Python基礎語法入門篇(一)
字符串的常見操作包括:
獲取長度:len len函數可以獲取字符串的長度。
查找內容:find 查找指定內容在字符串中是否存在,如果存在就返回該內容在字符串中第一次出現的開始位置索引值(從0開始計算),如果不存在,則返回-1.
判斷:startswith,endswith 判斷字符串是不是以誰誰誰開頭/結尾
計算出現次數:count 返回 str在start和end之間 ,在字符串中出現的次數
替換內容:replace 替換字符串中指定的內容,如果指定次數count,則替換不會超過count次。
切割字符串:split 通過參數的內容切割字符串
修改大小寫:upper,lower 將字符串轉為大寫或小寫
空格處理:strip 去空格
字符串拼接:join 字符串拼接
str = "a"
print(str.join('hello'))
#haealalao
#重點解釋一下join,會把指定字符串添加到字符串的每個字符的中間(第一個字符和最後一個字符不加)。一般用的不多
列表的增刪改查
添加元素
添加元素有一下幾個方法:
append 在末尾添加元素
insert 在指定位置插入元素
extend 合並兩個列表
append
append會把新元素添加到列表末尾
name_list = ['張三', '李四']
name_list.append('王五')
print(name_list)
#['張三', '李四', '王五']
insert
insert(index, object) 在指定位置index前插入元素object
name_list = ['張三', '李四']
name_list.insert(1, '小明')
print(name_list)
#['張三', '小明', '李四']
extend
通過extend可以將另一個列表中的元素逐一添加到列表中
name_list = ['張三', '李四']
name_list2 = ['小麗', '小王']
name_list.extend(name_list2)
print(name_list)
#['張三', '李四', '小麗', '小王']
修改元素
我們是通過指定下標來訪問列表元素,因此修改元素的時候,為指定的列表下標賦值即可。
name_list = ['張三', '李四']
print("修改前:%s" % name_list)
name_list[1] = '小麗'
print("修改後:%s" % name_list)
#修改前:['張三', '李四']
#修改後:['張三', '小麗']
查找元素
所謂的查找,就是看看指定的元素是否存在,主要包含一下幾個方法:
in 和 not inpython中查找的常用方法為:
in(存在),如果存在那麼結果為true,否則為falsenot in(不存在),如果不存在那麼結果為true,否則falsename_list = ['張三', '李四']
if '王五' in name_list:
print('存在')
else:
print('不存在')
#不存在
not類似,只不過取反
刪除元素
列表元素的常用刪除方法有:
del:根據下標進行刪除
pop:刪除最後一個元素
remove:根據元素的值進行刪除
del
name_list = ['張三', '李四', '小麗']
del name_list[1]
print(name_list)
#['張三', '小麗']
pop
name_list = ['張三', '李四', '小麗']
name_list.pop()
print(name_list)
#['張三', '李四']
remove
name_list = ['張三', '李四', '小麗']
name_list.remove('張三')
print(name_list)
#['李四', '小麗']
Python的元組與列表類似,不同之處在於元組的元素不能修改。元組使用小括號,列表使用方括號。
tuple1 = (1, 2, 3)
print(tuple1[1]) #2
python中不允許修改元組的數據,包括不能刪除其中的元素。
定義只有一個元素的元組,需要在唯一的元素後寫一個逗號
tuple1 = (1)
print(type(tuple1)) #int
tuple2 = (1,)
print(type(tuple2)) #tuple
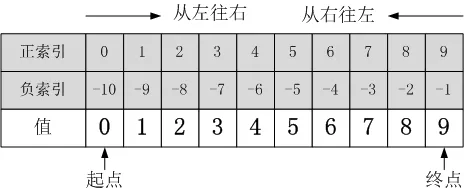
切片是指對操作的對象截取其中一部分的操作。字符串、列表、元組都支持切片操作。
切片的語法:[起始:結束:步長],也可以簡化使用 [起始:結束]
注意:選取的區間從"起始"位開始,到"結束"位的前一位結束(不包含結束位本身),步長表示選取間隔。
# 索引是通過下標取某一個元素
# 切片是通過下標去某一段元素
s = 'Hello World!'
print(s)
print(s[4]) # o 字符串裡的第4個元素
print(s[3:7]) # lo W 包含下標 3,不含下標 7
print(s[1:]) # ello World! 從下標為1開始,取出 後面所有的元素(沒有結束位)
print(s[:4]) # Hell 從起始位置開始,取到 下標為4的前一個元素(不包括結束位本身)
print(s[1:5:2]) # el 從下標為1開始,取到下標為5的前一個元素,步長為2(不包括結束位本身)
除了使用key查找數據,還可以使用get來獲取數據
person = {
'name': '張三', 'age': 18}
# 不可以通過 .屬性,獲取值
print(person['name'])
# print(person['email']) # 獲取不存在的key,會發生異常
print(person.get('name'))
print(person.get('email')) # 獲取不存在的key,會獲取到None值,不會出現異常
print(person.get('email', '[email protected]')) # 獲取不存在的key, 可以提供一個默認值。
字典的每個元素中的數據是可以修改的,只要通過key找到,即可修改
person = {
'name': '張三', 'age': 18}
person['name'] = '小麗'
print('修改後的值是:%s' % person) #修改後的值是:{'name': '小麗', 'age': 18}
如果在使用 變量名[‘鍵’] = 數據 時,這個“鍵”在字典中,不存在,那麼就會新增這個元素
person = {
'name': '張三', 'age': 18}
person['email'] = '[email protected]'
print('添加後的值是:%s' % person) #添加後的值是:{'name': '張三', 'age': 18, 'email': '[email protected]'}
對字典進行刪除操作,有一下幾種:
del
clear()
del刪除指定的元素
person = {
'name': '張三', 'age': 18}
del person['age']
print(person) #{'name': '張三'}
del刪除整個字典
person = {
'name': '張三', 'age': 18}
del person
print(person) #報錯:NameError: name 'person' is not defined
clear清空整個字典,但保留字典的結構
person = {
'name': '張三', 'age': 18}
person.clear()
print(person) #{}
遍歷字典的key(鍵)
person = {
'name': '張三', 'age': 18, 'email': '[email protected]'}
for s in person.keys():
print(s)
#name
#age
#email
遍歷字典的value(值)
person = {
'name': '張三', 'age': 18, 'email': '[email protected]'}
for s in person.values():
print(s)
#張三
#18
#[email protected]
遍歷字典的項(元素)
person = {
'name': '張三', 'age': 18, 'email': '[email protected]'}
for i in person.items():
print(i)
#('name', '張三')
#('age', 18)
#('email', '[email protected]')
遍歷字典的key-value(鍵值對)
person = {
'name': '張三', 'age': 18, 'email': '[email protected]'}
for k, v in person.items():
print('key是:%s,value是:%s' % (k, v))
#key是:name,value是:張三
#key是:age,value是:18
#key是:email,value是:[email protected]
定義函數的格式如下:
def 函數名():
代碼
定義了函數之後,就相當於有了一個具有某些功能的代碼,想要讓這些代碼能夠執行,需要調用它
調用函數很簡單的,通過 函數名() 即可完成調用
示例:
#定義函數
def f1():
print('hello ')
print('world')
f1() #定義完函數後,函數是不會自動執行的,需要調用它才可以
結果:
hello
world
函數定義好以後,函數體裡的代碼並不會執行,如果想要執行函數體裡的內容,需要手動的調用函數。
每次調用函數時,函數都會從頭開始執行,當這個函數中的代碼執行完畢後,意味著調用結束了。
為了讓一個函數更通用,例如想讓它計算哪兩個數的和,就讓它計算哪兩個數的和,在定義函數的時候可以讓函數接 收數據,就解決了這個問題,這就是函數的參數
定義、調用帶有參數的函數來計算任意兩個數字之和:
def sum(a, b):
print('a的值是:%s,b的值是:%s,計算和為:%s' % (a, b, a + b))
sum(9, 1) # 位置參數
sum(b = 1,a = 9) # 關鍵字參數
結果:
a的值是:9,b的值是:1,計算和為:10
a的值是:9,b的值是:1,計算和為:10
注意點:
在定義函數的時候,小括號裡寫等待賦值的變量名
在調用函數的時候,小括號裡寫真正要進行運算的數據
調用函數時參數的順序
定義時小括號中的參數,用來接收參數用的,稱為 “形參” (形式參數)
調用時小括號中的參數,用來傳遞給函數用的,稱為 “實參” (實際參數)
所謂“返回值”,就是程序中函數完成一件事情後,最後給調用者的結果
帶有返回值的函數
想要在函數中把結果返回給調用者,需要在函數中使用return
示例:
def sum(a, b):
return a + b
#使用一個變量接受函數的返回值
a = sum(9, 1)
print(a) #10
1)全局變量:如果一個變量定義在函數外部,既能在一個函數中使用,也能在其他的函數中使用,這樣的變量就是全局變量
2)局部變量,就是在函數內部定義的變量,其作用范圍是這個函數內部,即只能在這個函數中使用,在函數的外部是不能使用的
局部變量:
def f1():
#定義局部變量a
a = 1
print(a)
f1()
全局變量:
#定義全局變量a
a = 1
def f1():
print(a)
f1()
注意:從上邊看我們在程序中所有的變量都定義為全局變量就可以替代局部變量,實際上不可以這麼做。在滿足條件的情況下,要使用作用域最小的那個變量。就好像50碼的鞋,誰都能穿,但是我們只穿適合自己大小的鞋。
打開文件/創建文件
在python,使用open函數,可以打開一個已經存在的文件,或者創建一個新文件。
open(文件路徑,訪問模式)
#這裡使用相對路徑,就是在當前目錄下
f = open("test.txt", 'w')
文件路徑
絕對路徑:指的是絕對位置,完整地描述了目標的所在地,所有目錄層級關系是一目了然的。
相對路徑:是從當前文件所在的文件夾開始的路徑。
test.txt ,是在當前文件夾查找 test.txt 文件
./test.txt ,也是在當前文件夾裡查找 test.txt 文件, ./ 表示的是當前文件夾。
…/test.txt ,從當前文件夾的上一級文件夾裡查找 test.txt 文件。 …/ 表示的是上一級文件夾
demo/test.txt ,在當前文件夾裡查找 demo 這個文件夾,並在這個文件夾裡查找 test.txt 文件。
關閉文件:
#這裡需要手動創建file文件夾,變量通常命名f或fp
f = open("file/test.txt", 'w')
# 關閉這個文件
f.close()
訪問模式:
寫數據(write)
使用write()可以完成向文件寫入數據
# w模式如果文件存在,會先清空文件內容,然後再寫。如果模式變為a,就會執行追加操作
f = open("test.txt", 'w')
f.write('hello world\n' * 3)
f.close()
讀數據(read)
使用read(num)可以從文件中讀取數據,num表示要從文件中讀取的數據的長度(單位是字節),如果沒有傳入
num,那麼就表示讀取文件中所有的數據
f = open("test.txt", 'r')
content = f.read(2) # 最多讀取2個數據
print(content)
content = f.read() # 從上次讀取的位置繼續讀取剩下的所有的數據
print(content)
f.close()
注意:
"r",那麼可以省略 open('test.txt') 讀數據(readline)
readline只用來讀取一行數據。
f = open("test.txt")
content = f.readline()
print(content)
content = f.readline()
print(content)
f.close()
讀數據(readlines)
readlines可以按照行的方式把整個文件中的內容進行一次性讀取,並且返回的是一個列表,其中每一行為列表的
一個元素。
f = open("test.txt")
content = f.readlines()
print(content)
f.close()
通過文件操作,我們可以將字符串寫入到一個本地文件。但是,如果是一個對象(例如列表、字典、元組等),就無
法直接寫入到一個文件裡,需要對這個對象進行序列化,然後才能寫入到文件裡。
通過文件操作,我們可以將字符串寫入到一個本地文件。但是,如果是一個對象(例如列表、字典、元組等),就無
法直接寫入到一個文件裡,需要對這個對象進行序列化,然後才能寫入到文件裡。
設計一套協議,按照某種規則,把內存中的數據轉換為字節序列,保存到文件,這就是序列化,反之,從文件的字
節序列恢復到內存中,就是反序列化。
對象—》字節序列 就是 序列化
字節序列–》對象 就是 反序列化
Python中提供了JSON這個模塊用來實現數據的序列化和反序列化。
JSON模塊
JSON(JavaScriptObjectNotation, JS對象簡譜)是一種輕量級的數據交換標准。JSON的本質是字符串。
使用JSON實現序列化
JSON提供了dump和dumps方法,將一個對象進行序列化。
dumps方法的作用是把對象轉換成為字符串,它本身不具備將數據寫入到文件的功能。
f = open("test.txt", 'w')
person = ['zs', 'ls']
# 導入json模塊到該文件中
import json
# 序列化,將python對象變成json字符串
names = json.dumps(person)
f.write(names)
f.close()
dump方法可以在將對象轉換成為字符串的同時,指定一個文件對象,把轉換後的字符串寫入到這個文件裡
f = open("test.txt", 'w')
person = ['zs', 'ls']
# 導入json模塊到該文件中
import json
names = json.dump(person, f)
f.close()
使用JSON實現反序列化
使用loads和load方法,可以將一個JSON字符串反序列化成為一個Python對象。
loads方法需要一個字符串參數,用來將一個字符串加載成為Python對象。
f = open("test.txt", 'r')
# 導入json模塊到該文件中
import json
# 調用loads方法,將文件中的字符串轉換成python對象
names = json.loads(f.read())
print(names) # ['zs', 'ls']
print(type(names)) # <class 'list'>
f.close()
load方法可以傳入一個文件對象,用來將一個文件對象裡的數據加載成為Python對象。
f = open("test.txt", 'r')
# 導入json模塊到該文件中
import json
names = json.load(f)
print(names)
print(type(names))
f.close()
程序在運行過程中,由於我們的編碼不規范,或者其他原因一些客觀原因,導致我們的程序無法繼續運行,此時,
程序就會出現異常。如果我們不對異常進行處理,程序可能會由於異常直接中斷掉。為了保證程序的健壯性,我們
在程序設計裡提出了異常處理這個概念。
在讀取一個文件時,如果這個文件不存在,則會報出 FileNotFoundError 錯誤。
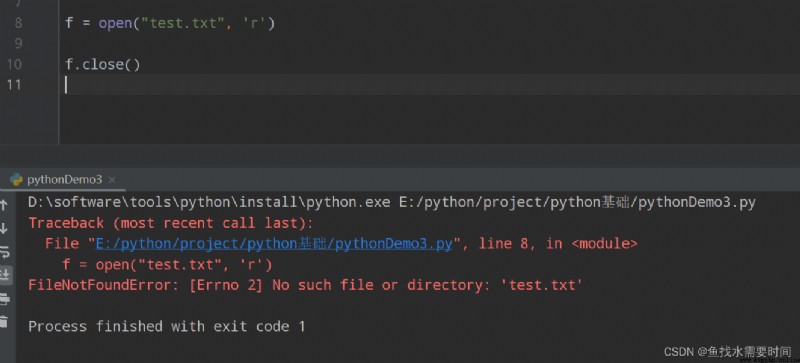
try...except語句可以對代碼運行過程中可能出現的異常進行處理。 語法結構:
try:
可能會出現異常的代碼塊
except 異常的類型:
出現異常以後的處理語句
示例:
try:
f = open("test.txt", 'r')
print(f.read())
except FileNotFoundError:
print('文件沒有找到,請檢查文件名稱是否正確')
Python基礎語法入門篇(一)