - - - > Python Interpreter

2️⃣ Get into python Interpreter installation directory , Open the terminal : Win + R, Input cmd , enter , Then enter the command cd, hold Scripts Drag folder into cd And execute the switch :
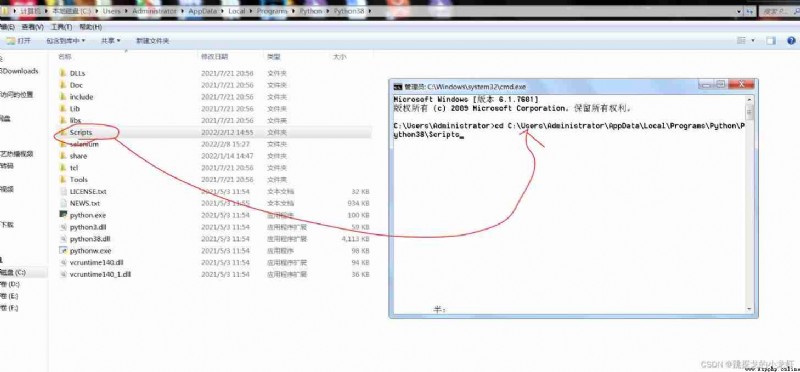
3️⃣ Enter installation instructions and execute :
pip install requests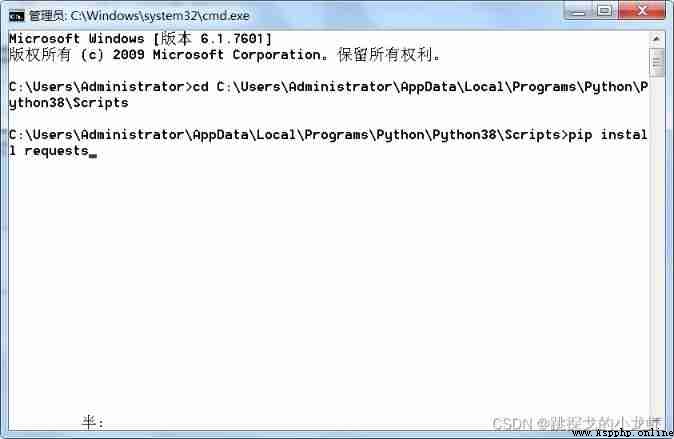
Next , Introduce requests Basic syntax , And urllib The library is similar to ,requests The syntax of the library is roughly divided into one type and six attributes :
First of all, remember urllib library , stay urllib library in , We found through tests that , it The server response obtained is HTTPResponse The type of , and requests The server response obtained by the library is requests.models.Response The type of .
And then we use requests Library simulation browser , Make a normal request to the server , This request is only to assist the following six attributes :
import requests
url = 'http://www.baidu.com'
response = requests.get(url = url)use requests library , We made the request through requests.get() Function Of , Pass reference is the of the destination web page url( There will be other transmission parameters later , Temporarily pass in a url), also use response Variable accepts the response from the server .
Next is requests Six properties of the library :
1️⃣ text attribute : Return the web page source code in string form ( because At this time, the coding format is gbk, The Chinese part may be garbled , Resolve Later )
# (1) text attribute : Return the web page source code in the form of string
print(response.text) # Because there is no coding format , Chinese can be garbled 2️⃣ encoding attribute : Set the corresponding encoding format
# (2) encoding attribute : Set the corresponding encoding format :
response.encoding = 'utf-8'After that response There will be no Chinese garbled code 了 .
3️⃣ url attribute : return url Address
# (3) url attribute : return url Address
url = response.url4️⃣ content attribute : Returns binary data
# (4) content attribute : Returns binary data
content_binary = response.content5️⃣ status_code attribute : Return status code 200 It's normal
# (5) status_code attribute : Return status code 200 It's normal
status_code = response.status_code6️⃣ headers attribute : Return response header
# (6) headers attribute : Return response header
headers = response.headersrequests Library get request The sample code of is as follows :
import requests
url = 'https://www.baidu.com/s?'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
data = {
'wd' : ' Tango crayfish '
}
# Three parameters :
# url: Request path
# params: Request parameters
# kwargs: Dictionaries
# No customization of the request object is required
# Parameters use params To pass
# Parameters do not need to be coded
# At the same time, there is no need to request object customization
# Request path ? Characters can be added or omitted
response = requests.get(url = url,params = data,headers = headers)
response.encoding = 'utf-8'
content = response.text
print(content)You can see that from the top ,requests The most code saving place is , It does not require customization of the request object , If replaced urllib library , We You need to encapsulate a request Request object , Then pass this object into urllib.request.urlopen() function in , And in the requests library in , We Just put three parameters , namely url、data and headers Pass in , Can finish get request , It is very convenient !( The above code executes the search in Baidu ‘ Tango crayfish ’ Returned web page source code )
Next is requests Library post request :
# requests_post request
import requests
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
data = {
'kw' : 'eye'
}
# Four parameters :
# url: Request path
# data: Request parameters
# json data
# kwargs: Dictionaries
response = requests.post(url = url,data = data,headers = headers)
content = response.text
import json
obj = json.loads(content.encode('utf-8'))
print(obj)if get request requests Kubi urllib If it's a little simpler , that post The request is definitely requests Library is more convenient , it Not only does it eliminate the customization of the request object , and The encoding and transcoding of parameters are omitted , so to speak Very convenient , Just and get The three parameters are the same as the request url、data and headers Just pass it in , therefore post Ask someone to strongly recommend requests Library instead of urllib library .
Finally, I'd like to introduce requests Using agents ip The way , It simplifies urllib library , memories urllib Kuyt's agent ip, We need to create handler processor , And define opener object , but requests In the library , We just need to send the agent ip As an ordinary parameter , Pass in requests.get()/requests.post() Function ( It's so convenient !)
# requests_ip agent
import requests
url = 'http://www.baidu.com/s'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
data = {
'wd' : 'ip'
}
proxy = {
'http:' : '218.14.108.53'
}
response = requests.get(url = url, params = data,headers = headers,proxies = proxy)
content = response.textLast , Just to summarize requests library , First of all, for requests library , No longer six ways , It is There are six attributes ; The second is about get Request and post request ,requests Libraries no longer require customization of request objects , and post The request no longer requires codec operations ; Last about ip agent , There is no need to define some intermediate objects , Direct incoming proxy ip, As a general parameter . meanwhile , our requests.get()/requests.post() function , Can pass in four parameters :url、data、headers、ip agent .