前言
首先使用Python將Word文件導入
row和cell解析所需內容
內層解析循環
前言大家好,今天有一個公務員的小伙伴委托我給他幫個忙,大概是有這樣一份Word(由於涉及文件私密所以文中的具體內容已做修改)

一共有近2600條類似格式的表格細欄,每個欄目包括的信息有:
日期
發文單位
文號
標題
簽收欄
需要提取其中加粗的這三項內容到Excel表格中存儲,表格樣式如下:
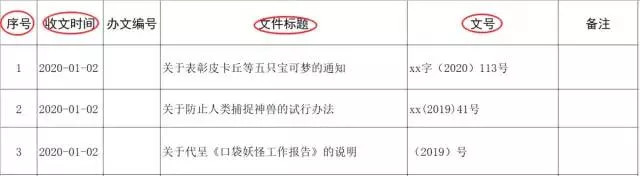
也就是需要將收文時間、文件標題、文號填到指定位置,同時需要將時間修改為標准格式,如果是完全手動復制和修改時間,依照一個條目10s的時間計算,一分鐘可以完成6條,那麼最快也需要:
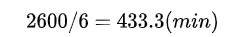
而這類格式規整的文件整理非常適合用Python來執行,好的那麼接下來請Python出場,必要的信息我在代碼中以注釋信息呈現。
首先使用Python將Word文件導入# 導入需要的庫docxfrom docx import Document# 指定文件存放的路徑path = r'C:\Users\word.docx' # 讀取文件document = Document(path)# 讀取word中的所有表格tables = document.tables再把問題逐個劃分,首先嘗試獲取第一張表第一個文件條目的三個所需信息
# 獲取第一張表table0 = tables[0]仔細觀察可以發現一個文件條目占據了3行,所以對表格全部行循環迭代時可以設步長為3
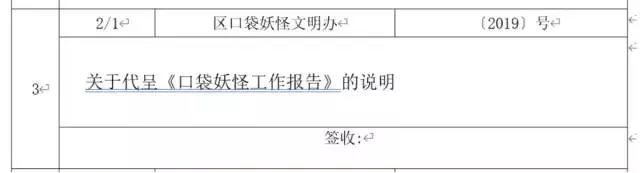
注意觀察表格,按照row和cell把所需內容解析清楚
# 在全局放一個變量用來計數填序號n = 0for i in range(0, len(table0.rows) + 1, 3): # 日期 date = table0.cell(i, 1).text # 標題 title = table0.cell(i + 1, 1).text.strip() # 文號 dfn = tables[j].cell(i, 3).text.strip() print(n, date, tite, dfn)接下來需要解決的是,時間我們獲取的是 2/1 這種 日/月的形式。我們需要轉化成 YYYY-MM-DD格式,而這利用到datetime包的strptime和strftime函數:
strptime: 解析字符串中蘊含的時間
strftime: 轉化成所需的時間格式
import datetimen = 0for i in range(0, len(table0.rows) + 1, 3): # 日期 date = table0.cell(i, 1).text # 有的條目時間是空的,這裡不做過多判別 if '/' in date: date = datetime.datetime.strptime(date, '%d/%m').strftime('2020-%m-%d') else: date = '-' # 標題 title = table0.cell(i + 1, 1).text.strip() # 文號 dfn = tables[j].cell(i, 3).text.strip() print(n, date, tite, dfn)這樣一張表的內容解析就完成了,注意這裡用的是table[0]即第一張表,遍歷所有的表加一個嵌套循環就可以,另外也可以捕獲異常增加程序靈活性
n = 0for j in range(len(tables)): for i in range(0, len(tables[j].rows)+1, 3): try: # 日期 date = tables[j].cell(i, 1).text if '/' in date: date = datetime.datetime.strptime(date, '%d/%m').strftime('2020-%m-%d') else: date = '-' # 標題 title = tables[j].cell(i + 1, 1).text.strip() # 文號 dfn = tables[j].cell(i, 3).text.strip() n += 1 print(n, date, title, dfn) except Exception as error: # 捕獲異常,也可以用log寫到日志裡方便查看和管理 print(error) continue信息解析和獲取完成就可以導出了,用到的包是openpyxl
from openpyxl import Workbook# 實例化wb = Workbook()# 獲取當前sheetsheet = wb.active# 設立表頭header = ['序號', '收文時間', '辦文編號', '文件標題', '文號', '備注']sheet.append(header)內層解析循環在最內層解析循環的末尾加上如下代碼即可
row = [n, date, ' ', title, dfn, ' ']sheet.append(row)線程的最後記得保存
wb.save(r'C:\Users\20200420.xlsx')運行時間在10分鐘左右,大概離開了一會程序就執行結束了
最後附上完整代碼,代碼很簡單,理清思路最重要
from docx import Documentimport datetimefrom openpyxl import Workbookwb = Workbook()sheet = wb.activeheader = ['序號', '收文時間', '辦文編號', '文件標題', '文號', '備注']sheet.append(header)path = r'C:\Users\word.docx'document = Document(path)tables = document.tablesn = 0for j in range(len(tables)): for i in range(0, len(tables[j].rows)+1, 3): try: # 日期 date = tables[j].cell(i, 1).text if '/' in date: date = datetime.datetime.strptime(date, '%d/%m').strftime('2020-%m-%d') else: date = '-' # 標題 title = tables[j].cell(i + 1, 1).text.strip() # 文號 dfn = tables[j].cell(i, 3).text.strip() n += 1 print(n, date, title, dfn) row = [n, date, ' ', title, dfn, ' '] sheet.append(row) except Exception as error: # 捕獲異常,也可以用log寫到日志裡方便查看和管理 print(error) continuewb.save(r'C:\Users\20200420.xlsx')以上就是Python辦公自動化Word轉Excel文件批量處理的詳細內容,更多關於Python辦公自動化Word轉Excel的資料請關注軟件開發網其它相關文章!