Traditional similarity algorithm : Calculation of text similarity , Generally, vector space model is used (VSM), First, the text word segmentation , The extracted features , Build text vector according to features , The calculation of similarity between texts is transformed into the calculation of feature vector distance , Such as European distance 、 Cosine angle, etc .
shortcoming : In the case of big data, the complexity will be very high .
Simhash Application scenarios : Calculate large-scale text similarity , To achieve mass text information de duplication .
Simhash Algorithm principle : adopt hash Value comparison similarity , Calculated from two strings hash value , To perform exclusive or operations , Then we get the number of differences , The larger the number, the greater the difference .
Word frequency (TF): The ratio of the number of times a word appears in the whole article to the total number of words ;
Reverse word frequency (IDF): A word , It appears very frequently in all articles , This word is not representative , Can reduce its effect , That is to give it a smaller weight .
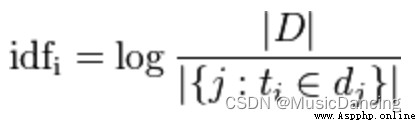
The numerator represents the total number of articles , The denominator indicates the number of articles in which the word appears . Generally, the denominator is added to one , Prevent denominator from being 0 The situation of , Take the logarithm after this ratio , Namely IDF 了 .
Final use tf*idf Get the weight of a word , Then calculate the key words of an article . Then, according to the method of comparing the keywords of each article, the article is de duplicated .simhash The algorithm balances efficiency and performance , It can be compared very little ( Don't take too many keywords ), And have good representativeness ( Keywords should not be too few ).
Simhash It's a kind of local sensitivity hash. It is assumed that A、B With certain similarity , stay hash after , Can still maintain this similarity , Call it local sensitivity hash.
Get an article keyword set , adopt hash The method of the keyword set hash Into a string of binary , Direct comparison of binary numbers , The similarity is the similarity between two documents , Hamming distance is used to check the similarity , That is, when comparing binary , See how many of them are different , Just call Hemingway's distance .
Will the article simhash Get a bunch of 64 Binary of bit , According to experience, Hamming distance is generally taken as 3 As a threshold , That is to say 64 In bit binary , As long as there are no more than three different , It can be considered that the two documents are similar , The threshold here can also be set according to your own needs . That is to put a document hash Then get a string of binary number algorithm , Call this hash by simhash.
simhash The specific implementation steps are as follows :
1. Break the document into words , Take the... Of an article TF-IDF The top with the highest weight 20 Word (feature) And weight (weight). That is, a document with a length of 20 Of (feature:weight) Set .
2. For the words (feature), After ordinary hashing, we get a 64 Binary for , We get a length of 20 Of (hash : weight) Set .
3. according to (2) Get a string of binary numbers (hash) The corresponding position in is 1 yes 0, Take positive value for corresponding position weight And negative weight. For example, a word has entered (2) obtain (010111:5) Go through the steps (3) Then you can get a list [-5,5,-5,5,5,5]. And that gives us 20 A length of 64 A list of [weight,-weight...weight] Represents a document .
4. Yes (3) in 20 A list is obtained by column wise accumulation of lists . Such as [-5,5,-5,5,5,5]、[-3,-3,-3,3,-3,3]、[1,-1,-1,1,1,1] Perform column accumulation to obtain [-7,1,-9,9,3,9], such , We get... For a document , A length of 64 A list of .
5. Yes (4) To determine each value in the list obtained in , When it is negative, go to 0, Positive value 1. for example ,[-7,1,-9,9,3,9] obtain 010111, So you get a document simhash The value of .
6. Calculate similarity . Two simhash Take XOR , Look at it 1 Whether the number of is more than 3. exceed 3 Is determined to be dissimilar , Less than or equal to 3 Is determined to be similar .
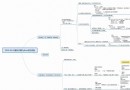
Simhash The overall flow chart is as follows :
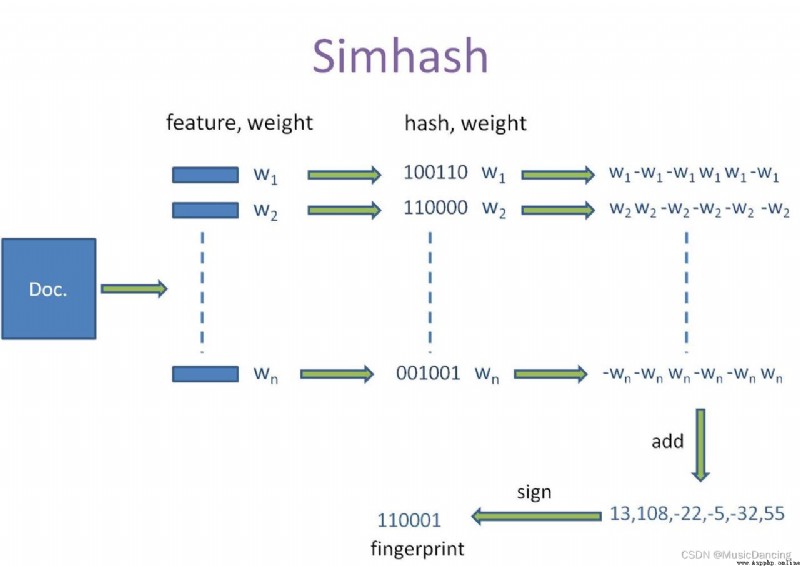
Completely irrelevant text corresponds to the same simhash, The accuracy is not very high , and simhash More suitable for longer text , But when the large-scale corpus is de duplicated ,simhash The advantage of computing speed is still very good .
# !/usr/bin/python
# coding=utf-8
class Simhash:
def __init__(self, tokens='', hashbits=128):
self.hashbits = hashbits
self.hash = self.simhash(tokens)
def __str__(self):
return str(self.hash)
# Generate simhash value
def simhash(self, tokens):
v = [0] * self.hashbits
for t in [self._string_hash(x) for x in tokens]: # t by token Ordinary hash value
for i in range(self.hashbits):
bitmask = 1 << i
if t & bitmask:
v[i] += 1 # View the current bit Whether a is 1, If yes, this bit +1
else:
v[i] -= 1 # Otherwise , This bit -1
fingerprint = 0
for i in range(self.hashbits):
if v[i] >= 0:
fingerprint += 1 << i
return fingerprint # Of the entire document fingerprint For the final bits >=0 And
# Find Hamming distance
def hamming_distance(self, other):
x = (self.hash ^ other.hash) & ((1 << self.hashbits) - 1)
tot = 0
while x:
tot += 1
x &= x - 1
return tot
# Look for similarity
def similarity(self, other):
a = float(self.hash)
b = float(other.hash)
if a > b:
return b / a
else:
return a / b
# in the light of source Generate hash value
def _string_hash(self, source):
if source == "":
return 0
else:
x = ord(source[0]) << 7
m = 1000003
mask = 2 ** self.hashbits - 1
for c in source:
x = ((x * m) ^ ord(c)) & mask
x ^= len(source)
if x == -1:
x = -2
return x
test
if __name__ == '__main__':
s = 'This is a test string for testing'
hash1 = Simhash(s.split())
s = 'This is a string testing 11'
hash2 = Simhash(s.split())
print(hash1.hamming_distance(hash2), " ", hash1.similarity(hash2))