今天小編來和大家聊一下Python當中的altair可視化模塊,並且通過調用該模塊來繪制一些常見的圖表,借助Altair,我們可以將更多的精力和時間放在理解數據本身以及數據的意義上面,從復雜的數據可視化過程中解脫出來。
Altair被稱為是統計可視化庫,因為它可以通過分類匯總、數據變換、數據交互、圖形復合等方式全面地認識數據、理解和分析數據,並且其安裝的過程也是十分的簡單,直接通過pip命令來執行,如下
pip install altair
pip install vega_datasets
pip install altair_viewer如果使用的是conda包管理器來安裝Altair模塊的話,代碼如下
conda install -c conda-forge altair vega_datasets我們先簡單地來嘗試繪制一個直方圖,首先創建一個DataFrame數據集,代碼如下
df = pd.DataFrame({"brand":["iPhone","Xiaomi","HuaWei","Vivo"],
"profit(B)":[200,55,88,60]})接下來便是繪制直方圖的代碼
import altair as alt
import pandas as pd
import altair_viewer
chart = alt.Chart(df).mark_bar().encode(x="brand:N",y="profit(B):Q")
# 展示數據,調用display()方法
altair_viewer.display(chart,inline=True)output
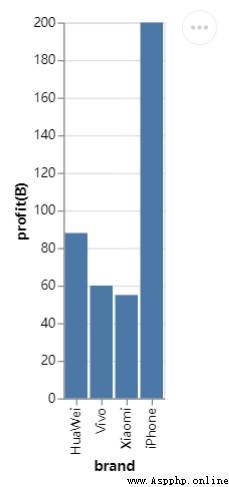
從整個的語法結構來看,首先使用alt.Chart()指定使用的數據集,然後使用實例方法mark_*()繪圖圖表的樣式,最後指定X軸和Y軸所代表的數據,可能大家會感到好奇,當中的N以及Q分別代表的是什麼,這個是變量類型的縮寫形式,換句話說,Altair模塊需要了解繪制圖形所涉及的變量類型,只有這樣,繪制的圖形才是我們期望的效果。
其中的N代表的是名義型的變量(Nominal),例如手機的品牌都是一個個專有名詞,而Q代表的是數值型變量(Quantitative),可以分為離散型數據(discrete)和連續型數據(continuous),除此之外還有時間序列型數據,縮寫是T以及次序型變量(O),例如在網購過程當中的對商家的評級有1-5個星級。
最後的圖表的保存,我們可以直接調用save()方法來保存,將對象保存成HTML文件,代碼如下
chart.save("chart.html")也可以保存成JSON文件,從代碼上來看十分的相類似
chart.save("chart.json")當然我們也能夠保存成圖片格式的文件,如下圖所示
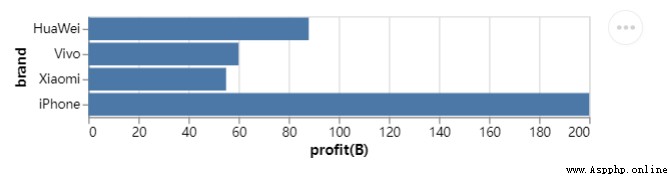
我們在上面的基礎之上,進一步的衍生和拓展,例如我們想要繪制一張水平方向的條形圖,X軸和Y軸的數據互換,代碼如下
chart = alt.Chart(df).mark_bar().encode(x="profit(B):Q", y="brand:N")
chart.save("chart1.html")output
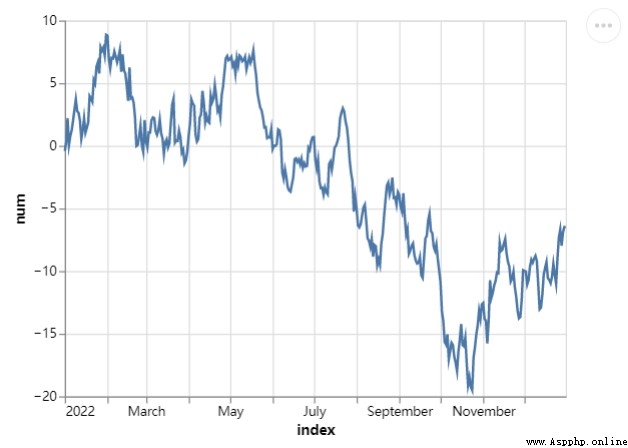
同時我們也來嘗試繪制一張折線圖,調用的是mark_line()方法代碼如下
## 創建一組新的數據,以日期為行索引值
np.random.seed(29)
value = np.random.randn(365)
data = np.cumsum(value)
date = pd.date_range(start="20220101", end="20221231")
df = pd.DataFrame({"num": data}, index=date)
line_chart = alt.Chart(df.reset_index()).mark_line().encode(x="index:T", y="num:Q")
line_chart.save("chart2.html")output
我們還可以來繪制一張甘特圖,通常在項目管理上面用到的比較多,X軸添加的是時間日期,而Y軸上表示的則是項目的進展,代碼如下
project = [{"project": "Proj1", "start_time": "2022-01-16", "end_time": "2022-03-20"},
{"project": "Proj2", "start_time": "2022-04-12", "end_time": "2022-11-20"},
......
]
df = alt.Data(values=project)
chart = alt.Chart(df).mark_bar().encode(
alt.X("start_time:T",
axis=alt.Axis(format="%x",
formatType="time",
tickCount=3),
scale=alt.Scale(domain=[alt.DateTime(year=2022, month=1, date=1),
alt.DateTime(year=2022, month=12, date=1)])),
alt.X2("end_time:T"),
alt.Y("project:N", axis=alt.Axis(labelAlign="left",
labelFontSize=15,
labelOffset=0,
labelPadding=50)),
color=alt.Color("project:N", legend=alt.Legend(labelFontSize=12,
symbolOpacity=0.7,
titleFontSize=15)))
chart.save("chart_gantt.html")output
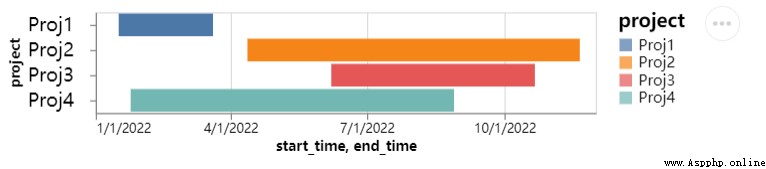
從上圖中我們看到團隊當中正在做的幾個項目,每個項目的進展程度不同,當然了,不同項目的時間跨度也不盡相同,表現在圖表上面的話就顯得十分的直觀了。
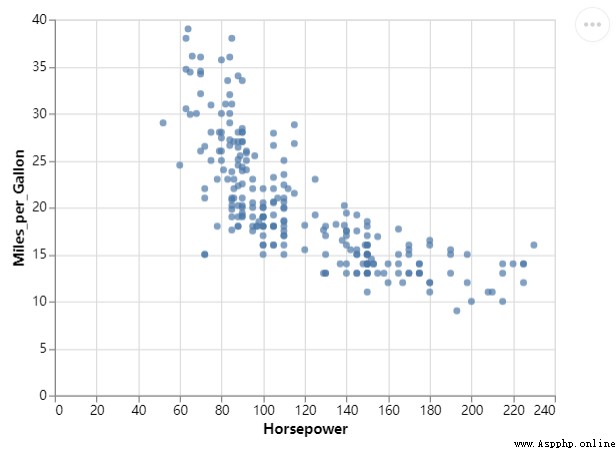
緊接著,我們再來繪制散點圖,調用的是mark_circle()方法,代碼如下
df = data.cars()
## 篩選出地區是“USA”也就是美國的乘用車數據
df_1 = alt.Chart(df).transform_filter(
alt.datum.Origin == "USA"
)
df = data.cars()
df_1 = alt.Chart(df).transform_filter(
alt.datum.Origin == "USA"
)
chart = df_1.mark_circle().encode(
alt.X("Horsepower:Q"),
alt.Y("Miles_per_Gallon:Q")
)
chart.save("chart_dots.html")output
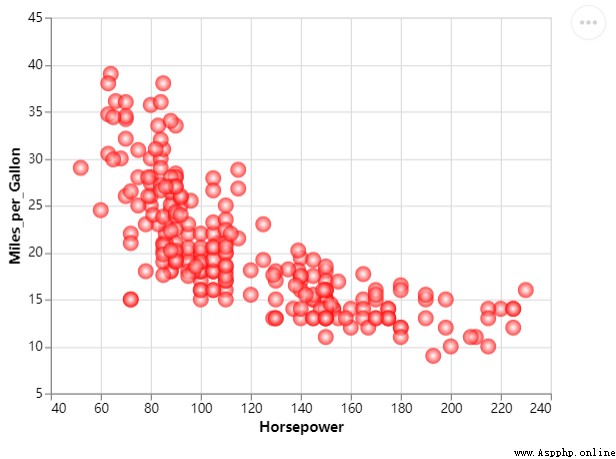
當然我們可以將其進一步的優化,讓圖表顯得更加美觀一些,添加一些顏色上去,代碼如下
chart = df_1.mark_circle(color=alt.RadialGradient("radial",[alt.GradientStop("white", 0.0),
alt.GradientStop("red", 1.0)]),
size=160).encode(
alt.X("Horsepower:Q", scale=alt.Scale(zero=False,padding=20)),
alt.Y("Miles_per_Gallon:Q", scale=alt.Scale(zero=False,padding=20))
)output
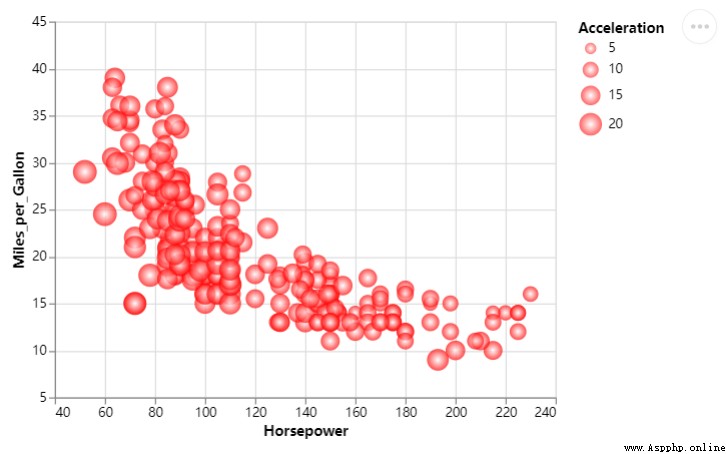
我們更改散點的大小,不同散點的大小代表著不同的值,代碼如下
chart = df_1.mark_circle(color=alt.RadialGradient("radial",[alt.GradientStop("white", 0.0),
alt.GradientStop("red", 1.0)]),
size=160).encode(
alt.X("Horsepower:Q", scale=alt.Scale(zero=False, padding=20)),
alt.Y("Miles_per_Gallon:Q", scale=alt.Scale(zero=False, padding=20)),
size="Acceleration:Q"
)output
NO.1
往期推薦
Historical articles
分享 5 大常用的特征選擇方法,機器學習入門必看!!!
【硬核原創】盤點Python爬蟲中的常見加密算法,建議收藏!!
用Python當中Plotly.Express模塊繪制幾張圖表,真的被驚艷到了!!
【硬核干貨】Pandas模塊中的數據類型轉換
分享、收藏、點贊、在看安排一下?