p.s. High yield Blogger , Pay attention to Neverlost !( This article is longer , involve selenium Most of it , You can collect it first )
Catalog
I.selenium Installation of Library and download of relevant browser tools
II.selenium The basic syntax of the library
III.selenium Reptile combat cases : obtain jd Secsha page source code
IV.selenium Practical cases of automation gadgets : Simulate real people to log in to the ancient poetry website
V.selenium Learning without interface browser
First , Let's introduce what is selenium library :
selenium It's an automated testing tool , Support Firefox,Chrome And so on The application in crawler is mainly used to solve JS The problem of rendering .
Then we can use selenium What to do :
1️⃣ Reptiles ,selenium Can simulate a real person to open a browser , Therefore, we can better obtain the data we need .( occasionally , Use urllib When the library simulates the browser , Will be recognized by the server , The returned data is missing , So we really need selenium Be a reptile )
2️⃣ Automation gadgets , For example, it can help us operate some browser interaction and so on .
Let's introduce selenium Installation method of Library and related browser tools :
First , We installed selenium library :
1️⃣ open pycharm, choice File - - - > Settings :
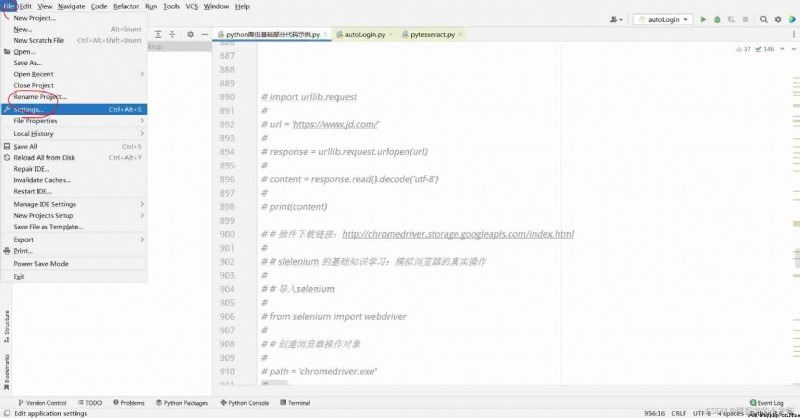
Then we Click on Project - - -> Python Interpreter, Check us out python The location of the interpreter , Get into this position .
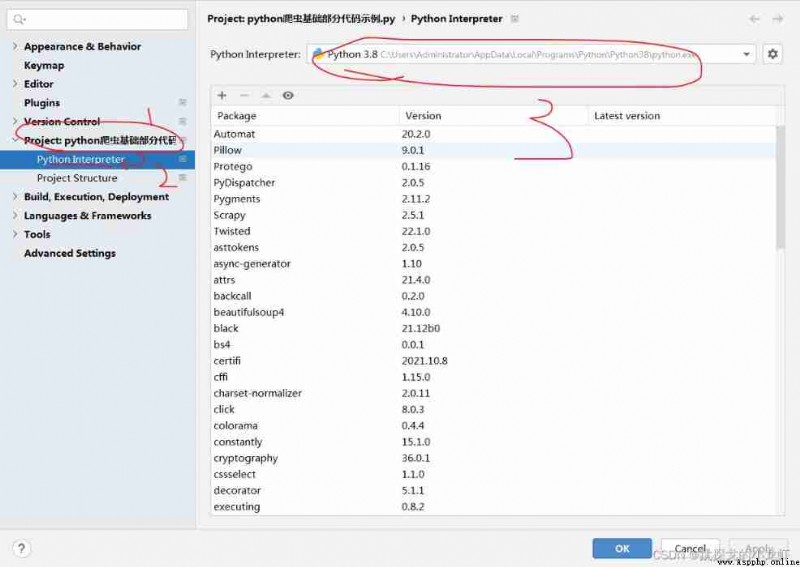
2️⃣ Get into python After the installation position of the interpreter , We Press Win + R, Input cmd, Bring up the terminal :
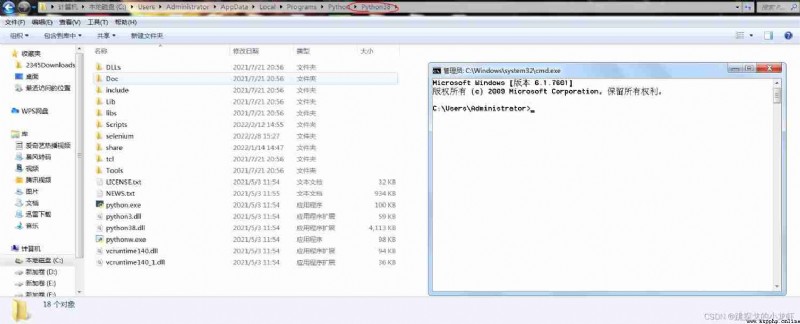
Then we input... At the terminal :cd, and Put the left Scripts Drag folder into cd Cursor after in ( A blank space ), And execute this command :
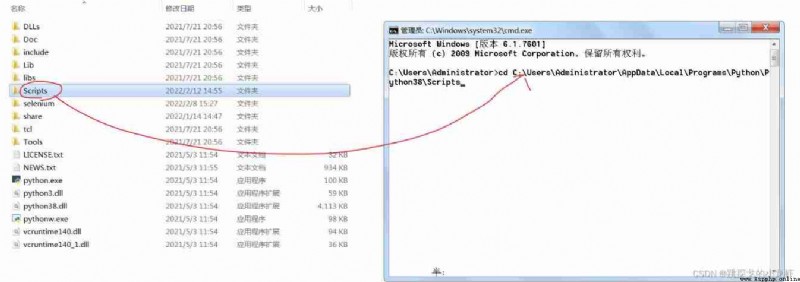
At this time, our terminal has entered Scripts In the folder .
3️⃣ Execute the installation instructions :
pip install selenium==3.4Notice here , Our instructions are install 3.4 Version of selenium, Don't omit == And after that , Otherwise, the installation is selenium The following syntax and operation may be affected by the version problem !
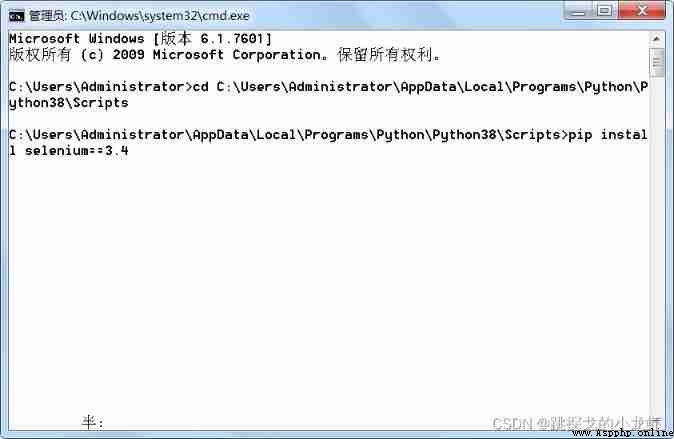
install selenium After the library , Let's go on Install a browser tool that simulates a real person operating the browser :
1️⃣ Visit this address : Browser tools download
Then we can see such a page :

2️⃣ Check the version of your browser :
Take Google browser as an example , We can open any page , Click the three points in the upper right corner of the page , Then choose help - - - > About Google Chrome:
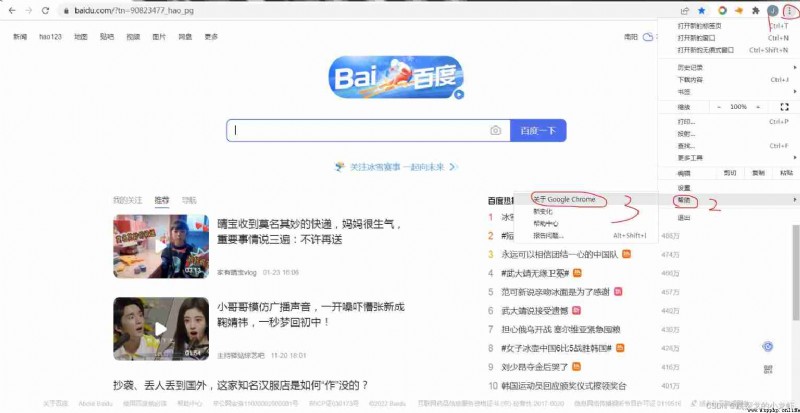
Then we'll see the following page Get the version number of the browser :
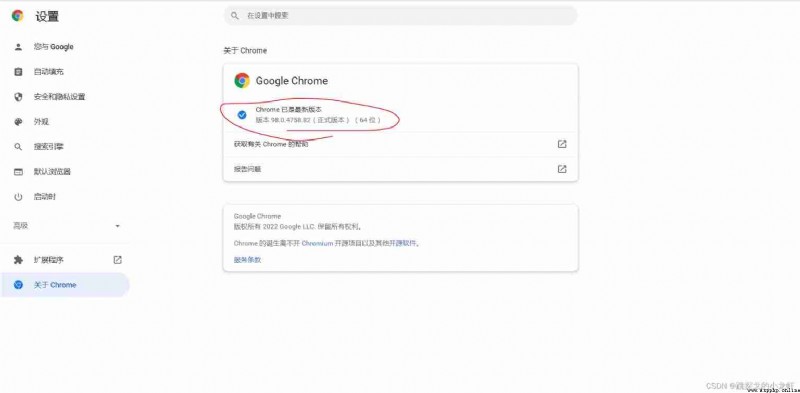
3️⃣ Download the corresponding version of the browser tool :
We According to the version number of Google browser seen above , stay The first step is to find the tool download with the corresponding version number in the open web page that will do .
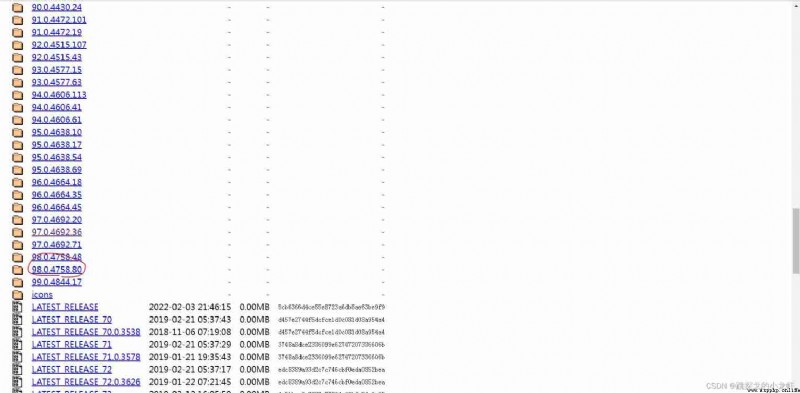
Not everyone , The first few pairs are compatible . After downloading , Put it in python Project folder , Best and python File at the same level , Convenient for later introduction
First of all, let's introduce selenium The basic syntax of the library :
1️⃣ Import selenium library , And initialize the browser operation object :
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)The upper part has done two things : Import selenium library , The browser operation object is initialized . When importing, the format is from selenium import webdriver, After import , We can Create a string variable path,path The value of is the path where we installed the browser tool before , If Installed with this python File in the same level directory , be Just enter its name , Otherwise, use the absolute path !
Last use webdriver.Chrome() function , The incoming path , Create a browser action object browser( The name can be customized ), This object will be used as a helper for us to simulate real people to operate the browser !
2️⃣ Simulated human , Open browser automatically , And access to the source page :
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
content = browser.page_sourceThis step , First, we define the address of the web page to be opened , after Use get() function , Simulate a real person, open the browser and pass in url, meanwhile , our browser The object is also related to this url The binding is established , Subsequent access to source code or node information needs to be through this browser object . Last , adopt page_source function , Get current url Source code of web page .
3️⃣ Several methods of locating elements :
# (1) according to id The property value of the property found the object _ important :
button = browser.find_element_by_id('su')
print(button)
# (2) according to name The property value of the property found the object :
button = browser.find_element_by_name('wd')
print(button)
# (3) according to xpath The statement found the object _ important :
button = browser.find_element_by_xpath('//input[@id = "su"]')
print(button)
# (4) Find the object by the name of the label
button = browser.find_element_by_tag_name('input')
print(button)
# (5) according to CSS Selector found object , amount to bs4 The grammar of _ important :
button = browser.find_element_by_css_selector('#su')
# (6) Find objects based on linked elements :
button = browser.find_element_by_link_text(' Journalism ')So-called Positioning elements , Just Refer to We have some ways Compare the elements on the page with the objects in the actual code ( Variable ) Binding , In order to facilitate the follow-up Get element information by manipulating these objects 、 Actually control or manipulate the elements on the page ( If you've learned front end js、 Android Your friends may Better understanding of such a model ). These show six ways to locate elements , among More important Yes. The first three and the fifth , namely id、name、xpath sentence 、CSS Selector these four ways , The other two are just for understanding .
4️⃣ Acquisition of element information :
# First , Get it on the page id The value is su Of input Input box elements , And variables input Build a binding relationship
input = browser.find_element_by_id('su')
# (1) get_attribute() Function to get the attribute value of the specified attribute of the tag
# The passed parameter is the name of the attribute , for example class、id etc. , Return the property values of these properties
print(input.get_attribute('class'))
# (2) tag_name Function to get the name of the tag corresponding to the element , For example, the element is input label , The return value is input
print(input.tag_name)
# (3) text Function to get the text of the label , Text refers to the contents of the label angle brackets :
# for example :<div> xxx </div> So the result is xxx
print(input.text)Locate the id The value is su Of input After the form element , We put This element and variable input Binding , Then By manipulating the input, We can get information about this form element , There are two important messages : One is The attribute value of the element , You can use the get_attribute() Function to obtain , Of this function The passed parameter is the name of the attribute , such as class、id wait , The property value of this property is returned ; The other is The text in the label , This can be done by text Property acquisition .
5️⃣ selenium Interactive learning :
# (1) Click button :
button.click()
# (2) Enter the specified content in the text box :
input.send_keys('content')
# (3) Slide to the bottom :
js_bottom = 'document.documentElement.scrollTop = 100000'
browser.execute_script(js_bottom)
# (4) Go back to the previous page :
browser.back()
# (5) Go back to the next page :
browser.forward()
# (6) Close the browser :
browser.quit()Be careful , The code above is The premise is to define a button object , Bound to a button object in the page ; Defined a input object , Bound to a text box object in the page ;browser Is the defined browser operation object .
6️⃣ Handle switching operation :
First Introduce the handle :
Handle (Handle) Is an identifier used to identify an object or item , Can be used to describe forms 、 Documents, etc. .
about selenium In terms of operation , Handle switching occurs when switching between multiple windows :

The picture above shows this situation , At this point, we have five windows , When in the first window , We adopt selenium The automation operation clicks a button , A second window opens , here We It does not directly control the elements of the second window , It is You need to switch the handle first .
So let's switch the handle ( window ) It's like this :
windows = browser.window_handles
browser.switch_to.window(windows[index])The first step is to get all the current handles , It returns a list , The second step is to pass in an index value index To windows In the list , About index values , That's the definition :
Root window , That is to say The first window , Its index value is always 0, All subsequent windows , Arrange in reverse order , That is, the index value of the newly opened window is 1, The old windows are arranged back in turn . for instance , The five windows above , If The order of opening is 1 - - - > 2 - - - > 3 - - - > 4 - - - >5, that The corresponding index values in the handle are 0 4 3 2 1 .
After switching windows , Other operations , Including defining binding elements 、 Interaction , Same as before .
After learning the basics , Let's start with a simple reptile case : obtain jd Official website secsha page source code .
First, explain why we use selenium To do this actual battle : When we Use urllib Library urlopen() Function to get the response of the server when , because The server recognizes that we are an analog server rather than a real server , therefore There are a lot of missing data returned , this Equivalent to we can't use urllib Get the complete response from the library .
So we use the following code to achieve the effect we want :
from selenium import webdriver
# Create browser action object
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# (1) Visit website , That is, the operation of imitating human , Open the browser and access the link , use get() function :
url = 'https://miaosha.jd.com'
browser.get(url)
# (2) page_source Get web source :( At this time url It's from the previous step url)
content = browser.page_source
print(content)This case is relatively simple , Don't elaborate , The notes are very detailed .
The following is the simulated real person login ancient poetry network , This is a selenium A small case of simulating human Automation , Let's first analyze the needs : Use selenium library , Automatically open the ancient poetry website through code , And automatically enter login information , To complete the login .
1️⃣ First , We turn on Ancient poetry network :
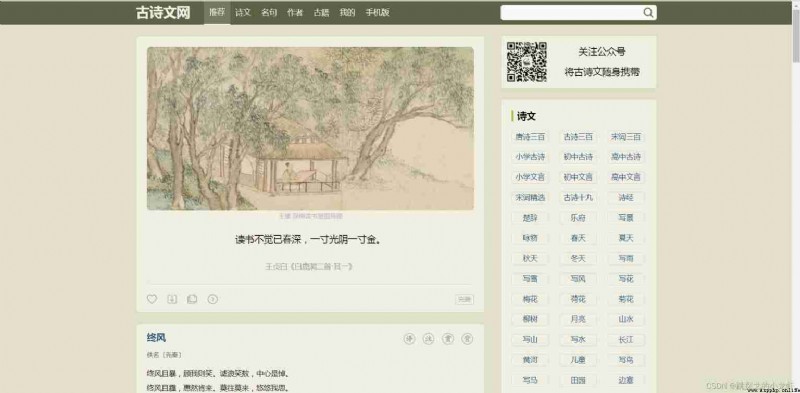
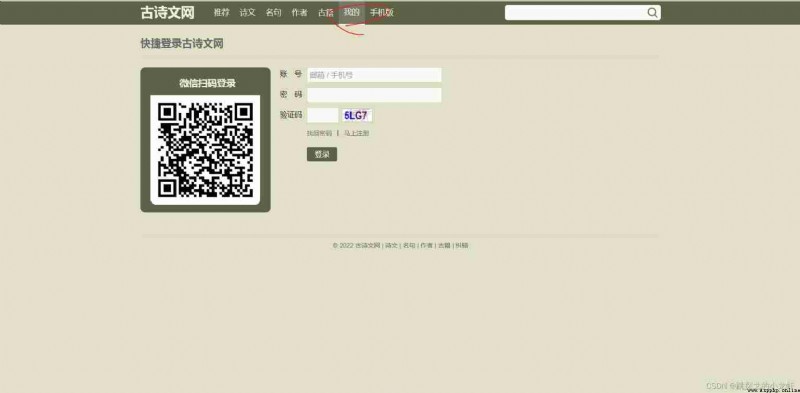
You can see , Our general operation should be : Go to the website - - - > obtain " my " Button - - - > Click on " my " Button - - - > obtain " account number "、" password "、" Verification Code " The text box - - - > Execute the text box to enter the code - - - > obtain " Sign in " Button - - - > Click on " Sign in " Button .
2️⃣ Find the location method of each element :
First , Sure adopt a Elemental href Property value of property , Locate the " my " Button :
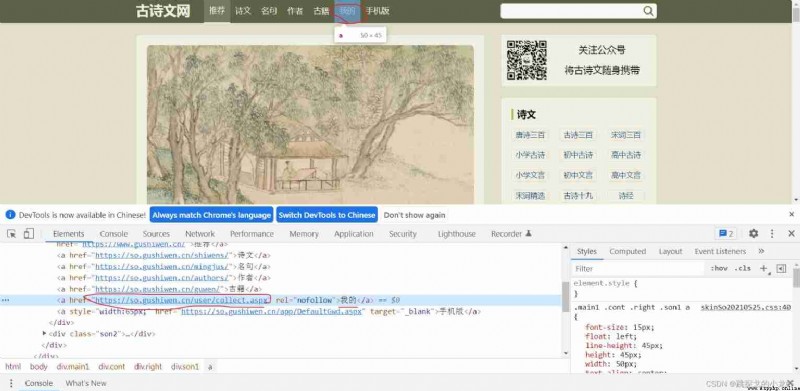
browser.find_element_by_css_selector('a[href = "https://so.gushiwen.cn/user/collect.aspx"]')
secondly , , respectively, Through their respective id, Position several text boxes :
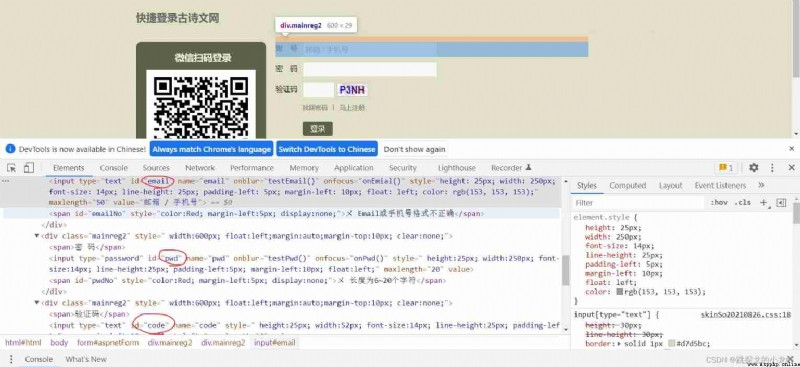
browser.find_element_by_id('email')
browser.find_element_by_id('pwd')
browser.find_element_by_id('code')
Last , Through the login button id value , Locate the login button :
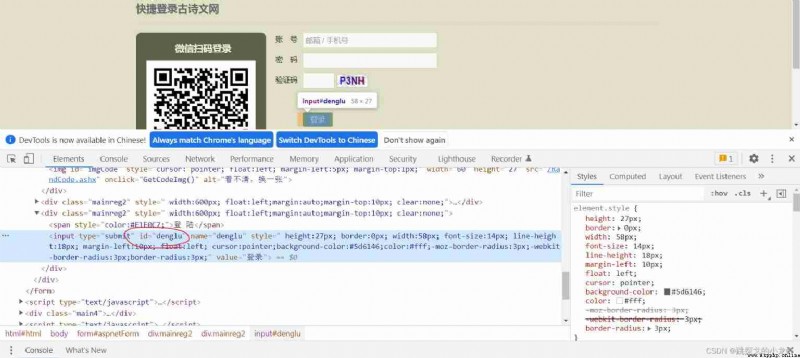
btn_login = browser.find_element_by_id('denglu')
3️⃣ Write the code ( Complete source code ):
# Ancient poetry website login
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# Ancient poetry website official website link :
url = 'https://www.gushiwen.cn/'
# Simulated human , Open the official website of ancient poetry
browser.get(url)
# adopt a Attributes of the tag href="https://so.gushiwen.cn/user/collect.aspx", location : my Button
btn_mine = browser.find_element_by_css_selector('a[href = "https://so.gushiwen.cn/user/collect.aspx"]')
# Click on my Button , Successfully jump to the login page
btn_mine.click()
# Due to switching to a new page , Let's add a little delay :
import time
time.sleep(1)
# adopt id Property value of property , Lock the user name input box element :
input_username = browser.find_element_by_id('email')
# Define a user name that can log in to the ancient poetry website ( Make sure you have registered ):
username = '[email protected]'
# adopt id Property value of property , Lock the password input box element :
input_pwd = browser.find_element_by_id('pwd')
# Define a password matching the user name above ( Make sure you are registered )
password = 'ljl010802'
# Execute the code automatically entered in the text box , Enter the user name and password respectively :
input_username.send_keys(username)
time.sleep(1)
input_pwd.send_keys(password)
# adopt id Property value of property , Lock the verification code input box element :
input_check_code = browser.find_element_by_id('code')
# The processing of captcha : There are three kinds of , It can be entered manually 、 Image recognition and coding platform , Manual input is adopted here :
check_code = input(' Please enter the verification code :')
# Perform automatic input of verification code :
input_check_code.send_keys(check_code)
# adopt id Property value of property , Get login button :
btn_login = browser.find_element_by_id('denglu')
# Click login , Complete the actual combat :
btn_login.click()Be careful , Before the actual combat , First go to the ancient poetry website to register your own account , And put the account number and password in the code above username and password variable .
One last thing : Verification code acquisition , This actual battle adopts the method of manual input , That is to say, we Through the newly opened web page , See the verification code , Then enter the verification code in the console , But there are also Other ways , For example, extract pictures , And through image recognition 、 Coding platform identification And so on , The subsequent notes will specifically introduce the cracking of the verification code !( Of this note Space first , Don't spend too much time on this problem )
Finally, briefly introduce the operation of two non interface browsers :
I learned before selenium library , It's true that the browser opens , But the advantages and disadvantages : slowly , Sometimes we need faster access to data or other things , Therefore, we need to understand the operation of two non interface browsers :
1️⃣ phantomjs
First , We need to download first phantomjs Tools , You can click my online disk link to download :phantomjs ( Extraction code :dxzj)
Then , hold phantomjs Put the tools on python The file is in the same level directory for subsequent import .
Last , Use the following three lines of code , complete phantomjs Import of and creation of browser operation objects :
from selenium import webdriver
path = 'phantomjs.exe'
browser = webdriver.PhantomJS(path)After the above three lines of code , All subsequent operations , And all selenium The operation of the library is the same , Therefore, no further explanation is needed , But at this time, all operations will no longer open the browser , And very fast ( Try it on your own !)
2️⃣ handless
phantomjs Compare with handless, Slightly outdated , Now? handless It is the preferred browser without interface :
# selenium_ No interface to simulate browser operation and learning handless Learning from
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path Here we need to change the path of our own Google browser :
path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options = chrome_options)The upper part is handless The whole process of creating browser operation objects , The above code can be copied directly , The only change is path The variable needs to be changed to its own Chrome Browser path .
in addition , because The above section is for each use handless It's all fixed , We can do The following package :
def handless_browser():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path Here we need to change the path of our own Google browser :
path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options = chrome_options)
return browser
browser = handless_browser()After encapsulation , Every time we Need new handless When the browser operates on objects , Just call the function , Can finish .