第一章 Python 入門
第二章 Python基本概念
第三章 序列
第四章 控制語句
第五章 函數
第六章 面向對象基礎
第七章 面向對象深入
第八章 異常機制
第九章 文件操作
在本章節, 主要介紹了文件操作相關的API方法使用
首先我們將會學習什麼是文件操作, 以及文件分類還有在IO操作時會用到的常用編碼介紹
然後我們學習了文件操作的流程, 創建->寫入->關閉
在然後我們學習了文件的拓展, 序列化模塊pickle, 文件操作模塊csv, 系統操作調用模塊os和os.path以及文件拷貝壓縮模塊shutil
一個完整的程序一般都包括數據的存儲和讀取;我們在前面寫的程序數據都沒有進行實際的存儲,因此python解釋器執行完數據就消失了
實際開發中,我們經常需要從外部存儲介質(硬盤、光盤、U盤等)讀取數據,或者將程序產生的數據存儲到文件中,實現“持久化”保存
按文件中數據組織形式,我們把文件分為文本文件和二進制文件兩大類:
文本文件
文本文件存儲的是普通“字符”文本,python默認為 unicode 字符集,可以使用記事本程序打開
二進制文件
二進制文件把數據內容用“字節”進行存儲,無法用記事本打開, 必須使用專用的軟件解碼.
常見的有:MP4視頻文件、MP3音頻文件、JPG圖片、doc文檔等等
在操作文本文件時,經常會操作中文,這時候就經常會碰到亂碼問題.
為了解決中文亂碼問題,需要學習下各個編碼之前的問題.
常用編碼之間的關系如下:
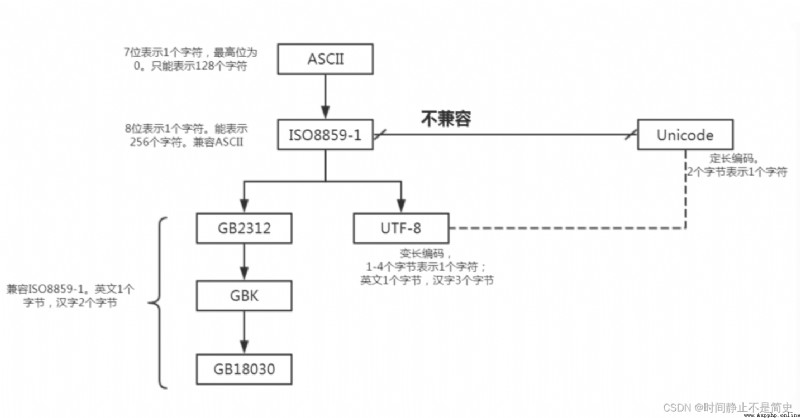
全稱為 American Standard Code for Information Interchange ,美國信息交換標准代碼,
這是世界上最早最通用的單字節編碼系統,主要用來顯示現代英語及其他西歐語言
注意事項:
2^7=128個字符,用7bit即可完全編碼,GBK即漢字內碼擴展規范,英文全稱Chinese Internal Code Specification.
GBK編碼標准兼容GB2312,共收錄漢字21003個、符號883個,並提供1894個造字碼位,簡、繁體字融於一庫。
GBK采用雙字節表示,總體編碼范圍為8140-FEFE,首字節在81-FE 之間,尾字節在40-FE 之間
Unicode 編碼設計成了固定兩個字節,所有的字符都用16位
2^16=65536表示,包括之前只占8位的英文字符等,所以會造成空間的浪費
Unicode 完全重新設計,不兼容 iso8859-1 ,也不兼容任何其他編碼
對於英文字母, unicode 也需要兩個字節來表示, 所以 unicode 不便於傳輸和存儲.
因此而產生了 UTF編碼 , UTF-8 全稱是( 8-bit UnicodeTransformation Format )
注意事項
open() 函數用於創建文件對象,基本語法格式如下:open(文件名[,打開方式])
注意:
如果只是文件名,代表在當前目錄下的文件. 文件名可以錄入全路徑,比如: D:\a\b.txt
可以使用原始字符串 r“d:\b.txt” 減少 \ 的輸入, 因此以上代碼可改寫成 f = open(r"d:\b.txt","w")
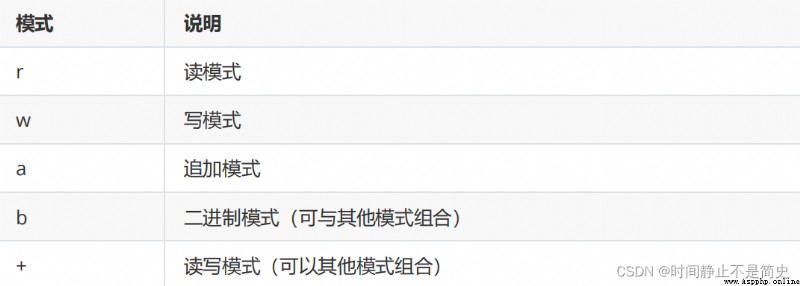
作為入參的打開方式如下(經常會用!!!)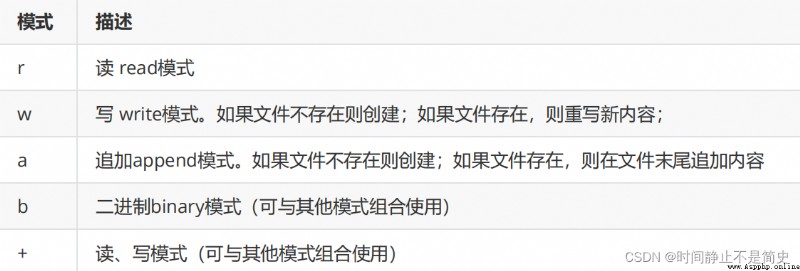
文本文件對象和二進制文件對象的創建
如果是二進制模式 b ,則創建的是二進制文件對象,處理的基本單元是“字節”
如果沒有增加模式 b ,則默認創建的是文本文件對象,處理的基本單元是“字符”
文本文件的寫入一般就是三個步驟:
實操代碼
# 1.使用open()方式
f = open(r"d:\a.txt", "a")
s = "TimePause\n時間靜止\n"
f.write(s)
f.close()
結果展示

windows 操作系統默認的編碼是 GBK , Linux 操作系統默認的編碼是 UTF- 8 .
當我們用 open() 時,調用的是操作系統相關api來打開的文件,並且默認的編碼是 GBK
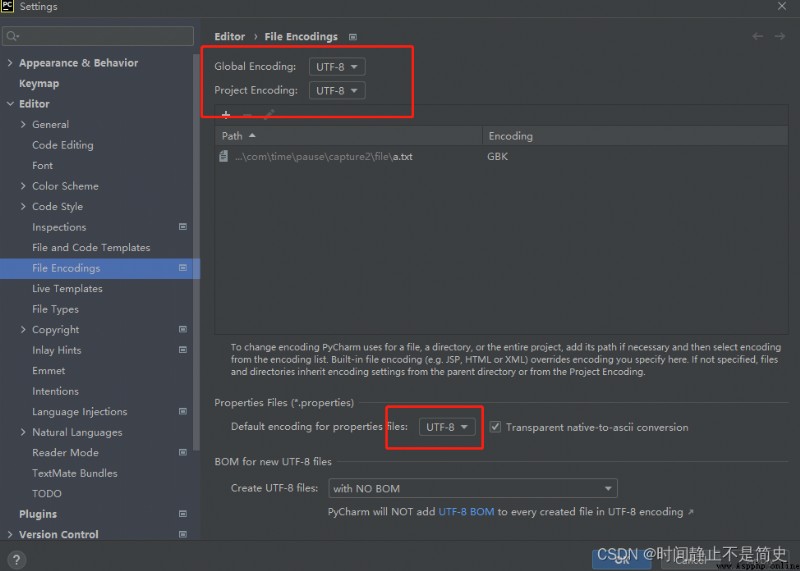
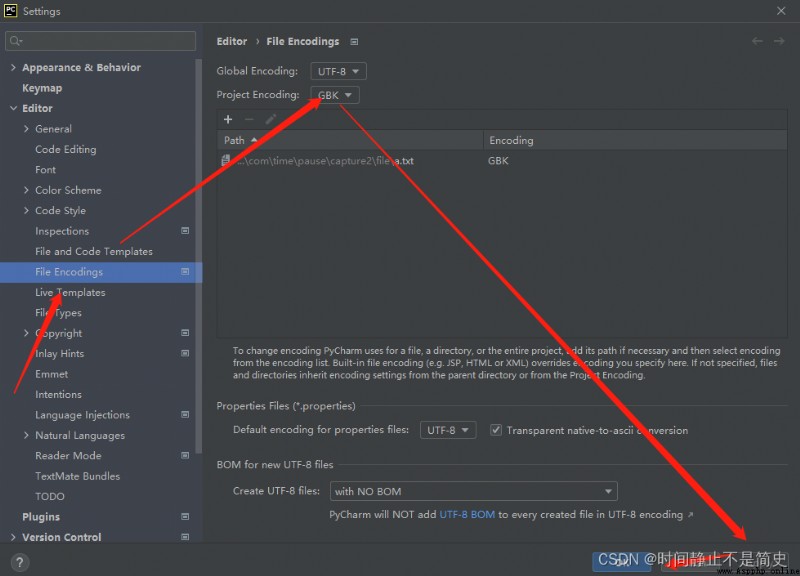
但是由於我們通常習慣將所有代碼編碼都設置成 UTF- 8 ., 因此在打開時會出現亂碼問題, 如下圖所示

解決方案:
按照上圖提示, 將文本編碼設置成 GBK格式讀取即可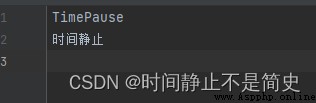
注意:
我們還可以通過指定編碼來解決中文亂碼問題. 因為我們將pycharm文本讀寫編碼都設置成 utf-8,
因此只要我們在文件寫入的時候規定編碼為 utf-8(默認gbk), 那麼我們在讀取時就不會出現亂碼. 如下代碼
實操代碼
# 【示例】通過指定文件編碼解決中文亂碼問題
f = open(r"d:\bb.txt", "w", encoding="utf-8")
f.write("一個有溫情的小站\n時間靜止不是簡史")
f.close()
問題描述
我們一般習慣把pycharm所有字符編碼設置成utf-8時. 在我們進行網絡請求時, 有時候會返回亂碼問題, 如下圖
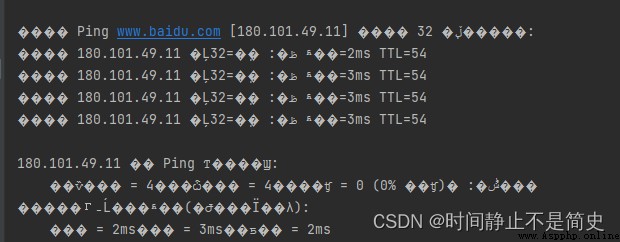
問題分析
因為我們在 pycharm 設置所有字符編碼均為 UTF-8, 但是通過網絡請求得到GBK格式的文本, 然後我們仍以 UTF-8 編碼去解碼就會出現亂碼
解決方案
可以將項目編碼設置成GBK格式即可; 也可以通過文本操作代碼對得到的數據進行GBK格式讀取
亦或者在寫入時, 直接將編碼聲明為UTF-8

write(a) :把字符串 a 寫入到文件中writelines(b) :把字符串列表寫入文件中,不添加換行符實操代碼
# 【操作】添加字符串列表數據到文件中
f = open(r"d:\bb.txt", 'w', encoding="utf-8")
s = ["什麼鬼\n"] * 3 # 通過 \n實現手動換行
f.writelines(s)
f.close()
由於文件底層是由操作系統控制,所以我們打開的文件對象必須顯式調用 close() 方法關閉文件對象.
當調用 close() 方法時,首先會把緩沖區數據寫入文件(也可以直接調用 flush() 方法),再關閉文件,釋放文件對象
注意:
close()一般結合異常機制的 finally 一起使用實操代碼
# 【操作】結合異常機制的 finally ,確保關閉文件對象
# "a" 設置打開方式為追加模式
try:
f = open(r"d:\c.txt", "a")
s = "來自深淵"
f.write(s)
except BaseException as e:
print(e)
finally:
f.close()
with關鍵字 (上下文管理器)可以自動管理上下文資源,不論什麼原因跳出 with塊 ,都能確保文件正確的關閉,
並且可以在代碼塊執行完畢後自動還原進入該代碼塊時的現場
實操代碼
# 【操作】使用 with 管理文件寫入操作
s = ["齊格飛"] * 3
with open(r"d:\cc.txt", "w") as f:
f.writelines(s)
文件讀取的步驟:
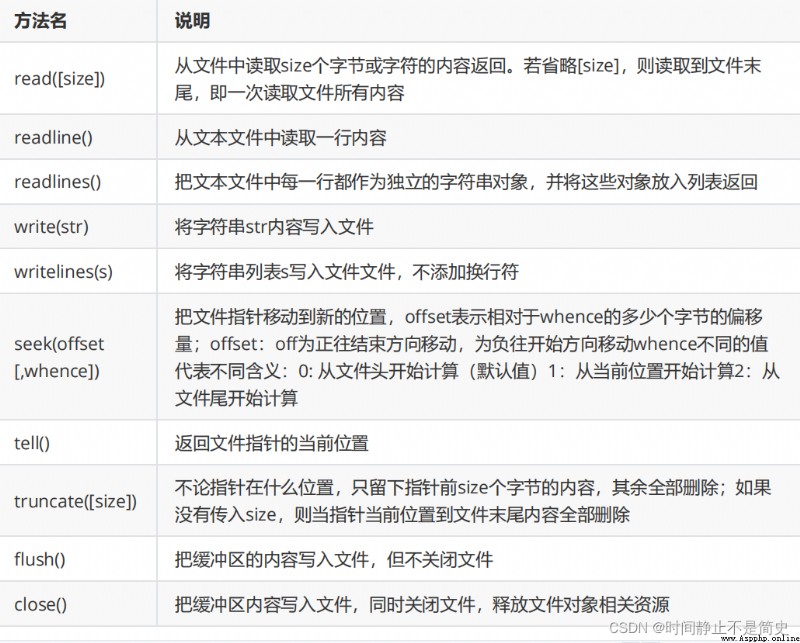
文件的讀取一般使用如下三個方法:
read([size]): 從文件中讀取 size 個字符,並作為結果返回
如果沒有 size 參數,則讀取整個文件. 讀取到文件末尾,會返回空字符串
readline(): 讀取一行內容作為結果返回
讀取到文件末尾,會返回空字符串
readlines() : 文本文件中,每一行作為一個字符串存入列表中,返回該列表
代碼格式
with open(r"d:\a.txt", "r"[, encoding="utf-8"]) as f:
f.read(4)
注意:
encoding="utf-8",UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 13: invalid start byte實操代碼
# 【操作】 讀取一個文件前4個字符
import pickle
with open(r"d:\a.txt", "r") as f:
print(f.read(4))
# 【操作】文件較小,一次將文件內容讀入到程序中
with open(r"d:\aa.txt", "r") as f:
print(f.read())
# 【操作】按行讀取一個文件
with open(r"d:\b.txt") as f:
while True:
lines = f.readline()
if not lines: # 在python 中 if not 會將後面對象隱式轉成True或者False進行判斷, 因此遇到空字符串也返回False
break
else:
print(lines, end="")
print()
# 【操作】使用迭代器(每次返回一行)讀取文本文件
# 寫和讀的編碼要對應
with open(r"d:\bb.txt", "r", encoding="utf-8") as f:
for a in f:
print(a, end="")
# 【操作】為文本文件每一行的末尾增加行號
with open(r"d:\c.txt", "r") as f:
lines = f.readlines()
lines2 = [line.rstrip() + " # " + str(index) + "\n" for index, line in zip(range(1, len(lines) + 1), lines)]
with open(r"d:\c.txt", "w") as ff:
ff.writelines(lines2)
二進制文件的處理流程和文本文件流程一致。首先還是要創建文件對象,
創建好二進制文件對象後,仍然可以使用 write() 、 read() 實現文件的讀寫操作
在創建文件對象時, 首先需要指定二進制模式,然後才能創建出二進制文件對象. 例如
f = open(r"d:\a.txt", 'wb') 可寫的、重寫模式的二進制文件對象f = open(r"d:\a.txt", 'ab') 可寫的、追加模式的二進制文件對象f = open(r"d:\a.txt", 'rb') 可讀的二進制文件對象實操代碼
# 二進制文件的讀取和寫入(此操作相當於復制)
# f = open(r"d:\a.txt", 'wb') #可寫的、重寫模式的二進制文件對象
# f = open(r"d:\a.txt", 'ab') #可寫的、追加模式的二進制文件對象
# f = open(r"d:\a.txt", 'rb') #可讀的二進制文件對象
with open(r"d:\aaa.png", "rb") as scrFile, open(r"d:\bbb.png", "wb") as destFile:
for l in scrFile:
destFile.write(l)
文件對象的屬性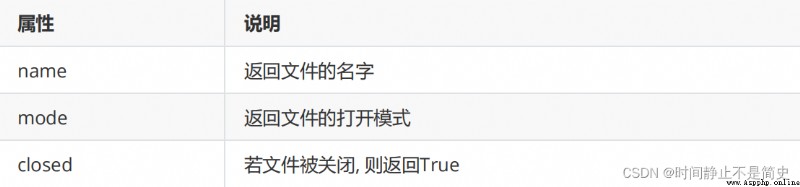
文件對象的打開模式
文件對象的常用方法
利用 seek() 可以將讀取文件的指針移動到指定字節位置上
一個中文字符站兩個字節, 而英文只占一個字節
實操代碼
print("=================文件任意位置操作======================")
# 【示例】 seek() 移動文件指針示例
with open(r"d:\cc.txt", "r") as f:
print("文件名是{0}".format(f.name)) # 文件名是d:\cc.txt
print(f.tell()) # 0
print("讀取文件的內容", str(f.readline())) # 讀取文件的內容 齊格飛齊格飛齊格飛
print(f.tell()) # 18
f.seek(4, 0) # 中文占2個字節, 因此在seek時需要是2的倍數
print("文件讀取的內容", str(f.readline())) # 文件讀取的內容 飛齊格飛齊格飛
print(f.tell()) # 18
序列化指的是:將對象轉化成“串行化”數據形式,存儲到硬盤或通過網絡傳輸到其他地方.
反序列化是指相反的過程,將讀取到的“串行化數據”轉化成對象
可以使用pickle模塊中的函數,實現序列化和反序列操作
序列化我們使用:
pickle.dump(obj, file) obj 就是要被序列化的對象, file 指的是存儲的文件pickle.load(file) 從 file 讀取數據,反序列化成對象實操代碼
import pickle
print("=================使用pickle序列化=======================")
# 【操作】將對象序列化到文件中
with open("student.info", "wb") as f:
name = "時間靜止"
age = 18
score = [90, 80, 70]
resume = {
"name": name, "age": age, "score": score}
pickle.dump(resume, f)
# 【操作】將獲得的數據反序列化成對象
with open("student.info", "rb") as f:
resume = pickle.load(f)
print(resume)
csv是逗號分隔符文本格式,常用於數據交換、Excel文件和數據庫數據的導入和導出
與Excel文件不同,CSV文件中:
Python標准庫的模塊csv提供了讀取和寫入csv格式文件的對象
我們在excel中建立一個簡單的表格並且另存為 csv(逗號分隔) ,我們打開查看這個csv文件內容
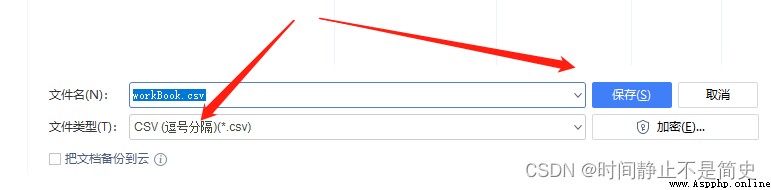
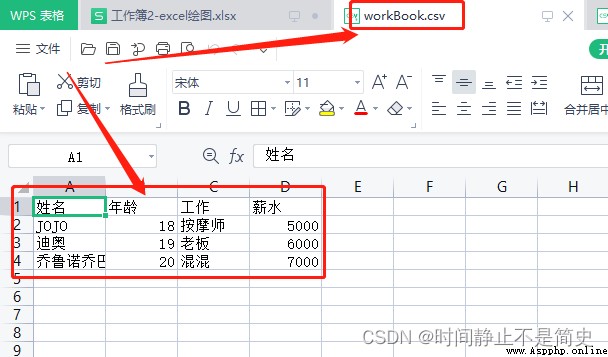
實操代碼
import csv
with open(r"d:\workBook.csv") as a:
o_csv = csv.reader(a) # #創建csv對象,它是一個包含所有數據的列表,每一行為一個元素
headers = next(o_csv) # #獲得列表對象,包含標題行的信息
print(headers)
for row in o_csv: # 循環打印各行內容
print(row)
結果展示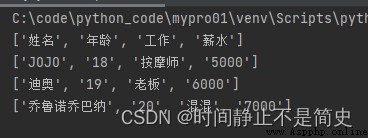
實操代碼
# 【操作】 csv.writer 對象寫一個csv文件
headers = ['姓名', '年齡', '工作', '住址']
rows = [('JOJO', '18', '按摩師', '英國'), ('迪奧', '19', '老板', '埃及'), ('喬魯諾喬巴納', '20', '混混', '意呆利')]
with open(r"d:\workBook3.csv", "w") as b:
b_scv = csv.writer(b) # 創建csv對象
b_scv.writerow(headers) # 寫入一行(標題)
b_scv.writerows(rows) # 寫入多行(數據)
結果展示

os模塊 可以幫助我們直接對操作系統進行操作.
我們可以直接調用操作系統的可執行文件、命令,直接操作文件、目錄等等
os模塊 是做系統運維非常重要的基礎
實操代碼
# 【示例】 os.system 調用windows系統的記事本程序
os.system("notepad.exe")
# 【示例】 os.system 調用windows系統中ping命令
# 如果出現亂碼, 請看 文件操作->文件的寫入->中文亂碼->控制台輸出時 進行配置
os.system("ping www.baidu.com")
# 【示例】運行安裝好的微信
os.startfile(r"C:\Program Files (x86)\Tencent\WeChat\WeChat.exe")
可以通過前面講的文件對象實現對於文件內容的讀寫操作.
如果還需要對文件和目錄做其他操作,可以使用 os 和 os.path 模塊.

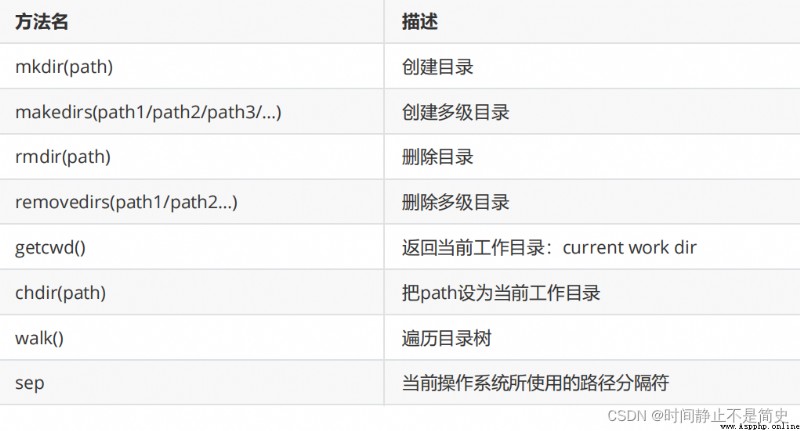
實操代碼
import os
# 【示例】 os 模塊:創建、刪除目錄、獲取文件信息等
print("系統名稱:", os.name) # windows-->nt linux-->posix
print("當前操作系統所使用的路徑分隔符:", os.sep) # windows-->\ linux-->/
print("行間隔符:", repr(os.linesep)) # windows-->\r\n linux-->\n
print("當前目錄:", os.curdir)
a = "3"
print(a)
# 返回對象的規范字符串表示
print(repr(a))
# 獲取文件和文件夾的相關信息
print(os.stat("MyPy08-FileRead.py"))
# 工作目錄的操作
print(os.getcwd()) # 獲取當前工作目錄
os.chdir("D:") # 切換當前工作目錄
os.mkdir("學習資料大全") # 創建目錄
os.rmdir("學習資料大全") # 刪除目錄
# os.makedirs("人種/黃種人/中國人") # 創建多級目錄, 調用成功一次之後, 再次調用會報錯
# os.rename("人種", "亞洲人") # 此方法也只能調用一次
print(os.listdir("亞洲人")) # 當前目錄下的子目錄
注意事項
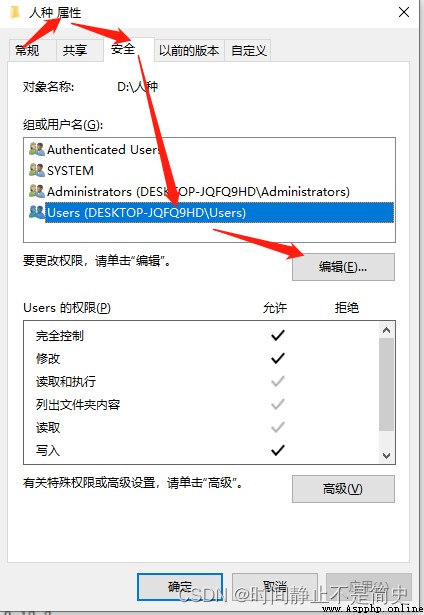
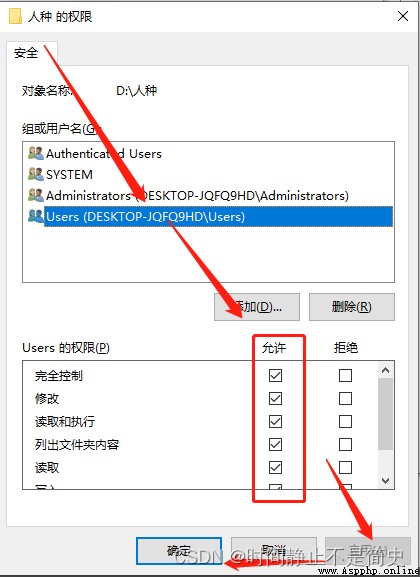
在調用 os.rename() 時, 如果出現報錯 PermissionError: [WinError 5] 拒絕訪問,
則需要你在需要重命名的文件夾上面配置用戶的權限. 修改之後便可進行重命名. 如下圖所示
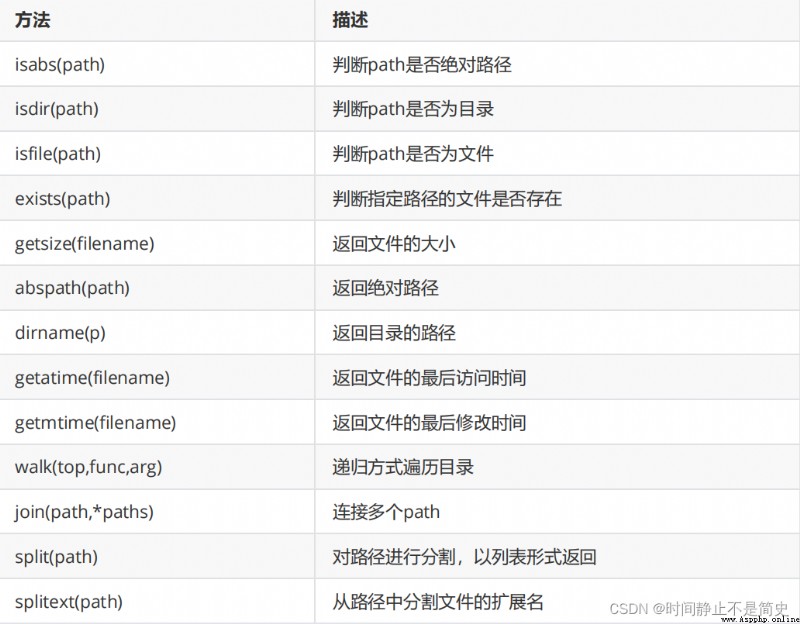
os.path 模塊提供了目錄相關(路徑判斷、路徑切分、路徑連接、文件夾遍歷)的操作
實操代碼
# 【示例】測試 os.path 中常用方法
print("是否是絕對路徑:", os.path.isabs("d:/a.txt"))
print("是否是目錄: ", os.path.isdir(r"d:\a.txt"))
print("文件是否存在: ", os.path.exists("a.txt"))
print("文件大小: ", os.path.getsize("a.txt"))
print("輸出絕對路徑:", os.path.abspath("a.txt"))
print("輸出所在目錄:", os.path.dirname("d:/a.txt"))
# 獲得創建時間、訪問時間、最後修改時間
print("輸出創建