一、安裝 Selenium和ChromeDriver
二、安裝Geoserver必要插件
三、關於Selenium中XPath的使用技巧
四、腳本編寫
首先,聲明一下,這裡我完成的腳步屬於半自動化的,我戲稱它為“有監督的半自動化”腳本。具體原因後面會詳細說明。
一、安裝 Selenium和ChromeDriver安裝Selenium:
pip install selenium安裝ChromeDriver
ChromeDriver下載地址: chromedirver.
注意:下載的版本號要和自己Chrome版本號一樣
二、安裝Geoserver必要插件注意:安裝的geoserver插件版本要和安裝的geoserver版本號完全一致,否則會報錯
1.安裝Mongodb插件:
以我的本地geoserver版本為例:
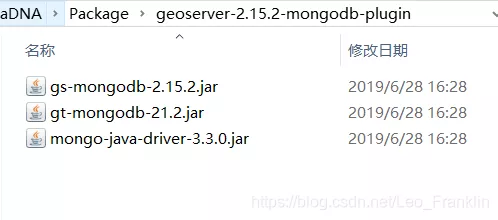
解壓後得到的jar文件
將得到的jar文件粘貼到這裡,重啟tomcat服務器即可安裝
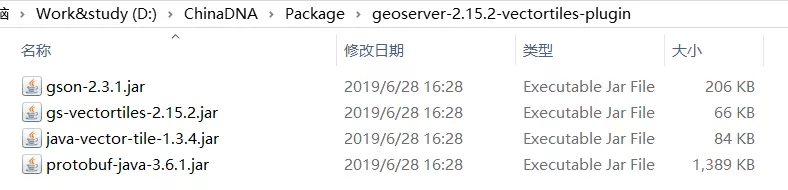
2.安裝矢量插件
這是從官網插件下載後的並且解壓後的樣子,安裝方式同Mongo插件一樣
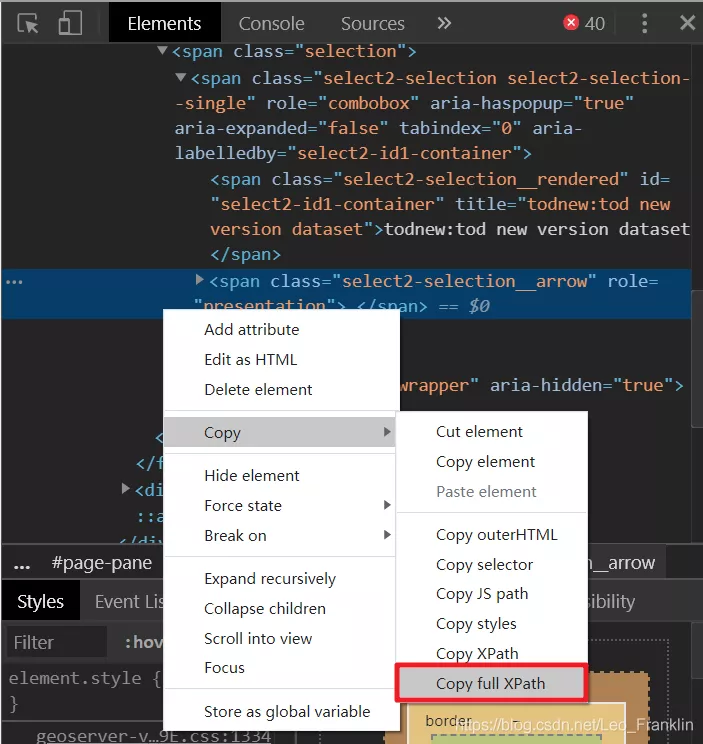
1.在要操作的網站按F12打開Chrome的調試工具,選擇元素選擇工具,如下圖所示:

2.選擇你要操作的元素,如下所示:在這裡插入圖片描述
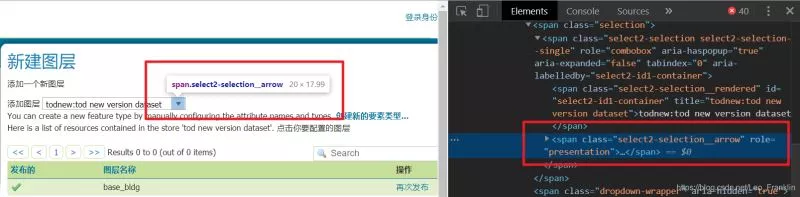
3.右鍵Copy,選擇復制完整的XPath路徑,這樣就可以精准的引用到代碼中了。
完整代碼如下:
from selenium import webdriverfrom selenium.webdriver.support.ui import Selectimport timecount = 0 # 用於統計帶發布圖層個數wd = webdriver.Chrome()wd.implicitly_wait(5) # 隱藏式等待wd.get('http://localhost:8080/geoserver/web/') # 鏈接本地的geoserverwd.find_element_by_id("username").send_keys("admin") # 填入用戶名wd.find_element_by_id("password").send_keys("geoserver") # 填入密碼wd.find_element_by_css_selector(".positive").click()time.sleep(1)wd.find_element_by_xpath('//*[@id="navigation"]/li[2]/ul/li[4]/a/span').click() # 選擇圖層頁time.sleep(1)wd.find_element_by_xpath('//*[@id="page"]/div[1]/div[2]/ul/li[1]/a').click() # 新建圖層time.sleep(1)select = Select(wd.find_element_by_css_selector(".select2-hidden-accessible")) # 選擇工作區time.sleep(1)select.select_by_index(4) # 這裡數字根據需求自行調整elements = wd.find_elements_by_xpath('/html/body/div[2]/div/div[2]/div[2]/div/div[2]/div/table/tbody/tr[*]/td[2]/span')# 統計MongoDB中待發布的圖層個數for element in elements: print(element.text) count = count + 1print(count)wd.find_element_by_xpath('//*[@id="navigation"]/li[2]/ul/li[4]/a/span').click() # 退回到圖層頁for i in range(1, count): #這裡的count可以不用,直接自己指定范圍 wd.find_element_by_xpath('//*[@id="page"]/div[1]/div[2]/ul/li[1]/a').click() # 新建圖層 time.sleep(1) select = Select(wd.find_element_by_css_selector(".select2-hidden-accessible")) # 選擇工作區 time.sleep(1) select.select_by_index(14) # 這裡數字根據需求自行調整 time.sleep(1) wd.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[2]/div/div[2]/div/table/tbody/tr['+ str(i) + ']/td[3]/span/a/span').click() # 點擊進入發布配置 time.sleep(1) wd.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[2]/form/div[2]/div[2]/div[1]/div/ul/div/li[2]/fieldset/ul/li[1]/div[2]/a[1]').click() # 選擇范圍 time.sleep(6) wd.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[2]/form/div[2]/div[2]/div[1]/div/ul/div/li[2]/fieldset/ul/li[2]/a').click()# 選擇范圍 time.sleep(6) wd.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[2]/form/div[2]/div[1]/ul/li[4]/a/span').click() # 切換到title cacheing time.sleep(1) wd.find_element_by_xpath("/html/body/div[2]/div/div[2]/div[2]/form/div[2]/div[2]/div/fieldset/ul/li[2]/div/ul/li[6]/div[1]/input").click() # 點擊需要添加的矢量切片 # time.sleep(1) wd.find_element_by_xpath("/html/body/div[2]/div/div[2]/div[2]/form/div[2]/div[2]/div/fieldset/ul/li[2]/div/ul/li[6]/div[2]/input").click() # 點擊需要添加的矢量切片 # time.sleep(1) wd.find_element_by_xpath("/html/body/div[2]/div/div[2]/div[2]/form/div[2]/div[2]/div/fieldset/ul/li[2]/div/ul/li[6]/div[3]/input").click() # 點擊需要添加的矢量切片 # time.sleep(1) wd.find_element_by_xpath("/html/body/div[2]/div/div[2]/div[2]/form/div[2]/div[2]/div/fieldset/ul/li[2]/div/ul/li[6]/div[4]/input").click() # 點擊需要添加的矢量切片 # time.sleep(1) wd.find_element_by_xpath("/html/body/div[2]/div/div[2]/div[2]/form/div[2]/div[2]/div/fieldset/ul/li[2]/div/ul/li[7]/input").send_keys(10) # 添加時長 # time.sleep(1) wd.find_element_by_xpath("/html/body/div[2]/div/div[2]/div[2]/form/div[2]/div[2]/div/fieldset/ul/li[2]/div/ul/li[8]/input").send_keys(10) # 添加時長 # time.sleep(1) wd.find_element_by_css_selector("#page div.button-group.selfclear > a:nth-child(1)").click() time.sleep(1)解釋一下:代碼中出現了time.sleep(6),6秒,大家可能會覺得等待的時間有些長,但是這是博主在實踐中覺得可行的時間。因為有的地方數據量太大,geoserver計算邊框時會耗時較長,導致崩潰,如果大家的數據量較小,則可以把,這裡的時間調小,或者沒有。
這裡Mongon的鏈接之類的工作都是在,之前手動操作的,沒有做自動化,畢竟也沒有多少,這就是半自動化,而監督是腳本執行過程中如果還是避免不了,計算時間過長,則相應圖層手動發布,之後的調整代碼for循環的range後再次執行即可。
再給大家曬一下geoserver計算邊框時長超過的後果:

到此這篇關於Python+Selenium實現在Geoserver批量發布Mongo矢量數據的文章就介紹到這了,更多相關Python批量發布Mongo矢量數據內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!