The point of this section
One Introduction
Two GIL Introduce
3、 ... and GIL And Lock
Four GIL With multithreading
5、 ... and Multithreading performance test
The point of this sectionmaster Cpython Of GIL Working mechanism of interpreter lock
master GIL And mutex
master Cpython The application scenarios of multithreading and multiprocessing
The duration of this section needs to be controlled 45 Within minutes
One IntroductionDefinition :
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
Conclusion : stay Cpython Interpreter , Multiple threads opened under the same process , Only one thread can execute at the same time , Can't take advantage of multi-core advantages
The first thing to be clear is GIL Not at all Python Characteristics of , It's about achieving Python Parser (CPython) A concept introduced by . like C++ It's a set of languages ( grammar ) standard , But different compilers can be used to compile executable code .
Famous compilers such as GCC,INTEL C++,Visual C++ etc. .Python It's the same thing , The same piece of code can be passed through CPython,PyPy,Psyco Such as different Python Execution environment to execute .
Like one of them JPython There is no GIL. But because CPython Is the default in most environments Python execution environment .
So in many people's concepts CPython Namely Python, Take it for granted GIL It comes down to Python The flaw of language .
So let's be clear here :GIL Not at all Python Characteristics of ,Python It can be completely independent of GIL
Two GIL IntroduceGIL The essence is a mutually exclusive lock , Since it's a mutex , The essence of all mutexes is the same , It's all about making concurrent runs serial , In this way, the shared data can only be modified by one task in the same time , To ensure data security .
One thing for sure is : Securing different data , We should add different locks .
If you want to know GIL, First of all, make sure that : Every time you execute python Program , There will be an independent process . for example python test.py,python aaa.py,python bbb.py Will produce 3 Different python process
verification python test.py There will only be one process
#test.py Content import os,timeprint(os.getpid())time.sleep(1000)# Open terminal execution python3 test.py# stay windows Check out tasklist |findstr python# stay linux Let's have a look at ps aux |grep pythonIn a python In the process of , It's not just test.py The main thread or other threads opened by the main thread , There are also interpreter level threads such as garbage collection enabled by the interpreter , All in all , All threads are running in this process , without doubt
1、 All data is shared , Among them , Code as a kind of data is also shared by all threads (test.py All of the code and Cpython All the code of the interpreter )
for example :test.py Define a function work( The code content is shown in the figure below ), All threads in the process have access to work Code for , So we can start three threads and target All point to the code , Being able to access means being able to execute .
2、 Tasks of all threads , You need to pass the code of the task as a parameter to the code of the interpreter to execute , That is, all threads want to run their own tasks , The first thing to do is to be able to access the interpreter's code .
Sum up :
If there are multiple threads target=work, So the execution process is
Multiple threads access the interpreter's code first , That is, get the execution authority , And then target Code to the interpreter to execute
The interpreter code is shared by all threads , So the garbage collection thread may also access the interpreter's code to execute , This leads to a problem : For the same data 100, Maybe threads 1 perform x=100 At the same time , And garbage collection is to recycle 100 The operation of , There is no wise way to solve this problem , It's lock processing , The following figure GIL, Guarantee python The interpreter can only execute one task at a time
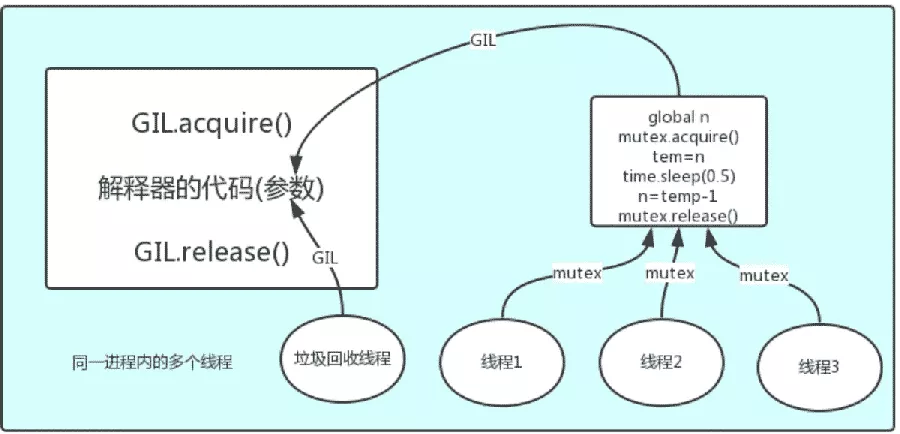
Witty students may ask this question :Python There is already one GIL To ensure that only one thread can execute at a time , Why do we need lock?
First , We need to reach a consensus : The purpose of locks is to protect shared data , Only one thread can modify shared data at a time
then , We can come to a conclusion : Different locks should be added to protect different data .
Last , The problem is clear ,GIL And Lock It's two locks , The data protected is different , The former is interpreter level ( Of course, what is protected is interpreter level data , For example, garbage collection data ), The latter is to protect the data of the application developed by users themselves , Obviously GIL Not in charge of it , Only user-defined lock processing , namely Lock, Here's the picture
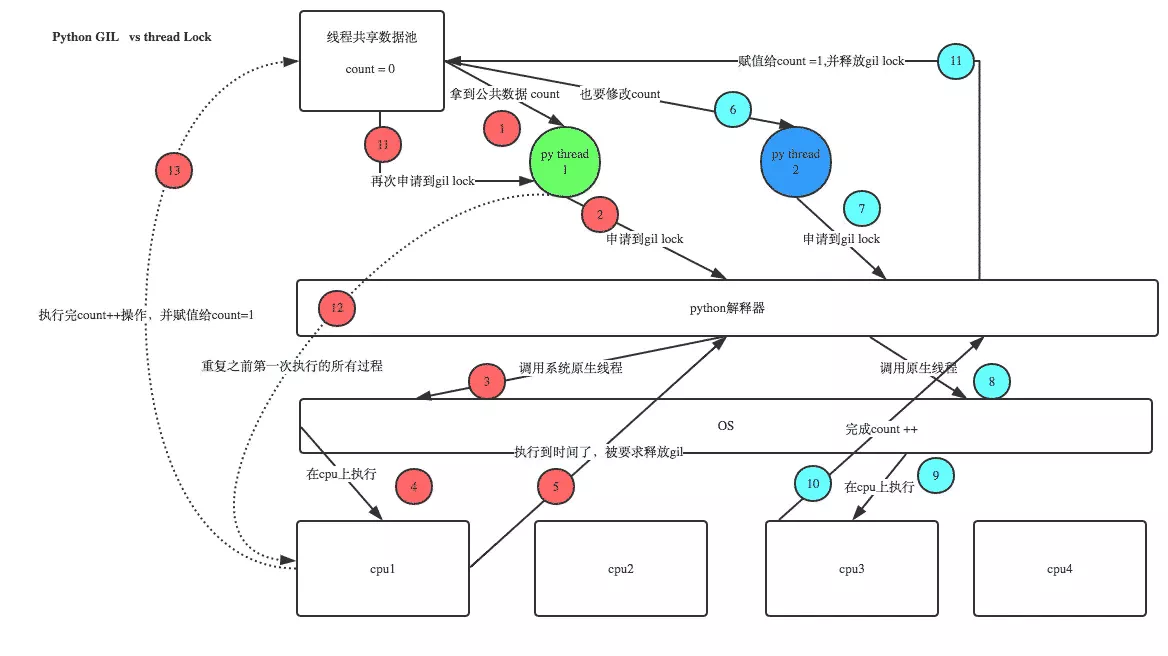
analysis :
1、100 A thread to rob GIL lock , That is, to seize the execution authority
2、 There must be a thread that preempts GIL( Let's call it thread 1), Then start execution , Once executed, you will get lock.acquire()
3、 It's very likely that threads 1 It's not finished yet , There's another thread 2 Grab GIL, Then start running , But threads 2 Found mutex lock Not threaded yet 1 Release , So it's blocking , Forced to surrender executive power , Release GIL
4、 Until the thread 1 Recapture GIL, Start execution from the last suspended position , Until the mutex is released normally lock, Then the other threads repeat 2 3 4 The process of
Code demonstration
from threading import Thread,Lockimport os,timedef work(): global n lock.acquire() temp=n time.sleep(0.1) n=temp-1 lock.release()if __name__ == '__main__': lock=Lock() n=100 l=[] for i in range(100): p=Thread(target=work) l.append(p) p.start() for p in l: p.join() print(n) # The result must be 0, From concurrent execution to serial execution , Sacrificing execution efficiency to ensure data security , Without lock, the result may be 99 Four GIL With multithreading With GIL The existence of , At the same time, only one thread in the same process is executed
I heard that , Some students immediately questioned : Processes can take advantage of multicore , But it's expensive , and python The cost of multithreading is small , But it can't take advantage of multi-core advantages , in other words python useless ,php Is the most powerful language ?
Don't worry , I haven't finished .
To solve this problem , We need to agree on a few points :
1、cpu It's used for calculation , Or to do I/O Of ?
2、 many cpu, It means that you can have multiple cores to do the computation in parallel , So what multi-core improves is computing performance
3、 Every cpu Once encountered I/O Blocking , Still need to wait , So check more I/O There's no use in the operation
A worker is equal to cpu, At this time, the calculation is equivalent to that the workers are working ,I/O Blocking is the process of providing raw materials for workers to work , If there are no raw materials in the process of working , Then the workers need to stop working , Until the arrival of raw materials .
If most of the tasks your factory does have to prepare raw materials (I/O intensive ), Then you have more workers , It doesn't make much sense , It's better to be alone , Let the workers do other jobs while waiting for the materials ,
On the contrary , If your factory has all the raw materials , Of course, the more workers there are , The more efficient
Conclusion :
1、 For calculation ,cpu The more the better , But for I/O Come on , More cpu It's no use
2、 Of course, for running a program , With cpu The increase of execution efficiency will definitely improve ( No matter how much the increase , There will always be improvement ), This is because a program is basically not pure computing or pure I/O, So we can only relatively see whether a program is computationally intensive or I/O intensive , So as to further analyze python Is multithreading really useful
Suppose we have four tasks to deal with , The way to deal with it must be to play concurrent effects , The solution can be :
Scheme 1 : Start four processes
Option two : Under one process , Open four threads
In the case of a single core , The results of the analysis :
If the four tasks are compute intensive , There's no multicore for Parallel Computing , Scenario 1 increases the overhead of creating a process , Plan two wins
If the four tasks are I/O intensive , The cost of creating process in scheme 1 is high , And the switching speed of the process is far less than that of the thread , Plan two wins
In the case of multicore , The results of the analysis :
If the four tasks are compute intensive , Multicore means parallel computing , stay python In a process, there is only one thread executing at the same time , A plan wins
If the four tasks are I/O intensive , No amount of cores can solve I/O problem , Plan two wins
Conclusion :
Today's computers are basically multicore ,python The efficiency of multithreading for computing intensive tasks does not bring much performance improvement , Not even serial ( There's not a lot of switching ), however , about IO The efficiency of intensive tasks has been significantly improved .
5、 ... and Multithreading performance testIf multiple concurrent tasks are computationally intensive : Multi process efficiency
from multiprocessing import Processfrom threading import Threadimport os,timedef work(): res=0 for i in range(100000000): res*=iif __name__ == '__main__': l=[] print(os.cpu_count()) # This machine is 4 nucleus start=time.time() for i in range(4): p=Process(target=work) # Time consuming 5s many p=Thread(target=work) # Time consuming 18s many l.append(p) p.start() for p in l: p.join() stop=time.time() print('run time is %s' %(stop-start))If multiple concurrent tasks are I/O intensive : Multithreading is efficient
from multiprocessing import Processfrom threading import Threadimport threadingimport os,timedef work(): time.sleep(2) print('===>')if __name__ == '__main__': l=[] print(os.cpu_count()) # This machine is 4 nucleus start=time.time() for i in range(400): # p=Process(target=work) # Time consuming 12s many , Most of the time is spent creating processes p=Thread(target=work) # Time consuming 2s many l.append(p) p.start() for p in l: p.join() stop=time.time() print('run time is %s' %(stop-start))application :
Multithreading is used for IO intensive , Such as socket, Reptiles ,web
Multiprocesses are used for compute intensive , Such as financial analysis
That's all Python Parser Cpython Of GIL Details of working mechanism of interpreter lock , More about Python Cpython Interpreter lock GIL Please pay attention to other relevant articles of software development network !