pandas庫是python中幾乎最長使用的庫,其功能非常多。這裡只記錄下pandas對Excel文件的簡單操作;
Pandas是xlwt,xlrd庫的封裝庫,擁有更全面的操作對象,csv,excel,dataframe等等。在xlwt等讀寫庫的基礎上實現一個庫操作不同格式的文件。所以pandas依賴處理Excel的xlrd模塊;
簡單來說:pandas是庫的封裝庫,功能更強大
推薦使用pip安裝:pip是一個包管理工具
pip install pandas
導入pandas
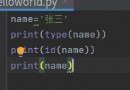
import pandas as pd
pandas中最重要的類型DataFrame的介紹:
DataFrame 是 Pandas 中的一種抽象數據對象(表格類型),Excel 中的數據都可以轉換為 DataFrame 對象。
DataFrame 和 Excel 的屬性
DataFrame sheet 頁
Series 列
Index 行號
row 行
NaN 空單元格
簡單讀數據
1、讀取文件,從第一行開始讀,讀取第一個sheet
data = pd.read_excel(‘urpan.xlsx’,header=0)
讀文件時傳遞參數介紹:
io:待讀取數據的文件 sheet_name: 指定讀取該excel中具體哪個表的數據,默認為0,即為第一個表。如果傳入1,則為第2個表;可指定傳入表名,如"Sheet1"; 也可傳入多個表,如[0,‘Sheet3’],傳入第一個表和名為’Sheet3’的表。 header: 指定作為列名的行,默認0,即取第一行的值為列名。數據為列名行以下的數據;若數據不含列名,則設定 header = None。 names: 默認為None,要使用的列名列表,如不包含標題行,應顯示傳遞header=None index_col: 指定某一列作為,為索引列 usecols: 讀取固定的列,usecols=‘A:C, F’,讀取A到C,和F列:#讀取文件,從第一行開始讀,讀取第一個sheetdata = pd.read_excel('H:/urpan.xlsx',header=0)print(data.head(3))print(data['year'])print(data.index) # 查看索引RangeIndex(start=0, stop=26, step=1)print(data.values) # 查看數值(print(data.shape) # 查看行數、列數 (26, 6)print(data.head( 5 )) # 查看前5行print(data.tail( 3 )) # 查看後3行寫文件簡單入門
def write():
‘’’’’’
data = {‘x’:[1,2,3],‘y’:[4,5,6]}
#轉換成dataFrame
df = pd.DataFrame(data)
#生成文件
df.to_excel(‘H:/df.xlsx’,sheet_name=“df”,index=True)
write()