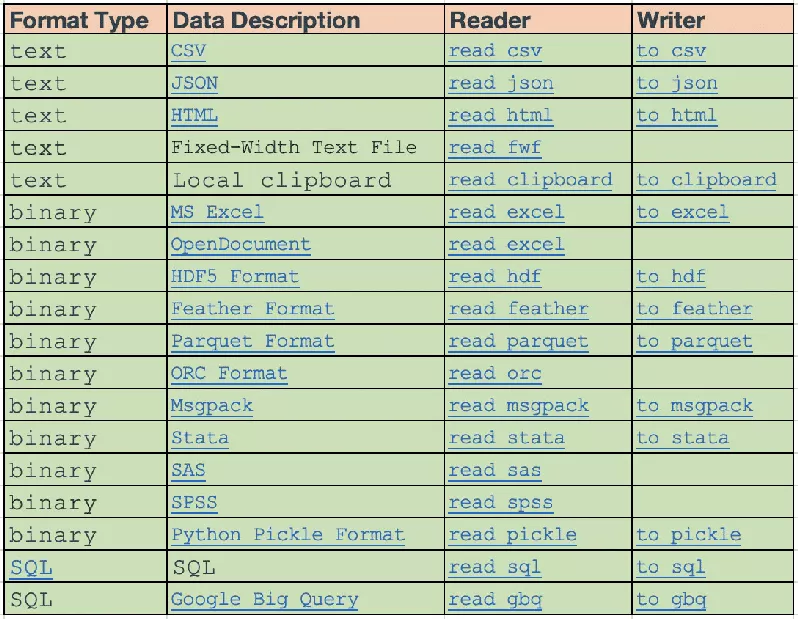
cache It is a technology widely used from the bottom to the top , Whether it's the front end or the back end , Programmers with some development experience should be familiar with caching . Cache refers to the memory that can exchange high-speed data , It precedes memory and CPU Exchange data , So the speed is very fast .
stay Python Development process , The results of some functions may be Call again and again , It wouldn't hurt if this function took less time .
however , If a function takes time 10 minute , Or send frequently rest request , Then the time consumption will increase nonlinearly .
that , For what many developers complain about Python, Whether it can improve its development efficiency through caching ?
The answer is yes !

This article will introduce how to use cache technology , Realization 1 Line code Promotion Python Execution speed .
Different programming languages , It will be different The cache strategy of , for example , adopt Hash map 、 Priority queue And so on . therefore , Different programming languages , There is a big difference in caching solutions , It may take a few minutes , It may also take a few hours .
however , stay Python in , Standard Toolkit functools A method named LRU(Least Recently Used) The cache strategy of , You can pass in parameters , To set how many recent calculation results are cached , If the passed parameter is None, Then infinite cache .
Now? , To make it easier for everyone to understand , Let me give you an example ,
import time as tt
def func():
num = 0
for i in range(10):
num += i
return num
def main():
return func() + func() + func() + func() + func() + func() + func()
t1 = tt.time()
main()
print("Time taken: {}".format(tt.time() - t1))
# 9.05990e-6 In this example , Repeatedly called func function , The total time is 0.009 second .
below , adopt functools Under tool kit LRU Cache run again ,
import time as tt
import functools
@functools.lru_cache(maxsize=5)
def func():
num = 0
for i in range(10):
num += i
return num
def main():
return func() + func() + func() + func() + func() + func() + func()
t1 = tt.time()
main()
print("Time taken: {}".format(tt.time() - t1))
# 4.768371e-06By comparing the data , It was found that the running time was reduced by nearly 50%.
Calling lru_cache when , You need to configure a maxsize Parameters of , It represents the result of the most recent function calculation , If the parameter is none Do not cache .
By contrast , You will find that the time to use the caching mechanism will vary greatly , This is because , Call the function repeatedly , It needs to be repeated The calculation process , And using cache , We just need to do Read and write quickly , There is no need to repeat the calculation process , This will save most of the time .
however , Because the previous calculation process is relatively simple , Only simple Addition operation , The intuitive feeling of time-consuming is not very strong .
Then there is another Fibonacci sequence Compare the examples of .
Many students should be familiar with Fibonacci sequence , A very typical recursion problem , It also appears frequently in textbooks .
Because it recursively calculates the process , The results of the previous calculation will also be used , Therefore, it will involve more repeated calculations , Let's take a look at the time-consuming situation of normal calculation .
import time as tt
def fib(n):
if n <= 1:
return n
return fib(n-1) + fib(n-2)
t1 = tt.time()
fib(30)
print("Time taken: {}".format(tt.time() - t1))
# 0.2073 below , Using LRU Accelerate it , Take a look at the effect ,
import time as tt
import functools
@functools.lru_cache(maxsize=5)
def fib(n):
if n <= 1:
return n
return fib(n-1) + fib(n-2)
t1 = tt.time()
fib(30)
print("Time taken: {}".format(tt.time() - t1))
# 1.811981e-050.2073 second contrast 2.0981e-5 second There's a difference 4 An order of magnitude , This gives people an intuitive feeling should be very strong .
In the process of involving some simple operations , Even double counting is harmless . however , If it involves a lot of data computing or time-consuming computing such as network requests , Using caching , It only needs 1 Lines of code can save considerable time . It saves time than double counting , It is also simpler than defining extra variables .
【python Study 】
learn Python The partners , Welcome to join the new exchange 【 Junyang 】:1020465983
Discuss programming knowledge together , Become a great God , There are also software installation packages in the group , Practical cases 、 Learning materials