我們在通過pandas讀取數據的時候,可以選擇的讀取方式有很多種,這裡提幾點技巧。
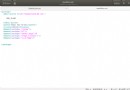
import pandas as pd
df = pd.read_csv('../data/XXX.csv',sep='\t',nrows = 100)
1.1 在設置路徑的時候,注意使用的斜槓方向,同時推薦一種寫法如下
df = pd.read_csv(r'C:\Users\12810\Desktop\temp\XXX.csv',sep='\t',nrows = 100) # 前面一個正則‘r’,不用修改斜槓方向
1.2 設置一個只讀取100個樣本,對於初步寫代碼的時候加速運行有很大的幫助。
df['new_col'] = XX # 加列的數據
df.apply(lambda x: x.split(','))
# 更多zip()、map()、lambda()連用請參照:
# https://blog.csdn.net/HG0724/article/details/117374802
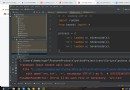
按照習慣,有時候單個獨立下劃線是用作一個名字,來表示某個變量是臨時的或無關緊要的。·
for _ in range(10):
print('我是:',_)
我是: 0
我是: 1
我是: 2
我是: 3
我是: 4
我是: 5
我是: 6
我是: 7
我是: 8
我是: 9
df['label'].value_counts().plot(kind='bar')
用於在數據分析中,找出某一列的數據中,元素的個數是多少,並可視化,很實用。
from collections import Counter # 一個計數器模塊
參考:https://blog.csdn.net/ch_improve/article/details/89388389
# 統計字符個數
str_1 = 'wdqdqwdqwqwd11dq2wd'
count_result = Counter(str_1) #
print(count_result)
Counter({'d': 6, 'w': 5, 'q': 5, '1': 2, '2': 1})
count_result.most_common(3)
[('d', 6), ('w', 5), ('q', 5)]