xpath yes python The most commonly used data parsing method for crawlers , I think it's also the simplest , It is also very versatile , Why is it the simplest . There are two main steps .
1、 Instantiate a etree object , And the parsed page source code data needs to be loaded into the object .
2、 call etree Object xpath Method , combination xpath Expressions locate labels and crawl content text or attributes .
How to instantiate a etree What about objects? ? First download lxml Library and import etree package , And then it will be the local HTML The document source code data is loaded into etree In the object , Or load the real-time web page source code data into etree in .
from lxml import etree
# Will local html You can only get the text content directly below the tag
tree = etree.parse('./douban.html')
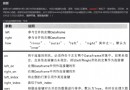
print(tree.xpath('/html/head/title'))
>> [<Element li at 0x1458ddbbc80>]from lxml import etree
import requests
# Load the web page source code data into the object
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="slist"]/ul/li')
print(li_list)
>> [<Element li at 0x1458ddbbc80>]The local is etree.parse, Page is etree.HTML
The return here is not local or web html Content in the document , It is a Element Object of type , This object stores title Corresponding text content , If there are multiple contents , In the form of a list , Return multiple Element.
xpath Rules for expressions :
/: The representation is a hierarchy , Locate from the root node .
//: It represents multiple levels , You can start from any node .
Attribute positioning ://div[@class="title"] Add... Before the attribute @.
The index position ://div[@class="title"]/a[1] The subscript is from 1 Not at first 0 Start .
/text(): Get the immediate text content in the tag .
//text(): You can get all the text content of a label .
@attrName: Add... Before the attribute @, You can get the attribute content .
Next, let's tell you , How to write one quickly xpath route .
We can open developer tools on the web page where we want to crawl data ( Right click to check or press fn and f12 Open the developer tool ), Then in the element (Element) Find the data you want to crawl, right-click and select Copy , Choose to copy again XPath, That's all right. , Is it convenient .
Above is xpath More commonly used methods , Of course xpath There are many other ways , If you are interested, you can check the relevant documents .