Resource download address :https://download.csdn.net/download/sheziqiong/85836603
Resource download address :https://download.csdn.net/download/sheziqiong/85836603
Topic selection : Design and implement a text-based content / Automatic text classification method of emotion
Specific goals : Implement a classifier , Complete the simple binary classification of microblog text , It is divided into the front 、 negative .
Microblog text is different from official text , As a text in the online community , It is non-standard 、 Popularity 、 Symbol hybridity, etc , The following four points are specifically summarized :
2、4 Bring convenience to processing , In particular, textual emoticons can increase the weight of emotional words ; and 1、3 It's a challenge , The data volume shall be as large as possible , Cover more language phenomena .
In the interim report , Because of the existence of the text that has nothing to do with emotional expression in the sentence , The method of using classification directly is not applicable to long text , It needs to be filtered , And the traditional classification method ignores the semantic relationship between words , Make the scale of training set larger , Without a large microblog corpus, it is difficult to achieve good results .
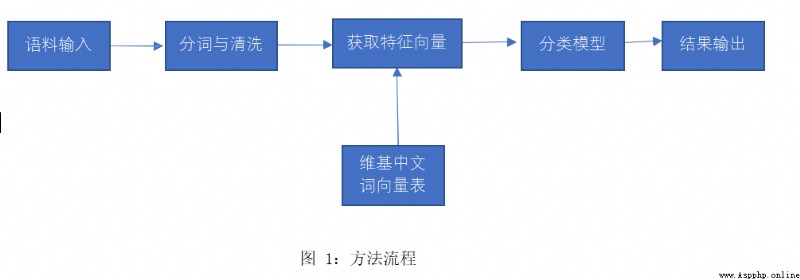
therefore , This paper considers the combination of word vectors and traditional classification methods , We can train the word vector table on a large-scale corpus , Then the vector of the whole text is obtained by averaging the word vector in the microblog text , Use vector as input to classify . meanwhile , When input no longer requires complete text , Filtering unwanted text becomes possible , Delete the conjunction 、 Prepositions do not affect the key information in the sentence . The word vector model takes into account the semantic connection , It is also consistent with the fact that emotion is essentially semantic ; The training speed of traditional classification method is faster than that of deep learning method , Consume less computing resources , There is no absolute difference in the effect , Therefore, it is suitable to run on a personal computer .
Wikipedia Chinese corpus ( ): Used for training word vector table
The second CCF Natural language processing and Chinese Computing Conference Chinese microblog emotion analysis sample data : The microblog corpus of this project comes from the Chinese stop words list published by the Chinese naturallanguageprocessing open platform of the Institute of computing, Chinese Academy of Sciences StopWord.txt: Used to filter useless text
First, the word vector table is obtained from Wikipedia Chinese corpus , With the help of the module python Open source genism, It includes the method of training word vector for Wikipedia corpus .
Then we preprocess the microblog corpus , The sample data downloaded is not a simple positive and negative binary classification , Its classification includes :anger anger 、disgust Hate 、fear Fear 、happiness happy 、like like 、sadness sad 、surprise surprised 、none Neutral . I will anger anger 、disgust Hate 、fear Fear 、sadness Sadness is classified as negative ,happiness happy 、like Preferences are classified as positive , Finally, each 1029 The positive and negative balance of sentences , Name it neg.txt and pos.txt.
Word segmentation of positive and negative corpora , With the help of the module jieba( Stuttering participle ); Use the stoplist for text cleaning ; Finally, compare the word vector table and take the average value to obtain the feature vector of the sentence . The dimension of the eigenvector obtained is 400, To save computing resources 、 Speed up , Use PCA Analysis and mapping , Find out 100 Dimension can contain almost all the information , Therefore, the dimension is reduced to 100.
The training set and verification set are randomly divided into 95:5. The verification set has 102 sentence , Among them, the negative 48 sentence , positive 54 sentence .
Three classification models are used for comparative study , by SVM、BP neural network 、 Random forests . The models are trained on the training sets respectively , Call the model to validate on the validation set .
1. The evaluation index
surface 1: Confusion matrix
TP、TN Indicates the number of text that the classification result is consistent with the actual label ,FN、FP Indicates the number of text that the classification result is inconsistent with the actual label .
Accuracy rate :P=TP/(TP+FP)
Recall rate :R=TP/(TP+FN)
F1 value :F1=2P*R/(P+R)
2. experimental result
The test results on the verification set are shown in the following table :
surface 2: The verification results
3. Analysis of experimental results
Resource download address :https://download.csdn.net/download/sheziqiong/85836603
Resource download address :https://download.csdn.net/download/sheziqiong/85836603