Take iris data as an example , First load the dataset .
from sklearn.datasets import load_iris
dataset = load_iris()
# print(dataset)
X = dataset.data
y = dataset.target
You can check the basic characteristics of the data
print(X)
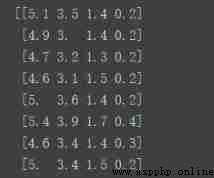
print(y)
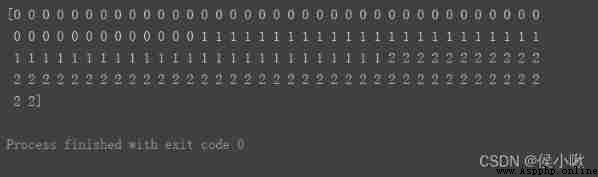
from sklearn.preprocessing import MinMaxScaler
X_transformed = MinMaxScaler().fit_transform(X)
print(X_transformed)
Program execution result :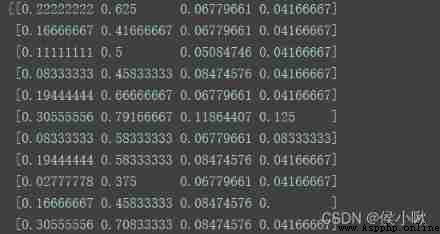
Instantiation MinMaxScaler() Relevant attributes can be passed in
MinMaxScaler(self, feature_range=(0, 1), *, copy=True, clip=False)
Example
from sklearn.preprocessing import MinMaxScaler
MinMaxScaler(feature_range=(0, 0.5), copy=False).fit_transform(X)
print(X)
Program execution result :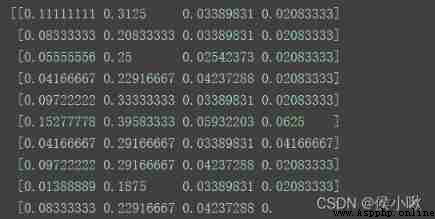
from sklearn.preprocessing import Normalizer
X_transformed = Normalizer().fit_transform(X)
print(X_transformed)
Program execution result :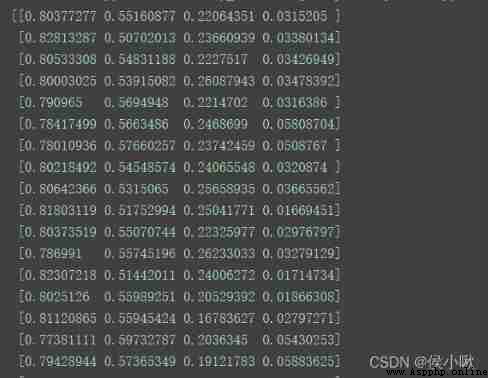
(self, norm=‘l2’, *, copy=True)
norm The default is ’l2’( It's the letters l Not numbers 1). The available values are "l1",“l2”,“max”.
'l2’ Express , The transformation mode is , Each eigenvalue , Convert to the square of the eigenvalue , The ratio of the square of all eigenvalues of the sample .
namely
X i ′ = X i 2 ∑ X i 2 \displaystyle X_i'=\frac{ {X_i}^2}{\sum {X_i}^2} Xi′=∑Xi2Xi2
'l1’ Express , The transformation mode is , Each eigenvalue , Convert to Its ratio to the sum of absolute values of each eigenvalue of the sample .
'max’ Express , The transformation mode is , Divide each eigenvalue by the largest eigenvalue in the sample .
copy ditto , That is, whether to copy . The default is True Represents replication , Replication does not change the original dataset .
from sklearn.preprocessing import Normalizer
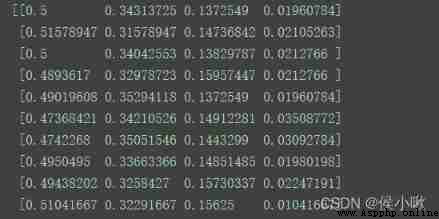
X_transformed = Normalizer(norm='l1').fit_transform(X)
print(X_transformed)
Program execution result :
from sklearn.preprocessing import StandardScaler
X_transformed = StandardScaler().fit_transform()
print(X_transformed)
Program execution result :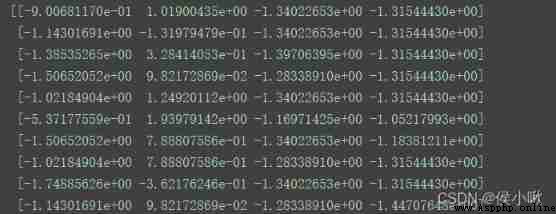
StandardScaler(self, *, copy=True, with_mean=True, with_std=True)
The default threshold is 0, Greater than 0 The data is converted to 1, Less than 0 All the data is converted into 0.
from sklearn.preprocessing import Binarizer
X_transformed = Binarizer().fit_transform(X)
print(X_transformed)
Program execution result :
(self, *, threshold=0.0, copy=True)
from sklearn.preprocessing import Binarizer
X_transformed = Binarizer(threshold=3).fit_transform(X)
print(X_transformed)
Program execution result :