in the capacity of Python people , Is a very contradictory thing .
Some experts think , In the age of big data , Everyone is swimming naked , Algorithms analyze people's preferences every day , Study how you prefer breaststroke 、 Freestyle or diving , Then decide whether to sell your swimsuit, swimming cap or diving bottle .
Python Human entanglement lies in , While swimming naked in big data , While analyzing other skinny swimmers ; While racking their brains to push the customer information to the target group , Hard on one side × Drop all kinds of pop-up ads 、 Patch ad 、 Open screen advertisement ……

A little faster and I went in
Python People are familiar with the framework of every advertising recommendation algorithm 、 Logic 、 tricks 、 Purpose , More than laymen can point out the design loopholes of advertising recommendations . But they are stopping their relatives 、 Lover 、 When a friend saw the advertisement for impulse consumption, he came across a sentence “ You know , As far as you know ”.

It seems that I don't know enough , Let's take a look at an example of advertising Recommendation Algorithm .
First , We have collected a large number of advertising data , Include App Information 、 advertising ID、 The media ID、 Material information 、 Title Text 、 Describe text and other available vector features .
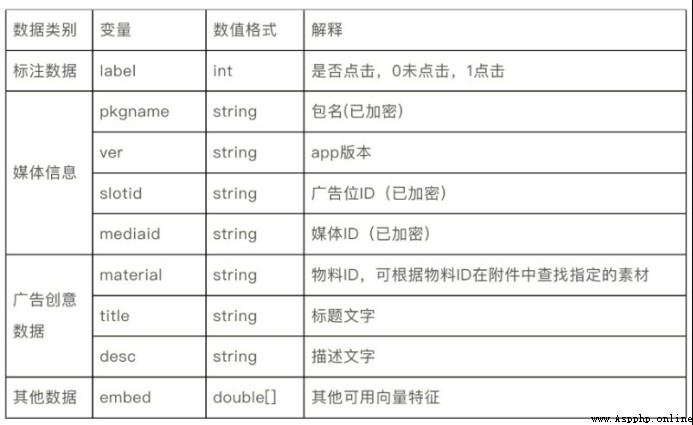
then , We found that the material information contains a lot of picture information , Store as text , So we need to deal with these information first .
It can be processed by image feature extraction, etc , For simplicity , Process in a unified way according to text information , First serialize the encoding , Progressive word ( Text ) Vector transformation .
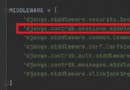
for col in ["pkgname", "ver", "slotid", "mediaid", "material"]:
lbl = LabelEncoder()
lbl.fit(train_df[col].tolist() + test_df[col].tolist())
train_df[col] = lbl.transform(train_df[col])
test_df[col] = lbl.transform(test_df[col])Here we use Torch Bag Embedding, Convert text to vector .
After data processing , We must sacrifice the classic reticular structure MLP 了 .
class MLP(nn.Module):
def __init__(self, category_dict, layers=[45 + 240, 32], dropout=False):
super().__init__()
print(category_dict)
self.category_dict = category_dict
self.embedding_dict = {
key: torch.nn.Embedding(
self.category_dict[key] + 1, int(np.log2(self.category_dict[key]))
).to(device)
for key in category_dict.keys()
}
self.fc_layers = torch.nn.ModuleList()
for _, (in_size, out_size) in enumerate(zip(layers[:-1], layers[1:])):
self.fc_layers.append(torch.nn.Linear(in_size, out_size).to(device))
self.output_layer = torch.nn.Linear(layers[-1], 1).to(device)
def forward(self, feed_dict, embed_dict):
embedding_feet = {
key: self.embedding_dict[key](feed_dict[key])
for key in self.category_dict.keys()
}
x = torch.cat(list(embedding_feet.values()), 1)
x = torch.cat([x, embed_dict], 1)
for idx, _ in enumerate(range(len(self.fc_layers))):
x = self.fc_layers[idx](x)
x = F.relu(x)
x = F.dropout(x)
logit = self.output_layer(x)
return logitTraining begins ~
This is a common idea in advertising recommendation , But as Python Human you , I must think this algorithm is a little crude .
Regarding this , I want to say ,“ As far as you know , You can go on ”.

Sign in
2022iFLYTEK A.I. The official website of the developer competition
A.I. Algorithm contest
“ Digital advertising from the creative perspective CTR Estimate the challenge ”
or Scan the qr code below , You can check the above data for free 、 Write your unique algorithm , Predict ad clicks based on training set data , Compete for the cash prize .
You don't know how ? You can't counselle now !

Of course , The code in the above case is also available
Scan the qr code below
Get questions Baseline
▼