引入依賴
算法相關依賴
獲取數據
生成df
重命名列
增加列
缺失值處理
獨熱編碼
替換值
刪除列
數據篩選
差值計算
數據修改
時間格式轉換
設置索引列
折線圖
散點圖
柱狀圖
熱力圖
66個最常用的pandas數據分析函數
從各種不同的來源和格式導入數據
導出數據
創建測試對象
查看、檢查數據
數據選取
數據清理
篩選,排序和分組依據
數據合並
數據統計
16個函數,用於數據清洗
1.cat函數
2.contains
3.startswith/endswith
4.count
5.get
6.len
7.upper/lower
8.pad+side參數/center
9.repeat
10.slice_replace
11.replace
12.replace
13.split方法+expand參數
14.strip/rstrip/lstrip
15.findall
16.extract/extractall
引入依賴# 導入模塊import pymysqlimport pandas as pdimport numpy as npimport time# 數據庫from sqlalchemy import create_engine# 可視化import matplotlib.pyplot as plt# 如果你的設備是配備Retina屏幕的mac,可以在jupyter notebook中,使用下面一行代碼有效提高圖像畫質%config InlineBackend.figure_format = 'retina'# 解決 plt 中文顯示的問題 mymacplt.rcParams['font.sans-serif'] = ['Arial Unicode MS']# 設置顯示中文 需要先安裝字體 aistudioplt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默認字體plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號import seaborn as sns# notebook渲染圖片%matplotlib inlineimport pyecharts# 忽略版本問題import warningswarnings.filterwarnings("ignore") # 下載中文字體!wget https://mydueros.cdn.bcebos.com/font/simhei.ttf # 將字體文件復制到 matplotlib'字體路徑!cp simhei.ttf /opt/conda/envs/python35-paddle120-env/Lib/python3,7/site-packages/matplotib/mpl-data/fonts.# 一般只需要將字體文件復制到系統字體田錄下即可,但是在 studio上該路徑沒有寫權限,所以此方法不能用 # !cp simhei. ttf /usr/share/fonts/# 創建系統字體文件路徑!mkdir .fonts# 復制文件到該路徑!cp simhei.ttf .fonts/!rm -rf .cache/matplotlib
# 數據歸一化from sklearn.preprocessing import MinMaxScaler# kmeans聚類from sklearn.cluster import KMeans# DBSCAN聚類from sklearn.cluster import DBSCAN# 線性回歸算法from sklearn.linear_model import LinearRegression# 邏輯回歸算法from sklearn.linear_model import LogisticRegression# 高斯貝葉斯from sklearn.naive_bayes import GaussianNB# 劃分訓練/測試集from sklearn.model_selection import train_test_split# 准確度報告from sklearn import metrics# 矩陣報告和均方誤差from sklearn.metrics import classification_report, mean_squared_error獲取數據from sqlalchemy import create_engineengine = create_engine('mysql+pymysql://root:[email protected]:3306/ry?charset=utf8')# 查詢插入後相關表名及行數result_query_sql = "use information_schema;"engine.execute(result_query_sql)result_query_sql = "SELECT table_name,table_rows FROM tables WHERE TABLE_NAME LIKE 'log%%' order by table_rows desc;"df_result = pd.read_sql(result_query_sql, engine)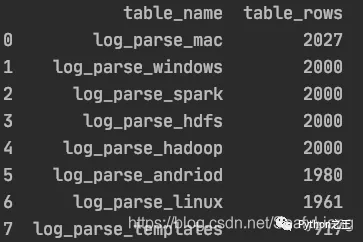
# list轉dfdf_result = pd.DataFrame(pred,columns=['pred'])df_result['actual'] = test_targetdf_result# df取子dfdf_new = df_old[['col1','col2']]# dict生成dfdf_test = pd.DataFrame({<!-- -->'A':[0.587221, 0.135673, 0.135673, 0.135673, 0.135673], 'B':['a', 'b', 'c', 'd', 'e'], 'C':[1, 2, 3, 4, 5]})# 指定列名data = pd.DataFrame(dataset.data, columns=dataset.feature_names)# 使用numpy生成20個指定分布(如標准正態分布)的數tem = np.random.normal(0, 1, 20)df3 = pd.DataFrame(tem)# 生成一個和df長度相同的隨機數dataframedf1 = pd.DataFrame(pd.Series(np.random.randint(1, 10, 135)))重命名列# 重命名列data_scaled = data_scaled.rename(columns={<!-- -->'本體油位': 'OILLV'})增加列# df2dfdf_jj2yyb['r_time'] = pd.to_datetime(df_jj2yyb['cTime'])# 新增一列根據salary將數據分為3組bins = [0,5000, 20000, 50000]group_names = ['低', '中', '高']df['categories'] = pd.cut(df['salary'], bins, labels=group_names)缺失值處理# 檢查數據中是否含有任何缺失值df.isnull().values.any()# 查看每列數據缺失值情況df.isnull().sum()# 提取某列含有空值的行df[df['日期'].isnull()]# 輸出每列缺失值具體行數for i in df.columns: if df[i].count() != len(df): row = df[i][df[i].isnull().values].index.tolist() print('列名:"{}", 第{}行位置有缺失值'.format(i,row))# 眾數填充heart_df['Thal'].fillna(heart_df['Thal'].mode(dropna=True)[0], inplace=True)# 連續值列的空值用平均值填充dfcolumns = heart_df_encoded.columns.values.tolist()for item in dfcolumns: if heart_df_encoded[item].dtype == 'float': heart_df_encoded[item].fillna(heart_df_encoded[item].median(), inplace=True)獨熱編碼df_encoded = pd.get_dummies(df_data)替換值# 按列值替換num_encode = {<!-- --> 'AHD': {<!-- -->'No':0, "Yes":1},}heart_df.replace(num_encode,inplace=True)刪除列df_jj2.drop(['coll_time', 'polar', 'conn_type', 'phase', 'id', 'Unnamed: 0'],axis=1,inplace=True)數據篩選# 取第33行數據df.iloc[32]# 某列以xxx字符串開頭df_jj2 = df_512.loc[df_512["transformer"].str.startswith('JJ2')]df_jj2yya = df_jj2.loc[df_jj2["變壓器編號"]=='JJ2YYA']# 提取第一列中不在第二列出現的數字df['col1'][~df['col1'].isin(df['col2'])]# 查找兩列值相等的行號np.where(df.secondType == df.thirdType)# 包含字符串results = df['grammer'].str.contains("Python")# 提取列名df.columns# 查看某列唯一值(種類)df['education'].nunique()# 刪除重復數據df.drop_duplicates(inplace=True)# 某列等於某值df[df.col_name==0.587221]# df.col_name==0.587221 各行判斷結果返回值(True/False)# 查看某列唯一值及計數df_jj2["變壓器編號"].value_counts()# 時間段篩選df_jj2yyb_0501_0701 = df_jj2yyb[(df_jj2yyb['r_time'] >=pd.to_datetime('20200501')) & (df_jj2yyb['r_time'] <= pd.to_datetime('20200701'))]# 數值篩選df[(df['popularity'] > 3) & (df['popularity'] < 7)]# 某列字符串截取df['Time'].str[0:8]# 隨機取num行ins_1 = df.sample(n=num)# 數據去重df.drop_duplicates(['grammer'])# 按某列排序(降序)df.sort_values("popularity",inplace=True, ascending=False)# 取某列最大值所在行df[df['popularity'] == df['popularity'].max()]# 取某列最大num行df.nlargest(num,'col_name')# 最大num列畫橫向柱形圖df.nlargest(10).plot(kind='barh')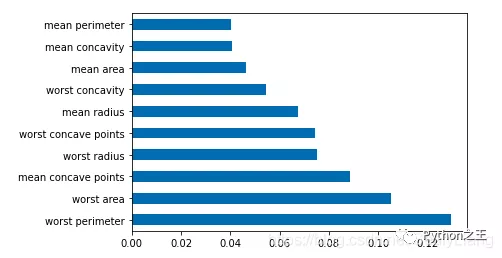
# axis=0或index表示上下移動, periods表示移動的次數,為正時向下移,為負時向上移動。print(df.diff( periods=1, axis=‘index‘))print(df.diff( periods=-1, axis=0))# axis=1或columns表示左右移動,periods表示移動的次數,為正時向右移,為負時向左移動。print(df.diff( periods=1, axis=‘columns‘))print(df.diff( periods=-1, axis=1))# 變化率計算data['收盤價(元)'].pct_change()# 以5個數據作為一個數據滑動窗口,在這個5個數據上取均值df['收盤價(元)'].rolling(5).mean()數據修改# 刪除最後一行df = df.drop(labels=df.shape[0]-1)# 添加一行數據['Perl',6.6]row = {<!-- -->'grammer':'Perl','popularity':6.6}df = df.append(row,ignore_index=True)# 某列小數轉百分數df.style.format({<!-- -->'data': '{0:.2%}'.format})# 反轉行df.iloc[::-1, :]# 以兩列制作數據透視pd.pivot_table(df,values=["salary","score"],index="positionId")# 同時對兩列進行計算df[["salary","score"]].agg([np.sum,np.mean,np.min])# 對不同列執行不同的計算df.agg({<!-- -->"salary":np.sum,"score":np.mean})時間格式轉換# 時間戳轉時間字符串df_jj2['cTime'] =df_jj2['coll_time'].apply(lambda x: time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(x)))# 時間字符串轉時間格式df_jj2yyb['r_time'] = pd.to_datetime(df_jj2yyb['cTime'])# 時間格式轉時間戳dtime = pd.to_datetime(df_jj2yyb['r_time'])v = (dtime.values - np.datetime64('1970-01-01T08:00:00Z')) / np.timedelta64(1, 'ms')df_jj2yyb['timestamp'] = v設置索引列df_jj2yyb_small_noise = df_jj2yyb_small_noise.set_index('timestamp')折線圖fig, ax = plt.subplots()df.plot(legend=True, ax=ax)plt.legend(loc=1)plt.show()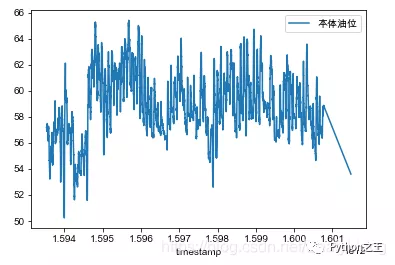
plt.figure(figsize=(20, 6))plt.plot(max_iter_list, accuracy, color='red', marker='o', markersize=10)plt.title('Accuracy Vs max_iter Value')plt.xlabel('max_iter Value')plt.ylabel('Accuracy')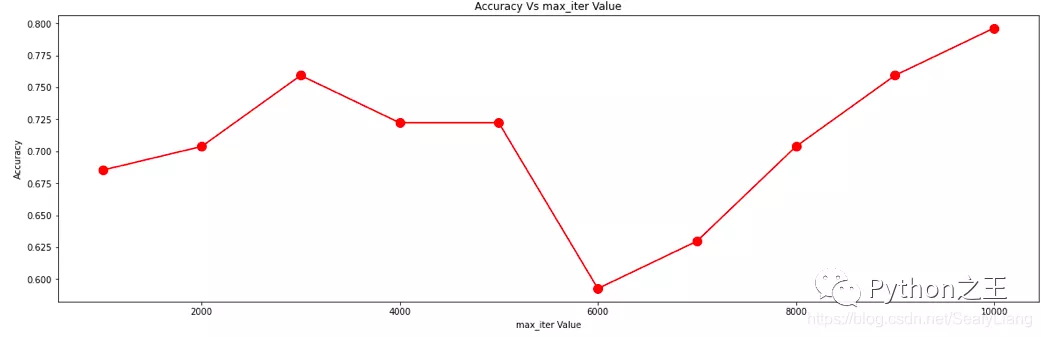
plt.scatter(df[:, 0], df[:, 1], c="red", marker='o', label='lable0') plt.xlabel('x') plt.ylabel('y') plt.legend(loc=2) plt.show() 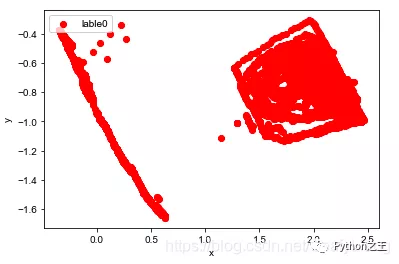
df = pd.Series(tree.feature_importances_, index=data.columns)# 取某列最大Num行畫橫向柱形圖df.nlargest(10).plot(kind='barh')
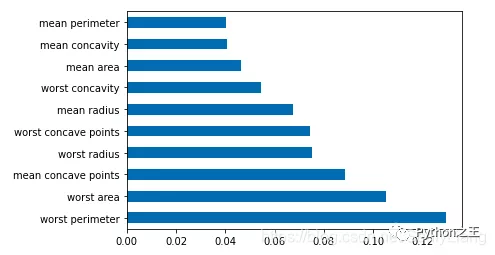
df_corr = combine.corr()plt.figure(figsize=(20,20))g=sns.heatmap(df_corr,annot=True,cmap="RdYlGn")
df #任何pandas DataFrame對象 s #任何pandas series對象從各種不同的來源和格式導入數據pd.read_csv(filename) # 從CSV文件 pd.read_table(filename) # 從分隔的文本文件(例如CSV)中 pd.read_excel(filename) # 從Excel文件 pd.read_sql(query, connection_object) # 從SQL表/數據庫中讀取 pd.read_json(json_string) # 從JSON格式的字符串,URL或文件中讀取。pd.read_html(url) # 解析html URL,字符串或文件,並將表提取到數據幀列表 pd.read_clipboard() # 獲取剪貼板的內容並將其傳遞給 read_table() pd.DataFrame(dict) # 從字典中,列名稱的鍵,列表中的數據的值導出數據df.to_csv(filename) # 寫入CSV文件 df.to_excel(filename) # 寫入Excel文件 df.to_sql(table_name, connection_object) # 寫入SQL表 df.to_json(filename) # 以JSON格式寫入文件創建測試對象pd.DataFrame(np.random.rand(20,5)) # 5列20行隨機浮點數 pd.Series(my_list) # 從一個可迭代的序列創建一個序列 my_list df.index = pd.date_range('1900/1/30', periods=df.shape[0]) # 添加日期索引查看、檢查數據df.head(n) # DataFrame的前n行 df.tail(n) # DataFrame的最後n行 df.shape # 行數和列數 df.info() # 索引,數據類型和內存信息 df.describe() # 數值列的摘要統計信息 s.value_counts(dropna=False) # 查看唯一值和計數 df.apply(pd.Series.value_counts) # 所有列的唯一值和計數數據選取使用這些命令選擇數據的特定子集。df[col] # 返回帶有標簽col的列 df[[col1, col2]] # 返回列作為新的DataFrame s.iloc[0] # 按位置選擇 s.loc['index_one'] # 按索引選擇 df.iloc[0,:] # 第一行 df.iloc[0,0] # 第一欄的第一元素數據清理df.columns = ['a','b','c'] # 重命名列 pd.isnull() # 空值檢查,返回Boolean Arrray pd.notnull() # 與pd.isnull() 相反 df.dropna() # 刪除所有包含空值的行 df.dropna(axis=1) # 刪除所有包含空值的列 df.dropna(axis=1,thresh=n) # 刪除所有具有少於n個非null值的行 df.fillna(x) # 將所有空值替換為x s.fillna(s.mean()) # 用均值替換所有空值(均值可以用統計模塊中的幾乎所有函數替換 ) s.astype(float) # 將系列的數據類型轉換為float s.replace(1,'one') # 1 用 'one' s.replace([1,3],['one','three']) # 替換所有等於的值 替換為所有1 'one' ,並 3 用 'three' df.rename(columns=lambda x: x + 1) # 列的重命名 df.rename(columns={<!-- -->'old_name': 'new_ name'})# 選擇性重命名 df.set_index('column_one') # 更改索引 df.rename(index=lambda x: x + 1) # 大規模重命名索引篩選,排序和分組依據df[df[col] > 0.5] # 列 col 大於 0.5 df[(df[col] > 0.5) & (df[col] < 0.7)] # 小於 0.7 大於0.5的行 df.sort_values(col1) # 按col1升序對值進行排序 df.sort_values(col2,ascending=False) # 按col2 降序對值進行 排序 df.sort_values([col1,col2],ascending=[True,False]) #按 col1 升序排序,然後 col2 按降序排序 df.groupby(col) #從一個欄返回GROUPBY對象 df.groupby([col1,col2]) # 返回來自多個列的groupby對象 df.groupby(col1)[col2] # 返回中的值的平均值 col2,按中的值分組 col1 (平均值可以用統計模塊中的幾乎所有函數替換 ) df.pivot_table(index=col1,values=[col2,col3],aggfunc=mean) # 創建一個數據透視表組通過 col1 ,並計算平均值的 col2 和 col3 df.groupby(col1).agg(np.mean) # 在所有列中找到每個唯一col1 組的平均值 df.apply(np.mean) #np.mean() 在每列上應用該函數 df.apply(np.max,axis=1) # np.max() 在每行上應用功能數據合並df1.append(df2) # 將df2添加 df1的末尾 (各列應相同) pd.concat([df1, df2],axis=1) # 將 df1的列添加到df2的末尾 (行應相同) df1.join(df2,on=col1,how='inner') # SQL樣式將列 df1 與 df2 行所在的列col 具有相同值的列連接起來。'how'可以是一個 'left', 'right', 'outer', 'inner'數據統計df.describe() # 數值列的摘要統計信息 df.mean() # 返回均值的所有列 df.corr() # 返回DataFrame中各列之間的相關性 df.count() # 返回非空值的每個數據幀列中的數字 df.max() # 返回每列中的最高值 df.min() # 返回每一列中的最小值 df.median() # 返回每列的中位數 df.std() # 返回每列的標准偏差16個函數,用於數據清洗# 導入數據集import pandas as pddf ={<!-- -->'姓名':[' 黃同學','黃至尊','黃老邪 ','陳大美','孫尚香'], '英文名':['Huang tong_xue','huang zhi_zun','Huang Lao_xie','Chen Da_mei','sun shang_xiang'], '性別':['男','women','men','女','男'], '身份證':['463895200003128433','429475199912122345','420934199110102311','431085200005230122','420953199509082345'], '身高':['mid:175_good','low:165_bad','low:159_bad','high:180_verygood','low:172_bad'], '家庭住址':['湖北廣水','河南信陽','廣西桂林','湖北孝感','廣東廣州'], '電話號碼':['13434813546','19748672895','16728613064','14561586431','19384683910'], '收入':['1.1萬','8.5千','0.9萬','6.5千','2.0萬']}df = pd.DataFrame(df)df1.cat函數用於字符串的拼接
df["姓名"].str.cat(df["家庭住址"],sep='-'*3)2.contains判斷某個字符串是否包含給定字符
df["家庭住址"].str.contains("廣")3.startswith/endswith判斷某個字符串是否以…開頭/結尾
# 第一個行的“ 黃偉”是以空格開頭的df["姓名"].str.startswith("黃") df["英文名"].str.endswith("e")4.count計算給定字符在字符串中出現的次數
df["電話號碼"].str.count("3")5.get獲取指定位置的字符串
df["姓名"].str.get(-1)df["身高"].str.split(":")df["身高"].str.split(":").str.get(0)6.len計算字符串長度
df["性別"].str.len()7.upper/lower英文大小寫轉換
df["英文名"].str.upper()df["英文名"].str.lower()8.pad+side參數/center在字符串的左邊、右邊或左右兩邊添加給定字符
df["家庭住址"].str.pad(10,fillchar="*") # 相當於ljust()df["家庭住址"].str.pad(10,side="right",fillchar="*") # 相當於rjust()df["家庭住址"].str.center(10,fillchar="*")9.repeat重復字符串幾次
df["性別"].str.repeat(3)10.slice_replace使用給定的字符串,替換指定的位置的字符
df["電話號碼"].str.slice_replace(4,8,"*"*4)11.replace將指定位置的字符,替換為給定的字符串
df["身高"].str.replace(":","-")12.replace將指定位置的字符,替換為給定的字符串(接受正則表達式)
replace中傳入正則表達式,才叫好用;- 先不要管下面這個案例有沒有用,你只需要知道,使用正則做數據清洗多好用;
df["收入"].str.replace("\d+\.\d+","正則")13.split方法+expand參數搭配join方法功能很強大
# 普通用法df["身高"].str.split(":")# split方法,搭配expand參數df[["身高描述","final身高"]] = df["身高"].str.split(":",expand=True)df# split方法搭配join方法df["身高"].str.split(":").str.join("?"*5)14.strip/rstrip/lstrip去除空白符、換行符
df["姓名"].str.len()df["姓名"] = df["姓名"].str.strip()df["姓名"].str.len()15.findall利用正則表達式,去字符串中匹配,返回查找結果的列表
findall使用正則表達式,做數據清洗,真的很香!
df["身高"]df["身高"].str.findall("[a-zA-Z]+")16.extract/extractall接受正則表達式,抽取匹配的字符串(一定要加上括號)
df["身高"].str.extract("([a-zA-Z]+)")# extractall提取得到復合索引df["身高"].str.extractall("([a-zA-Z]+)")# extract搭配expand參數df["身高"].str.extract("([a-zA-Z]+).*?([a-zA-Z]+)",expand=True以上就是Python Pandas數據處理高頻操作詳解的詳細內容,更多關於Python Pandas數據處理的資料請關注軟件開發網其它相關文章!