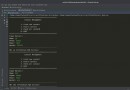
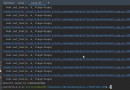
The pipeline saves each step of the data mining process in the workflow .
Pipeline is used in the process of data mining , It can greatly reduce the complexity of code and operation , Optimize process structure , It can effectively reduce the occurrence of common problems .
Pipeline passing Pipeline() To instantiate , The attributes that need to be passed in are a series of data mining steps , The first few of them are converters , The last one must be the estimator .
Take the classic iris data as an example , Through the following code of this simple example , Let's compare the difference between using and not using the code under the pipeline .
The specific process is : After data acquisition , First, normalize , Then use the nearest neighbor algorithm to predict , Finally, cross check is used to output the average accuracy .
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
# get data
dataset = load_iris()
# print(dataset)
X = dataset.data
y = dataset.target
X_transformed = MinMaxScaler().fit_transform(X)
estimator = KNeighborsClassifier()
scores = cross_val_score(estimator, X_transformed, y, scoring='accuracy')
print(" The prediction accuracy is {0:.1f}%".format(np.mean(scores) * 100))

scaling_pipeline = Pipeline([('scale', MinMaxScaler()),
('predict', KNeighborsClassifier())])
scores = cross_val_score(scaling_pipeline, X, y, scoring='accuracy')
print(" The prediction accuracy is {0:.1f}%".format(np.mean(scores) * 100))

The inspection accuracy is also 96.0%, It achieves the same effect as the traditional writing above .