點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達1 前言
正則表達式是對字符串(包括普通字符(例如,a 到 z 之間的字母)和特殊字符(稱為“元字符”))操作的一種邏輯公式,就是用事先定義好的一些特定字符、及這些特定字符的組合,組成一個“規則字符串”,這個“規則字符串”用來表達對字符串的一種過濾邏輯。正則表達式是一種文本模式,該模式描述在搜索文本時要匹配的一個或多個字符串。
上面都是官方的說明,博主自己的理解是(僅供參考):通過事先規定好一些特殊字符的匹配規則,然後利用這些字符進行組合來匹配各種復雜的字符串場景。比如現在的爬蟲和數據分析,字符串校驗等等都需要用到正則表達式來處理數據。
python的正則表達式則是re模塊了:
re 模塊使 Python 語言擁有全部的正則表達式功能。
re 模塊也提供了與這些方法功能完全一致的函數,這些函數使用一個模式字符串做為它們的第一個參數。
2 基本語法
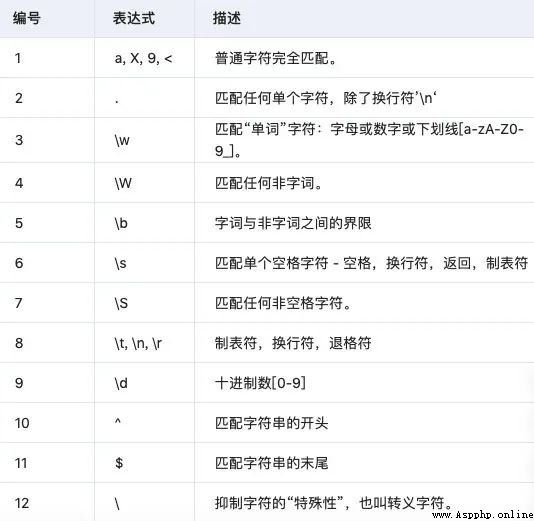
2.1 match函數
只從字符串的最開始與pattern進行匹配,下面是函數的語法 :
re.match(pattern, string, flags = 0)這裡是參數的描述 :
pattern - 這是要匹配的正則表達式。
string - 這是字符串,它將被搜索用於匹配字符串開頭的模式。
flags - 可以使用按位OR(|)指定不同的標志。這些是修飾符,如下表所列。
re.match 函數在成功時返回匹配對象,失敗時返回None。使用match(num)或groups()函數匹配對象來獲取匹配的表達式。
示例
#未從初始位置匹配,會返回None
import re
line = 'i can speak good english'
matchObj = re.match(r'\s(\w*)\s(\w*).*',line)
if matchObj:
print('matchObj.group() :',matchObj.group())
print('matchObj.group() :',matchObj.group(1))
print('matchObj.group() :',matchObj.group(2))
print('matchObj.group() :',matchObj.group(3))
else:
print('no match!')
#從初始位置開始匹配
import re
line = 'i can speak good english'
matchObj = re.match(r'(i)\s(\w*)\s(\w*).*',line)
if matchObj:
print('matchObj.group() :',matchObj.group())
print('matchObj.group() :',matchObj.group(1))
print('matchObj.group() :',matchObj.group(2))
print('matchObj.group() :',matchObj.group(3))
else:
print('no match!')
2.2 search 函數
與match()工作的方式一樣,但是search()不是從最開始匹配的,而是從任意位置查找第一次匹配的內容。下面是這個函數的語法 :
re.match(pattern, string, flags = 0)這裡是參數的描述 :
pattern - 這是要匹配的正則表達式。
string - 這是字符串,它將被搜索用於匹配字符串開頭的模式。
flags - 可以使用按位OR(|)指定不同的標志。這些是修飾符,如下表所列。
re.search函數在成功時返回匹配對象,否則返回None。使用match對象的group(num)或groups()函數來獲取匹配的表達式。

示例
import re
line = 'i can speak good english'
matchObj = re.search('(.*) (.*?) (.*)',line)
if matchObj:
print('matchObj.group() :',matchObj.group())
print('matchObj.group() :',matchObj.group(1))
print('matchObj.group() :',matchObj.group(2))
print('matchObj.group() :',matchObj.group(3))
else:
print('no match!')2.3 sub 函數
使用正則表達式re模塊中的最重要的之一是sub。
re.sub(pattern, repl, string, max=0)此方法使用repl替換所有出現在RE模式的字符串,替換所有出現,除非提供max。此方法返回修改的字符串。
示例
import re
line = 'i can speak good english'
speak = re.sub(r'can','not',line)
print(speak)
speak1 = re.sub(r'\s','',line) #替換所有空格
print(speak1)3 特殊類語法
3.1 字符類
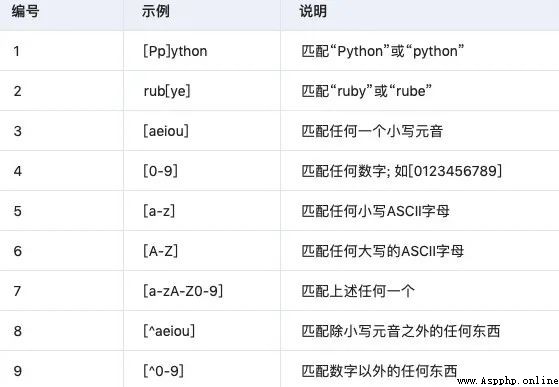
3.2 特殊字符類
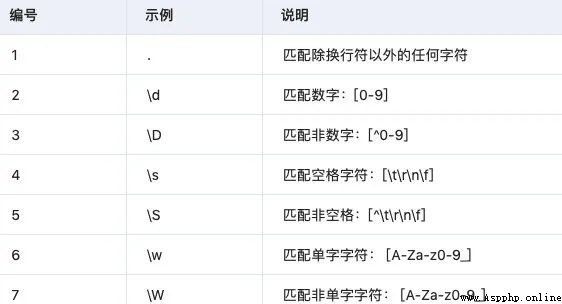
3.3 重復匹配
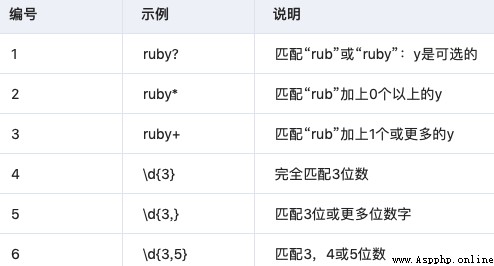
3.4 非貪婪重復
這匹配最小的重復次數:
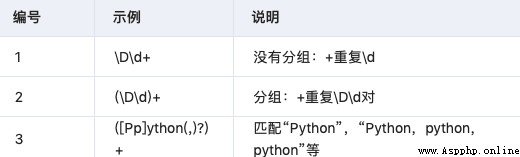
3.5 圓括號分組
3.6 反向引用
與以前匹配的組再次匹配
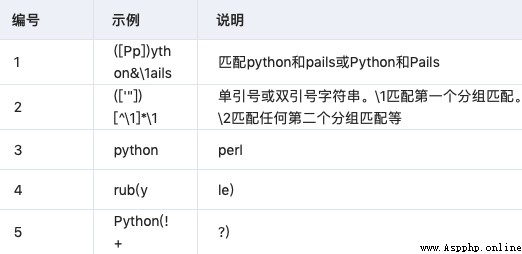
3.7 錨點
需要指定匹配位置。
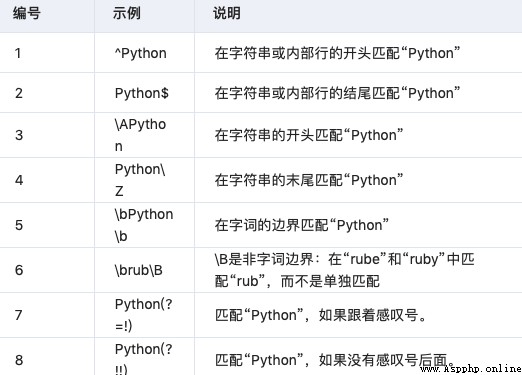
3.8 帶括號的特殊語法
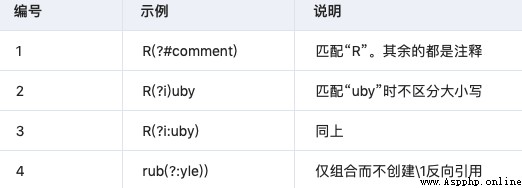
好消息!
小白學視覺知識星球
開始面向外開放啦

下載1:OpenCV-Contrib擴展模塊中文版教程
在「小白學視覺」公眾號後台回復:擴展模塊中文教程,即可下載全網第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內容。
下載2:Python視覺實戰項目52講
在「小白學視覺」公眾號後台回復:Python視覺實戰項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數、添加眼線、車牌識別、字符識別、情緒檢測、文本內容提取、面部識別等31個視覺實戰項目,助力快速學校計算機視覺。
下載3:OpenCV實戰項目20講
在「小白學視覺」公眾號後台回復:OpenCV實戰項目20講,即可下載含有20個基於OpenCV實現20個實戰項目,實現OpenCV學習進階。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫學影像、GAN、算法競賽等微信群(以後會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功後會根據研究方向邀請進入相關微信群。請勿在群內發送廣告,否則會請出群,謝謝理解~