在本文中,我們將介紹如何使用圖像相似性量度庫來比較圖像。根據庫的文檔,我們可以使用八種不同的評估指標來計算圖像之間的相似度。
幸運的是,所有可怕的數學運算已為我們實現,我們可以立即開始測量圖像相似度。我們只需要調用所選評估指標的名稱並傳遞兩個圖像作為參數即可。例如:
請注意,默認指標是psnr。
有兩種使用此軟件包的方法:您可以在終端中執行命令或編寫單獨的Python腳本。
如果要在兩個圖像之間進行快速評估,請在終端中運行以下命令:
(可選)添加— metric標志以指示要使用的評估指標。
在本文中,我選擇了三個評估指標:rmse,psnr和ssim。
首先,讓我們了解我們將要構建的程序:
讓我們使用pip或pip3安裝庫:
接下來,創建一個新的Python腳本文件並粘貼以下代碼:
上述代碼分析:
首先,我將為原始圖像創建一個文件夾。然後,我將比較圖像放置在數據集文件夾中。
這個紅蘋果將是我們原始的查詢圖像:
我們將其與其他水果進行比較:
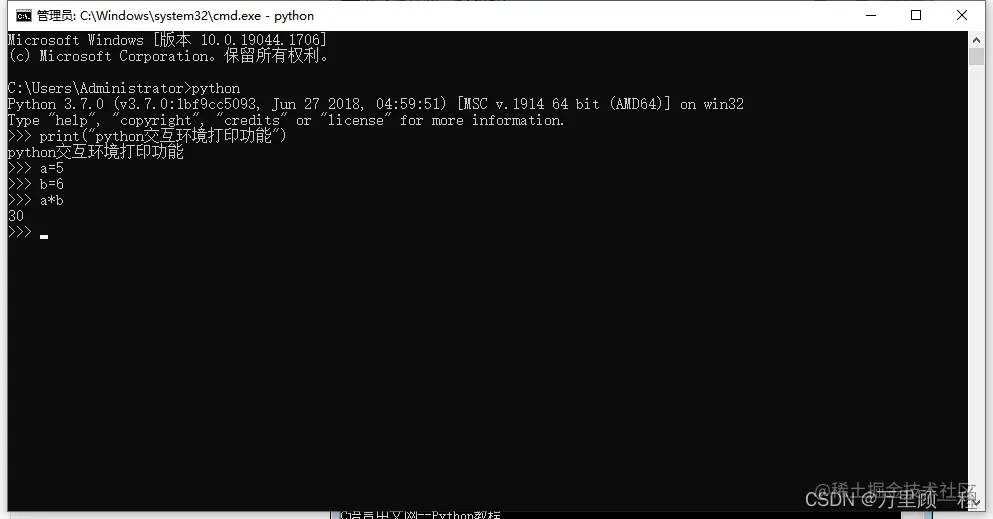
現在,讓我們運行Python程序,找出最匹配的一個:
$ python3 measure_similarity.py red_apple.jpg
輸出:
The difference between dataset/red_pear.jpg and the original image is :
0.8827639040117994
The difference between dataset/cherry.jpg and the original image is :
0.8542221298727691
The difference between dataset/green_apple.jpg and the original image is :
0.9379929447852137
The closest value: 0.9379929447852137
######################################################################
The difference between dataset/red_pear.jpg and the original image is :
0.018479494
The difference between dataset/cherry.jpg and the original image is :
0.022247538
The difference between dataset/green_apple.jpg and the original image is :
0.014238722
The closest value: 0.014238722
######################################################################
The difference between dataset/red_pear.jpg and the original image is :
55.925131298420894
The difference between dataset/cherry.jpg and the original image is :
55.43173546627284
The difference between dataset/green_apple.jpg and the original image is :
58.09926725713899
The closest value: 58.09926725713899
######################################################################
The most similar image accroding to SSIM: {
'dataset/green_apple.jpg': 0.9379929447852137}
The most similar image accroding to RMSE: {
'dataset/green_apple.jpg': 0.014238722}
The most similar image accroding to SRE: {
'dataset/green_apple.jpg': 58.09926725713899}
如您所見,青蘋果是贏家。如果查看每個結果,就會發現第二個最相似的圖像是紅梨。
現在,讓我們來看看當很難預測結果時會發生什麼。讓我們將紅色番茄的照片放在數據集文件夾中:
我要說的是,青蘋果和番茄看起來都像紅蘋果。讓我們根據數學來檢查結果:
為了使它更加令人興奮,讓我們嘗試比較更多不同的圖像。自從我喜歡繪畫以來,我為此實驗拍攝了自己的繪畫照片。
原始圖片:
圖像數據集:
我看到了兩張與小房子相似的照片,這些小房子與原始照片相似。
秋天風景和房子最匹配。
這些怎麼樣?
乍一看,結果令我有些驚訝。但是,當我仔細觀察時,與該女孩合影的照片具有深藍色背景,就像原始圖像一樣。北極光的繪畫在背景中具有相似的山脈。
如您所見,結果基於不同的評估指標而有所不同。
我們已經了解了如何使用不同的評估指標來衡量圖像相似度。圖像相似性度量庫為我們實現了這些方法。
哪種方法最好?
很難預測出准確的結果。度量根據不同方面比較圖像。這取決於您要如何比較圖像。
度量學習是一種直接基於距離度量的方法,旨在建立圖像之間的相似性或相異性。 另一方面,深度度量學習使用神經網絡從圖像中自動學習判別特征,然後計算度量。其目的在訓練可以將輸入嵌入到高維空間中的模型,以便訓練方案定義的“相似”輸入彼此靠近。 這些模型一旦訓練就可以為下游系統生成嵌入,在這些系統中這種相似性是有用的; 示例包括作為搜索的排名信號或作為另一個監督問題的預訓練嵌入模型的一種形式。