DNA序列
簡述其代碼
原始序列上進行替換
利用upper()輸出大寫結果
結尾
DNA序列ACTGATCGATTACGTATAGTATTTGCTATCATACATATATATCGATGCGTTCAT
求其互補DNA序列。
在生物上DNA互補序列簡述表達可以表示為:A與T,C與G互補,可以理解為將上述序列中現有的A用T代替,C用G代替,T用A代替,G用C代替,則其互補序列為:
TGACTAGCTAATGCATATCATAAACGATAGTATGTATATATAGCTACGCAAGTA
根據上述表述,我可以利用replace()函數進行替換,將A用T替換,T用A替換,C用G替換,G用C替換,
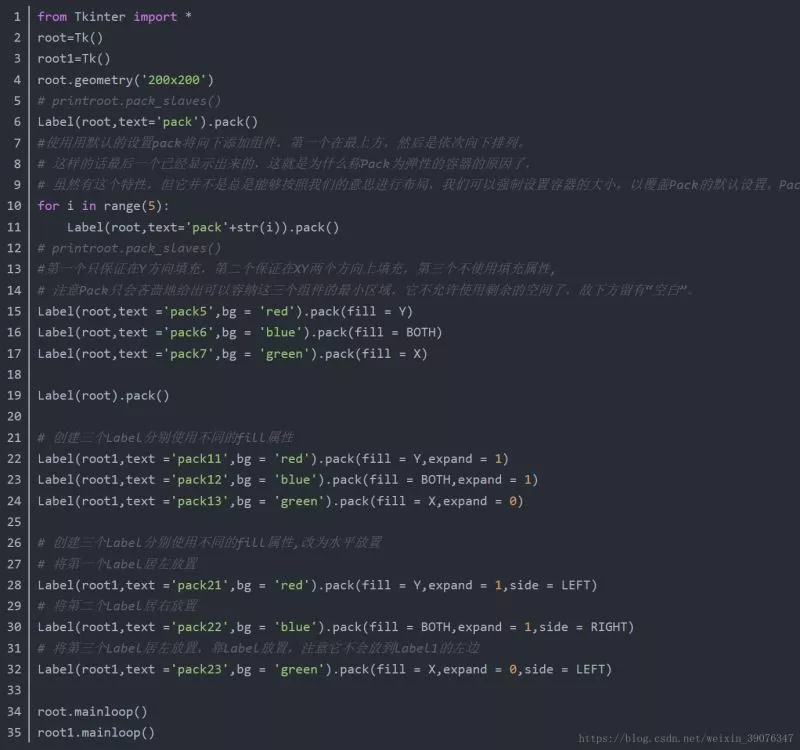
簡述其代碼my_dna = "ACTGATCGATTACGTATAGTATTTGCTATCATACATATATATCGATGCGTTCAT"# replace A with Tsequence1 = my_dna.replace('A', 'T')# replace T with Asequence2 = sequence1.replace('T', 'A')# replace C with Gsequence3 = sequence2.replace('C', 'G')# replace G with Csequence4 = sequence3.replace('G', 'C')# print the result of the final replacementprint(sequence1)print(sequence2)print(sequence3)print(sequence4)其輸出結果如下:
原始序列上進行替換TCTGTTCGTTTTCGTTTTGTTTTTGCTTTCTTTCTTTTTTTTCGTTGCGTTCTT
ACAGAACGAAAACGAAAAGAAAAAGCAAACAAACAAAAAAAACGAAGCGAACAA
AGAGAAGGAAAAGGAAAAGAAAAAGGAAAGAAAGAAAAAAAAGGAAGGGAAGAA
ACACAACCAAAACCAAAACAAAAACCAAACAAACAAAAAAAACCAACCCAACAA
顯然結果是不正確的,我們在sequence1到sequence2中就已經出現錯誤,誤把sequence1中A被替換之後變為T的序列,在sequence2中又被替換掉了,因此我們要轉變思路,保持只替換原本的序列,不進行多次替換,避免錯誤,我們可以嘗試每次只在原始序列上進行替換,嘗試代碼如下:
my_dna = "ACTGATCGATTACGTATAGTATTTGCTATCATACATATATATCGATGCGTTCAT"# replace A with Tsequence = my_dna.replace('A', 'T')# replace T with Asequence2 = my_dna.replace('T', 'A')# replace C with Gsequence3 = my_dna.replace('C', 'G')# replace G with Csequence4 = my_dna.replace('G', 'C')print(sequence1)print(sequence2)print(sequence3)print(sequence4)其輸出結果如下:
TCTGTTCGTTTTCGTTTTGTTTTTGCTTTCTTTCTTTTTTTTCGTTGCGTTCTT
ACAGAACGAAAACGAAAAGAAAAAGCAAACAAACAAAAAAAACGAAGCGAACAA
AGTGATGGATTAGGTATAGTATTTGGTATGATAGATATATATGGATGGGTTGAT
ACTCATCCATTACCTATACTATTTCCTATCATACATATATATCCATCCCTTCAT
顯然結果也是不正確的,因此,我們要引入中間變量,最後再把它做一個回環,
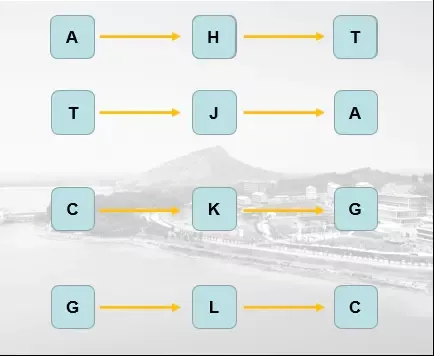
也就是說引入四個臨時字母,然後每個變換2次,最後把最終結果輸出,其代碼可以為:
my_dna = "ACTGATCGATTACGTATAGTATTTGCTATCATACATATATATCGATGCGTTCAT"sequence1 = my_dna.replace('A', 'H')sequence2 = sequence1.replace('T', 'J')sequence3 = sequence2.replace('C', 'K')sequence4 = sequence3.replace('G', 'L')sequence5 = sequence4.replace('H', 'T')sequence6 = sequence5.replace('J', 'A')sequence7 = sequence6.replace('K', 'G')sequence8 = sequence7.replace('L', 'C')print(sequence8)其結果為:
利用upper()輸出大寫結果TGACTAGCTAATGCATATCATAAACGATAGTATGTATATATAGCTACGCAAGTA
至此得到了我們想要的結果,但這種方法顯然是有些復雜了,我們可以利用字符的大小寫來完成我們的工作,也就是利用小寫字母為臨時變量,最終利用upper()輸出大寫的結果就行了,其代碼和結果如下:
my_dna = "ACTGATCGATTACGTATAGTATTTGCTATCATACATATATATCGATGCGTTCAT"sequence1 = my_dna.replace('A', 't')print(sequence1)sequence2 = sequence1.replace('T', 'a')print(sequence2)sequence3 = sequence2.replace('C', 'g')print(sequence3)sequence4 = sequence3.replace('G', 'c')print(sequence4)print(sequence4.upper())其結果為:
tCTGtTCGtTTtCGTtTtGTtTTTGCTtTCtTtCtTtTtTtTCGtTGCGTTCtT
tCaGtaCGtaatCGatatGataaaGCataCtatCtatatataCGtaGCGaaCta
tgaGtagGtaatgGatatGataaaGgatagtatgtatatatagGtaGgGaagta
tgactagctaatgcatatcataaacgatagtatgtatatatagctacgcaagta
TGACTAGCTAATGCATATCATAAACGATAGTATGTATATATAGCTACGCAAGTA
至此我們的互補DNA序列得到了,也許有更好更簡潔的代碼。
結尾雖然這是個小小的計算程序,但對於初學者的我來說每一次對原代碼的升級改造,哪怕是讀懂後的注釋都感覺是一次進步提升,總之代碼雖小,動手最重要!希望更多學習Python的愛好者不要像我一樣眼高手低,學習編程就是要,思考,敲碼,思考,敲碼,敲碼,再敲碼,更多關於python求DNA模板互補序列的資料請關注軟件開發網其它相關文章!