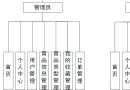
相關鏈接
可變序列:可以對執行序列進行增、刪、改操作,對象地址不發生改變。
① 列表list -> [v1,v2,…]、② 集合set -> {k1,k2,…}、③ 字典dict -> {k1:v1,…}
不可變序列:沒有增、刪、改的操作。由於其不可變特性,在多線程場景下,不需要加鎖。
① 元組tuple -> (v1,v2,…) 、② 字符串str -> ‘’
""" @author GroupiesM @date 2022/6/22 16:11 @introduction 可變序列:列表list、字典dict、集合set 可以對執行序列進行增、刪、改操作,對象地址不發生改變 不可變序列:元組tuple、字符串str 沒有增、刪、改的操作 """
'''可變序列 列表list、字典dict、集合set'''
lst = [10, 20, 45]
lst.append(300)
print(lst) # [10, 20, 45, 300]
'''不可變序列 元組tuple、字符串str'''
t = ('python', 5)
print(t) # ('python', 5)
""" @author GroupiesM @date 2022/4/29 09:25 @introduction 不可變序列(元組、字符串)在多個線程場景下,同時操作同一對象時不需要加鎖 注意事項: 元組中存儲的是對象的引用 a) 如果元組中對象本身不可變對象,即指向的內存地址不可變 b) 如果元組中的對象是非基本類型,可以修改其中的數據 """
t = (10, [20, 30], 9)
print(t) # (10, [20, 30], 9)
'''元組中的元素是引用類型時,可以修改引用類型的數據'''
t[1].remove(30) # (10, [20], 9)
print(t) # (10, [20], 9)
'''不可以修改元素的內存地址'''
t[1] = [50]
print(t) # TypeError: 'tuple' object does not support item assignment
P.S:
1.不可變序列在內存中是不會改變的
2.如果對不可變序列做出改變,會將該序列存儲在新的地址空間中,而原來的序列因為垃圾回收機制,會被回收。
3.可變序列發生改變時,是不會改變地址的,而是改變內存中的值,或者是擴展內存空間。
4.字典是一個可變序列,但是字典的鍵是不可變的,而值是可變的。因為字典結構的原理是偽隨機探測的散列表,它的查找方式是將鍵通過哈希函數,找到值的內存地址。所以哈希後的值一般是唯一的或是沖突比較小的。如果改變鍵的值,name哈希後的值就會發生變化,導致找不到原來的值,所以鍵的值是不可變的。鍵哈希後指向的是內存中的地址,內存中的數據發生變化不影響字典的查找。
""" @author GroupiesM @date 2022/4/28 17:13 @introduction <class 'tuple'> 列表:list = ['hello', 'world', 100] 字典:dict = {'name': '張三', 'age': 100} 元組:tuple = ('python','hello',90) 集合: set = {'python', 'hello', 90} 字符串: str = 'python' """
t = ('python', 'hello', 90)
print(type(t)) # <class 'tuple'>
print(t) # ('python', 'hello', 90)
""" @author GroupiesM @date 2022/4/28 17:55 @introduction 元組創建方式: 方式一:使用小括號(),元素之間英文逗號分隔;只有一個元素時也要加逗號,否則數據類型為基本數據類型 tup = ('python',) tup = (1,3,5) 方式二:內置函數 tuple() 類型轉換 tuple(('hello','php')) # list -> tuple tuple({'name': '張三', 'age': 100}) # 字典 -> tuple tuple(['hello','php']) # 元組 -> tuple tuple({'python', 'hello', 90}) # 集合 -> tuple tuple('hello') # 字符串->tuple """
'''方式一'''
lst = ['hello', 'python']
print(lst) # ['hello', 'python']
'''方式二'''
'''1.list->tuple'''
lst1 = tuple(('hello', 'php')) # list -> tuple
print('lst1', lst1) # ('hello', 'php')
'''2.字典->tuple時,自動取字典的key'''
lst2 = tuple({
'name': '張三', 'age': 100}) # 字典 -> tuple
print('lst2', lst2) # ('name', 'age')
'''3.元組->tuple'''
lst3 = tuple(['hello', 'php']) # 元組 -> tuple
print('lst3', lst3) # ('hello', 'php')
'''4.集合->tuple'''
lst4 = tuple({
'python', 'hello', 90}) # 集合 -> tuple
print('lst4', lst4) # ('python', 'hello', 90)
'''5.字符串->tuple'''
lst5 = tuple('hello') # 字符串->tuple
print('lst5', lst5) # ('h', 'e', 'l', 'l', 'o')
""" @author GroupiesM @date 2022/4/29 15:04 @introduction 使用for-in遍歷: 元組是可迭代對象 t = ('Python','hello',90) for i in t: print(i) """
t = ('Python', 'hello', 90)
for i in t:
print(i, end="\t") # Python hello 90
print()
for i in range(0, len(t)):
print(t[i], end="\t") # Python hello 90
""" @author GroupiesM @date 2022/6/27 16:57 @introduction """
1.查詢的方法
index(): 查找子串substr第一次出現的位置,如果查找的子串不存在時,則拋出ValueError
rindex():查找子串substr最後一次出現的位置,如果查找的子串不存在時,則拋出ValueError
find():查找子串substr第一次出現的位置,如果查找的子串不存在時,則返回-1
rfind():查找子串substr最後一次出現的位置,如果查找的子串不存在時,則返回-1
2.大小寫轉換
upper(): 把字符串中所有的字符都轉成大寫字母
lower(): 把字符串中所有的字符都轉成小寫字母
swapcase(): 把字符串中所有大寫字母轉成小寫字母,把所有小寫字母轉成大寫字母
capitalsize(): 整個字符串首字母大寫,其余字母小寫
title(): 每個單詞首字母大寫,其余字母小寫
3.內容對齊
center(): 居中對齊,第1個參數指定寬度,第2個參數指定填充符,第2個參數是可選的,默認是空格,如果設置寬度小於實際寬度則返回原字符串
ljust(): 左對齊,第1個參數指定寬度,第2個參數指定填充符,第2個參數是可選的,默認是空格,如果設置寬度小於實際寬度則返回原字符串
rjust(): 右對齊,第1個參數指定寬度,第2個參數指定填充符,第2個參數是可選的,默認是空格,如果設置寬度小於實際寬度則返回原字符串
zfill(): 右對齊,左邊用0填充,第1個參數指定寬度,如果設置寬度小於實際寬度則返回原字符串
4.字符串的分割
split(self,sep,maxsplit):從字符串左邊開始分割,返回一個列表
self:字符串本身
sep:指定分隔符,默認為空格
maxsplit:指定最大分割次數,分割指定次數後,剩余字符串作為一個整體不再分割
rsplit():從字符串右邊開始分割,返回一個列表(參數相同)
5.字符串判斷
isidentifier(): 合法的變量名(可用作接收變量的變量名)
isspace(): 全部由空字符串組成(回車、換行、水平制表符)
isalpha(): 全部由字母組成
isdecimal(): 全部由十進制的數字組成
isnumeric(): 全部由數字組成(中文簡體、繁體,符號,羅馬數字)
isalnum(): 全部由字母和數字組成
6.字符串替換
replace(old,new):
replace(old,new,count):
self: 默認字符串本身
1.old: 替換前的字符串
2.new: 替換後的字符串
3.count: 最大替換次數,(可省略參數)
7.字符串合並
join(): 將列表或元組中的字符串合並成一個字符串,列表或元組的元素必須都是字符串
8.字符串比較
運算符:>,>=,<,<=,==,!=
比較規則:首先比較兩個字符串中的第一個字符,如果相等則繼續比較下一個字符,
依次比較下去,直到兩個字符串中的字符不相等時,其比較結果就是兩個字符串的
比較結果,兩個字符串中所有的後續字符將不再被比較
比較原理:
兩個字符進行比較,比較的是其 ASCII碼值
通過內置函數ord(字符),可以獲取字符對應的 ASCII碼值(數字)
通過內置函數chr(數字),可以獲取數字對應的 字符
9.字符格式化
%-formatting、format、f-String
10.字符串編解碼
encode(String encoding):編碼,將字符串轉換為二進制數據(bytes)
decode(String encoding):解碼,將bytes類型的數據轉換為字符串類型
""" @author GroupiesM @date 2022/5/9 14:03 @introduction <class 'str'> 列表:list = ['hello', 'world', 100] 字典:dict = {'name': '張三', 'age': 100} 元組:tuple = ('python','hello',90) 集合: set = {'python', 'hello', 90} 字符串: str = 'python' """
''' 字符串定義:有三種方式,單引號、雙引號、三引號 '''
str1 = 'python'
str2 = "python"
str3 = ''''python'''
print(type(str1)) # <class 'tuple'>
print(str1) # ('python', 'hello', 90)
""" @author GroupiesM @date 2022/5/9 14:14 @introduction 一、駐留機制 1)python中字符串是基本類型,是不可變字符序列 2)什麼是字符串駐留機制 【相同字符串的內存地址也相等】 僅保存一份相同且不可變字符串的方法,不同的值被存放在字符串的駐留池中, Python的駐留機制對相同的字符串只保留一份拷貝,後續創建相同字符串時, 不會開辟新空間,而是把該字符串的地址賦值給新建的變量 二、注意事項 1、字符串的駐留條件 僅包含字母、數字、下劃線的字符串,python會啟用駐留機制, 因為Python解釋器僅對看起來像python標識符的字符串使用intern()方法,而python標識符正是由字母、數字和下劃線組成。 2、字符串的連接 字符串數據類型,是不可變類型,我們都知道,如果我們有了一個字符串,想要修改它,是不可以的,則必須新建一個對象, 因此不推薦使用“+”連接字符串,而推薦大家采用join()方法 3、整數駐留 python會針對整數范圍是[-5, 256]的整數啟用駐留機制(python認為這些數字時常用數字,放在緩存中節省開銷) 4、在pycharm和黑窗口(iterm)中測試結果不同,具體原因不詳 1)teminal:不觸發字符串駐留機制 2)pycharm:觸發字符串駐留機制 P.S 比較運算符: == -> value的比較 is,is not 內存地址比較 """
str1 = "abc"
str2 = "abc" # 相同字符串的內存地址也相等 -> str1與str2內存地址相等
str3 = "".join(['ab', 'c'])
print(str1, type(str1), id(str1)) # abc <class 'str'> 4378617712
print(str2, type(str2), id(str2)) # abc <class 'str'> 4378617712
# 結論: str1、str2的地址相等
print(str3, type(str3), id(str3)) # abc <class 'str'> 4381017264
""" 在不同場景測試包含[\w\d_]以外的字符時,python字符串駐留機制(python3.8.9) 1)terminal:不觸發字符串駐留機制 2)pycharm:觸發字符串駐留機制 """
"""1) terminal: [email protected] ~ % python3 Python 3.8.9 (default, Feb 18 2022, 07:45:33) [Clang 13.1.6 (clang-1316.0.21.2)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> str4='abc%' >>> str5='abc%' >>> str4==str5 True >>> str4 is str5 False >>> """
"""2) pycharm:"""
str4 = 'abc%'
str5 = 'abc%'
print(str4 == str5) # True 比較value
print(id(str4)) # 4300391152
print(id(str5)) # 4300391152
print(str4 is str5) # True 比較內存地址
""" @author GroupiesM @date 2022/5/23 17:01 @introduction 查詢方法: index(): 查找子串substr第一次出現的位置,如果查找的子串不存在時,則拋出ValueError rindex():查找子串substr最後一次出現的位置,如果查找的子串不存在時,則拋出ValueError find():查找子串substr第一次出現的位置,如果查找的子串不存在時,則返回-1 rfind():查找子串substr最後一次出現的位置,如果查找的子串不存在時,則返回-1 """
s = 'hello,hello'
print(s.index('lo')) # 3
print(s.rindex('lo')) # 9
print(s.find('lo')) # 3
print(s.rfind('lo')) # 9
# print(s.index('k')) #報錯 如果查找的子串不存在時,則拋出ValueError
# print(s.rindex('k')) #報錯 如果查找的子串不存在時,則拋出ValueError
print(s.find('k')) # -1
print(s.rfind('k')) # -1
""" @author GroupiesM @date 2022/6/20 09:34 @introduction 大小寫轉換: upper(): 把字符串中所有的字符都轉成大寫字母 lower(): 把字符串中所有的字符都轉成小寫字母 swapcase(): 把字符串中所有大寫字母轉成小寫字母,把所有小寫字母轉成大寫字母 capitalsize(): 整個字符串首字母大寫,其余字母小寫 title(): 每個單詞首字母大寫,其余字母小寫 """
s = 'hEllo WoRld'
print(s, id(s)) # hEllo WoRld 4333433968
print(s.upper(), id(s.upper())) # HELLO WORLD 4333137520
print(s.lower(), id(s.lower())) # hello world 4333137520
print(s.swapcase(), id(s.swapcase())) # HeLLO wOrLD 4333137520
print(s.capitalize(), id(s.capitalize())) # Hello world 4333137520
print(s.title(), id(s.title())) # Hello World 4333137520
""" @author GroupiesM @date 2022/6/20 10:33 @introduction 內容對齊: center(): 居中對齊,第1個參數指定寬度,第2個參數指定填充符,第2個參數是可選的,默認是空格,如果設置寬度小於實際寬度則返回原字符串 ljust(): 左對齊,第1個參數指定寬度,第2個參數指定填充符,第2個參數是可選的,默認是空格,如果設置寬度小於實際寬度則返回原字符串 rjust(): 右對齊,第1個參數指定寬度,第2個參數指定填充符,第2個參數是可選的,默認是空格,如果設置寬度小於實際寬度則返回原字符串 zfill(): 右對齊,左邊用0填充,第1個參數指定寬度,如果設置寬度小於實際寬度則返回原字符串 """
s = 'hello world'
'''指定填充'''
print(s.center(20, '*')) # ****hello world*****
print(s.ljust(20, '&')) # hello world&&&&&&&&&
print(s.rjust(20, '^')) # ^^^^^^^^^hello world
print(s.zfill(20)) # 000000000hello world
'''不指定填充'''
print(s.center(20)) # hello world
print(s.ljust(20)) #hello world
print(s.rjust(20)) # hello world
print(s.zfill(20)) # 000000000hello world
'''指定寬度 < 字符串長度'''
print(s.center(5)) # hello world
print(s.ljust(4)) # hello world
print(s.rjust(3)) # hello world
print(s.zfill(2)) # hello world
""" @author GroupiesM @date 2022/6/20 10:44 @introduction split()-分割: split(self,sep,maxsplit):從字符串左邊開始分割,返回一個列表 self:字符串本身 sep:指定分隔符,默認為空格 maxsplit:指定最大分割次數,分割指定次數後,剩余字符串作為一個整體不再分割 rsplit():從字符串右邊開始分割,返回一個列表(參數相同) """
s = 'a1b1c d1e1f g h'
print(s.split()) # ['a1b1c', 'd1e1f', 'g', 'h']
print(s.split(sep='1')) # ['a', 'b', 'c d', 'e1f']
print(s.split(maxsplit=3)) # ['a', 'b', 'c d', 'e', 'f g h']
print(s.split(sep='1', maxsplit=3)) # ['a', 'b', 'c d', 'e1f g h']
print('----')
print(s.rsplit()) # ['a1b1c', 'd1e1f', 'g', 'h']
print(s.rsplit(sep='1')) # ['a', 'b', 'c d', 'e', 'f g h']
print(s.rsplit(maxsplit=3)) # ['a1b1c', 'd1e1f', 'g', 'h']
print(s.rsplit(sep='1', maxsplit=3)) # ['a1b', 'c d', 'e', 'f g h']
""" @author GroupiesM @date 2022/6/20 11:21 @introduction 判斷: isidentifier(): 合法的變量名(可用作接收變量的變量名) isspace(): 全部由空字符串組成(回車、換行、水平制表符) isalpha(): 全部由字母組成 isdecimal(): 全部由十進制的數字組成 isnumeric(): 全部由數字組成(中文簡體、繁體,符號,羅馬數字) isalnum(): 全部由字母和數字組成 """
print('---isidentifier() 合法的變量名(可用作接收變量的變量名)---')
print('if'.isidentifier()) # True
print('_b'.isidentifier()) # True
print('張三'.isidentifier()) # True
print('8a'.isidentifier()) # False
print(''.isidentifier()) # False
print('---isspace() 全部由空字符串組成(回車、換行、水平制表符)---')
print(' \r\t\n'.isspace()) # True
print(' \r\t\n0'.isspace()) # False
print('---isalpha() 全部由字母組成---')
print('abc'.isalpha()) # True
print('張三'.isalpha()) # True
print('張三1'.isalpha()) # False
print('---isdecimal(): 全部由十進制的數字組成---')
print('123'.isdecimal()) # True
print('12三'.isdecimal()) # True
print('123.4'.isdecimal()) # False
print('123 '.isdecimal()) # False
print('---isnumeric(): 全部由數字組成(中文簡體、繁體,符號,羅馬數字)---')
print('12'.isnumeric()) # True
print('12②貳Ⅱ'.isnumeric()) # True
print('1two'.isnumeric()) # False
print('---isalnum(): 全部由字母和數字組成---')
print('張三8'.isalnum()) # True
print('張三8 '.isalnum()) # False
""" @author GroupiesM @date 2022/6/20 12:04 @introduction 替換: replace(String old,String new): replace(String old,String new,Integer count): self: 默認字符串本身 1.old: 替換前的字符串 2.new: 替換後的字符串 3.count: 最大替換次數,(可省略參數) """
s = '12 12 12'
print(s.replace(' ', '\r\n', 1))
''' 12 12 12 '''
print('---')
print(s.replace(' ', '\r\n'))
''' 12 12 12 '''
""" @author GroupiesM @date 2022/6/20 12:12 @introduction 合並: join(): 將列表或元組中的字符串合並成一個字符串,列表或元組的元素必須都是字符串 """
lst =['1 ','2 ','345']
print(''.join(lst)) # 1 2 345
lst =['1 ','2 ',345]
print(''.join(lst)) # TypeError: sequence item 2: expected str instance, int found
""" @author GroupiesM @date 2022/6/21 16:57 @introduction 比較: 運算符:>,>=,<,<=,==,!= 比較規則:首先比較兩個字符串中的第一個字符,如果相等則繼續比較下一個字符, 依次比較下去,直到兩個字符串中的字符不相等時,其比較結果就是兩個字符串的 比較結果,兩個字符串中所有的後續字符將不再被比較 比較原理: 兩個字符進行比較,比較的是其 ASCII碼值 通過內置函數ord(字符),可以獲取字符對應的 ASCII碼值(數字) 通過內置函數chr(數字),可以獲取數字對應的 字符 """
'''>'''
print("apple" > "app") # True
print('a' > '張') # False
print(ord('a')) # 97
print(ord('張')) # 24352
print(chr(97)) # a
''' ==與is的區別 ==比較的是value is比較的是id是否相等(內存地址) '''
a = 'ab'
b = "".join(['a', 'b'])
'''a與b的 值、內存地址'''
print(a, id(a)) # ab 4375883376
print(b, id(b)) # ab 4377252400
print(a == b) # True :a與b值相等
print(a is b) # False :a與b內存地址不相等
""" @author GroupiesM @date 2022/6/22 11:28 @introduction 切片: 1.字符串是不可變類型,不具備增、刪、改等操作 2.字符串是不可變類型,切片操作將產生新的對象 假設有字符串 str = 'hello,python',已知str長度為11 0 1 2 3 4 5 6 7 8 9 10 11 [正向索引] h e l l o , p y t h o n -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 [反向索引] 了解即可 切片語法1:newStr = str[起始(x):結束(y):步長(s)] 其中x,y為任意整數,表示索引位置 其中s為任意整數,表示步長(每次取字符間隔幾個位置) 1. 起始(x)可以省略不寫,不寫則取默認值 0;例如 str[:5] <=> str[0:5] 2. 結束(y)可以省略不寫,不寫則取默認值 字符串結尾位置; 例如str[6:] <=> str[6:11] 3. 步長(s)可以省略不寫,不寫則取默認值 1; 例如str[:5:] <=> str[:5:1] 4. 若 起始(x)>結束(y),生成新的字符串為空字符串 '' 5. 若 0 < 起始(x) < 結束(y),則按照 正向索引 進行切片操作 6. 若 起始(x) < 結束(y) < 0,則按照 反向索引 進行切片操作。基本沒有使用場景,了解即可 7. 若 s<0,則字符串反向切片 """
str = 'hello,python'
s1 = str[:5] # str[:5] <=> str[0:5] 兩種寫法等價
print('s1', s1) # hello
s2 = str[6:] # str[6:] <=> str[6:11] 兩種寫法等價
print('s2', s2) # python
s3 = str[:] # str[:] <=> str[0:11] 兩種寫法等價
print('s3', s3) # hello,python
s4 = str[0:5:] # str[0:5:] <=> str[0:5:1] 兩種寫法等價
print('s4', s4) # hello
s5 = str[-5:-1]
print('s5', s5) # s5 ytho
s6 = str[0:5:1]
print('s6', s6) # hlo
s7 = str[-15:-1] # s<0,反向切片
print('s7', s7) # nohtyp,olleh
""" @author GroupiesM @date 2022/6/27 16:48 @introduction 字符串編解碼: 目的:用於網絡中的數據傳輸(byte字節傳輸) encode(String encoding):編碼,將字符串轉換為二進制數據(bytes) decode(String encoding):解碼,將bytes類型的數據轉換為字符串類型 P.S 1.編碼方式:常見編碼方式有 GBK、UTF-8 2.亂碼最常見的原因就是編解碼不一致 """
s = '將bytes類型的數據轉換為字符串類型'
# 編碼 - b'\xbd\xabbytes\xc0\xe0\xd0\xcd\xb5\xc4\xca\xfd\xbe\xdd\xd7\xaa\xbb\xbb\xce\xaa\xd7\xd6\xb7\xfb\xb4\xae\xc0\xe0\xd0\xcd'
g_encode = s.encode('GBK')
g_encode = s.encode(encoding='GBK')
print(g_encode)
# 解碼 - 將bytes類型的數據轉換為字符串類型
g_decode = g_encode.decode('GBK')
g_decode = g_encode.decode(encoding='GBK')
print(g_decode)
22/06/28
M