Catalog
1. Preface
2、 Solution
3、 Now start the code implementation
4、 The final summary :
I am Zhengyin Looking forward to your attention

Hello everyone I am a Walking on the front line of punishment every day Zhengyin
Today, I will teach you how to get the product information on Alibaba's list page, which contains , goods title, The main picture of the commodity needs to be saved xls file save I am a Zhengyin It's not easy to make a free attention
The first scheme given is :
2.1、 adopt wxPython The framework writes a visual interface ,
2.2、 Because Alibaba's anti climbing is quite serious , So I went straight through selenium Skip the anti pickpocketing mechanism by exceeding the user
2.3、 Write browser pool to facilitate multi-threaded crawling data
2.4、 Write data business logic
3.1 Start with a browser pool
from multiprocessing import Manager
from time import sleep
from tool.open_browser import open_browser
class DriverPool:
def __init__(self, max_nums,driver_path,ui,open_headless=0):
self.ui = ui
self.drivers = {}
self.manager = Manager()
self.queue = self.manager.Queue()
self.max_nums = max_nums
self.open_headless = open_headless
self.CreateDriver(driver_path)
def CreateDriver(self,driver_path):
'''
Initialize browser pool
:return
'''
for name in range(1, self.max_nums + 1):
name = f'driver_{name}'
d = open_browser(excute_path=driver_path,open_headless=self.open_headless)
d.ui = self.ui
self.drivers[name] = d
self.queue.put(name)
def getDriver(self):
'''
Get a browser
:return driver
'''
if self.queue.empty():
sleep(1)
return self.getDriver()
name = self.queue.get()
driver = self.drivers[name]
driver.pool_name_driver = name
return driver
def putDriver(self, name):
'''
Return a browser
:param name:
:return:
'''
self.queue.put(name)
def quit(self):
'''
Close the browser , Execute end operation
:return:
'''
if self.drivers:
for driver in self.drivers.values():
try:
driver.quit()
except:
pass
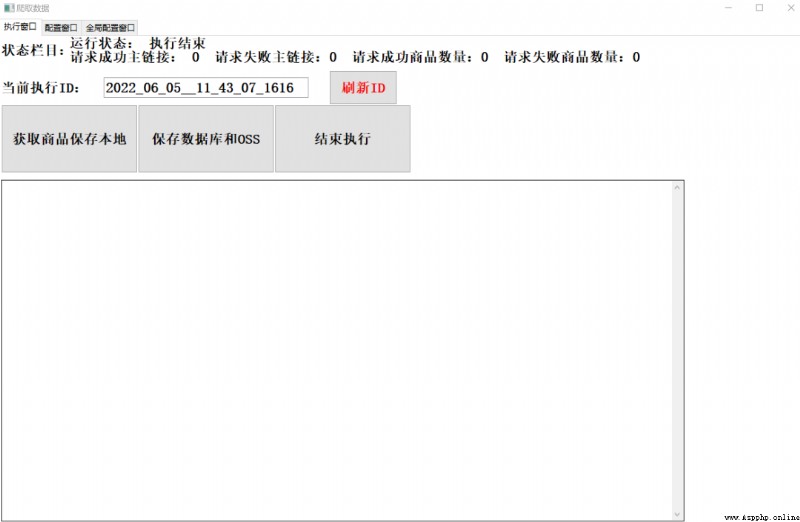
3.2 To write UI interface
def intUIRun(self):
'''
initialization UI main interface
:return:
'''
pannel = wx.Panel(self.panel_run)
pannel.Sizer = wx.BoxSizer(wx.VERTICAL)
self.text = wx.StaticText(pannel, -1, ' Status column :', size=(100, 40), pos=(0, 10))
self.text_input = wx.StaticText(pannel, -1, '', size=(900, 40), pos=(100, 0))
wx.StaticText(pannel, -1, ' Current implementation ID:', size=(100, 30), pos=(0, 65)).SetFont(self.font)
self.text_time = wx.TextCtrl(pannel, id=self.choices_id_ref, value=self.time_str, size=(300, 30), pos=(150, 60),
style=wx.TE_AUTO_URL | wx.TE_MULTILINE)
self.reflush_text_time = wx.Button(pannel, -1, ' Refresh ID', size=(100, 50), pos=(480, 50))
self.text_time.SetFont(self.font)
self.reflush_text_time.SetForegroundColour(wx.RED)
self.reflush_text_time.SetFont(self.font)
# self.text_time.SetForegroundColour(wx.RED)
self.text_input.SetBackgroundColour(wx.WHITE)
self.text_input.SetLabel(self.in_text)
self.text_input.SetFont(self.font)
self.text.SetFont(self.font)
wx.Button(pannel, self.get_product, ' Get the product and save it locally ', size=(200, 100), pos=(0, 100)).SetFont(self.font)
wx.Button(pannel, self.save_mysql, ' Save the database and OSS', size=(200, 100), pos=(200, 100)).SetFont(self.font)
wx.Button(pannel, self.end_process, ' End to perform ', size=(200, 100), pos=(400, 100)).SetFont(self.font)
self.log_text = wx.TextCtrl(pannel, size=(1000, 500), pos=(0, 210), style=wx.TE_MULTILINE | wx.TE_READONLY)
wx.LogTextCtrl(self.log_text)
self.Bind(wx.EVT_BUTTON, self.get_product_p, id=self.get_product)
self.Bind(wx.EVT_BUTTON, self.save_mysql_p, id=self.save_mysql)
self.Bind(wx.EVT_BUTTON, self.end_process_p, id=self.end_process)
self.text_time.Bind(wx.EVT_COMMAND_LEFT_CLICK, self.choices_id, id=self.choices_id_ref)
self.reflush_text_time.Bind(wx.EVT_BUTTON, self.reflush_time_evt)
self.panel_run.Sizer.Add(pannel, flag=wx.ALL | wx.EXPAND, proportion=1)
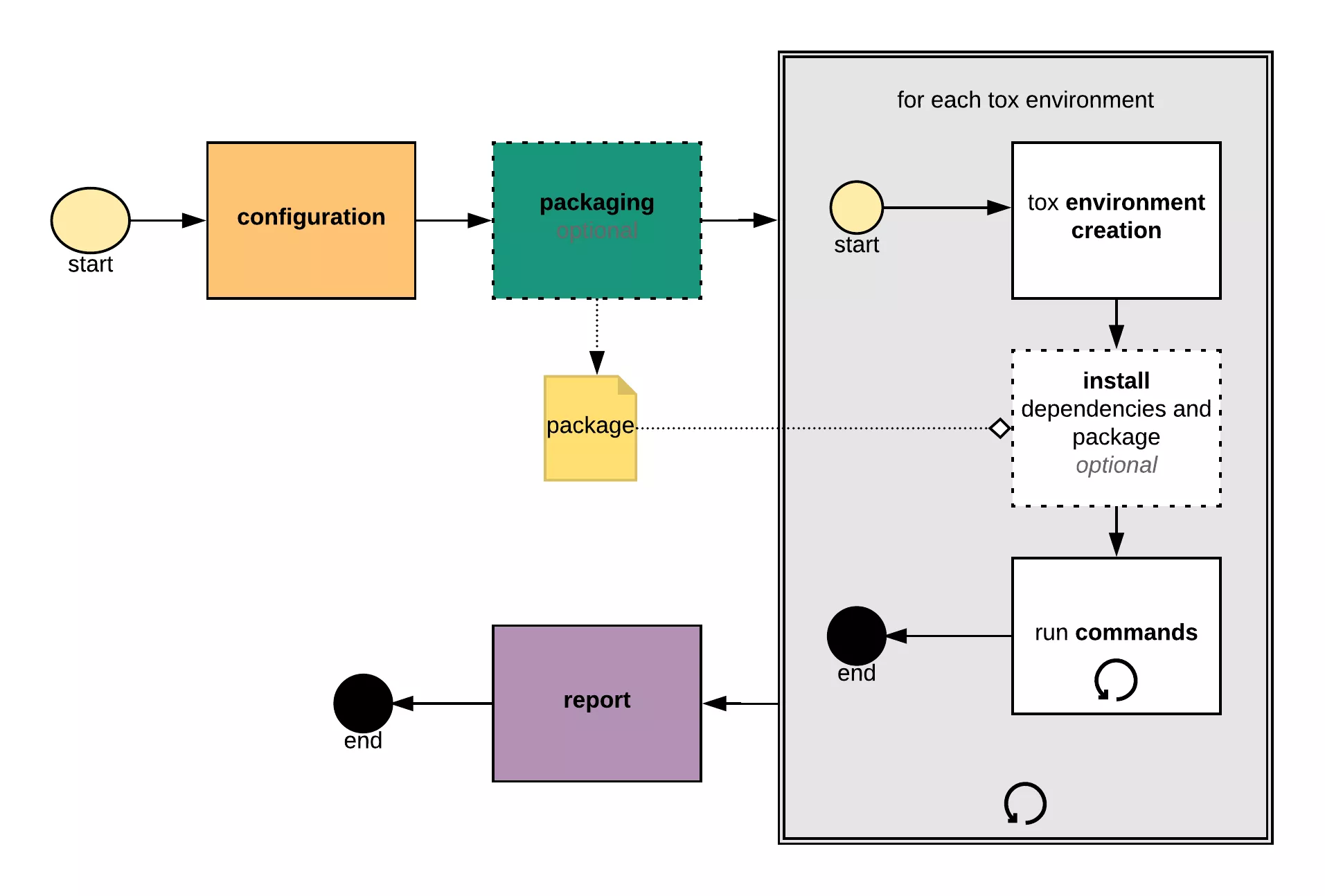
design sketch
3.3 Write business logic
Get product list page data
global _getMainProduct, goods_info
def _getMainProduct(data_url):
'''
Multi thread to get each page link
:param data_url:
:return:
'''
self, url, driver_pool = data_url
c = Common(driver_pool.getDriver())
goods_urls = []
try:
self.ui.print(f' Currently get the second {url} Page data ')
c.d.get(url)
c.wait_page_loaded(url)
if self.is_load_cache_cookies:
self.load_cookies(c.d)
c.d.get(url)
c.wait_page_loaded(url)
ele = c.find_element(By.CSS_SELECTOR, '[class="component-product-list"]')
goods_urls = ele.find_elements(By.CSS_SELECTOR, 'a[class="product-image"]')
goods_urls = [goods_url.get_attribute('href') for goods_url in goods_urls]
except SystemExit:
sys.exit(1)
except:
self.print(f' The requested page is out of range : {url} ERROR: {traceback.format_exc()}')
if c.find_element_true(By.CSS_SELECTOR, '[class="no-data common"]'):
return goods_urls
finally:
name = c.d.pool_name_driver
driver_pool.putDriver(name)
self.queue_print.put(f' Request completed :{url}')
return goods_urls
def getMainProduct_(self):
g_dict = globals()
urls = []
sum_l = self.pageNums[1] + 1
complate = 0
products = []
for i in range(self.pageNums[0], sum_l):
if self.ui.is_exit_process:
exit()
url = self.url.format(i)
urls.append([self, url, self.drive_pool])
if urls:
p = self.pool.map_async(_getMainProduct, urls)
while not p.ready():
if not self.queue_print.empty():
complate += 1
self.print(self.queue_print.get(), f' complete :{complate}/{sum_l - 1}')
products = p.get()
goods_info = set()
for xx in products:
for x in xx:
if x:
goods_info.add(x)
self.goods_info = goods_info
return goods_info
goods_info = getMainProduct_(self)
Get detail page data
global goods,Common,driver_pool,goods_url,sleep,re,By
def get_info_(self, data_info):
'''
Multi thread to get detail page data
:param self:
:param data_info:
:return:
'''
if self.ui.is_exit_process:
exit()
goods_url, driver_pool = data_info
c = Common(driver_pool.getDriver())
try:
c.d.get(goods_url)
sleep(3)
if self.is_load_cache_cookies:
self.load_cookies(c.d)
c.d.get(goods_url)
c.wait_page_loaded(goods_url)
for x in range(400, 18000, 200):
sleep(0.1)
c.d.execute_script(f'document.documentElement.scrollTop={x};')
is_all = c.find_element_true(By.CSS_SELECTOR, '[id="J-rich-text-description"]') # 'J-rich-text-description'
if not is_all:
self.print(f' Not found : {is_all}')
is_video = c.find_elements_true(By.CSS_SELECTOR, '[class="bc-video-player"]>video')
is_title = c.find_element_true(By.CSS_SELECTOR, '[class="module-pdp-title"]')
is_description = c.find_element_true(By.CSS_SELECTOR, '[name="description"]')
is_keywords = c.find_element_true(By.CSS_SELECTOR, '[name="keywords"]')
is_overview = c.find_element_true(By.CSS_SELECTOR, '[class="do-overview"]')
is_wz_goods_cat_id = c.find_element_true(By.CSS_SELECTOR, '[class="detail-subscribe"]')
wz_goods_cat_id = self.wz_goods_cat_id
# if is_wz_goods_cat_id:
# wz_goods_cat_id = is_wz_goods_cat_id.find_elements(By.CSS_SELECTOR, '[class="breadcrumb-item"]>a')[
# -1].get_attribute('href')
# wz_goods_cat_id = re.search(r'(\d+)', wz_goods_cat_id).group(1)
# goods_id = re.search(r'(\d+)\.html$', goods_url)
goods_id = re.search(r'(ssssss\d+)\.html$', goods_url)
goods = {
" Classification of goods ID": int(wz_goods_cat_id) if wz_goods_cat_id else 0,
" goods ID": goods_id.group(1) if goods_id else self.getMd5(f'{time.time()}')+' other ',
" Product links ": goods_url,
" describe ": c.find_element(By.CSS_SELECTOR, '[name="description"]').get_attribute(
'content') if is_description else '',
" title ": is_title.get_attribute('title') if is_title else '',
" keyword ": c.find_element(By.CSS_SELECTOR, '[name="keywords"]').get_attribute(
'content') if is_keywords else is_keywords,
" Video link ": c.find_element(By.CSS_SELECTOR, '[class="bc-video-player"]>video').get_attribute(
'src') if is_video else '',
" Main picture ": [],
" Goods details ": c.d.execute_script(
'''return document.querySelectorAll('[class="do-overview"]')[0].outerHTML;''') if is_overview else is_overview,
" Commodity Description ": '',
" Product description picture ": []
}
# Get product description pictures
goods_desc = getDescriptionFactory1(self, c, goods_url)
goods.update(goods_desc)
# Get the main picture
m_imgs = c.find_elements(By.CSS_SELECTOR, '[class="main-image-thumb-ul"]>li')
for m_img in m_imgs:
try:
img = m_img.find_element(By.CSS_SELECTOR, '[class="J-slider-cover-item"]').get_attribute('src')
s = re.search('(\d+x\d+)', img)
img2 = None
if s:
img2 = str(img).replace(s.group(1), '')
goods[' Main picture '].append(img)
if img2:
goods[' Main picture '].append(img2)
except:
pass
self.ui.status[' Quantity of goods successfully requested '] += 1
return goods
except:
traceback.print_exc()
self.print(f'=========================\n Link request error : {goods_url} \n {traceback.format_exc()}\n=========================')
self.error_page.append([goods_url, traceback.format_exc()])
self.ui.status[' Request failed item quantity '] += 1
finally:
name = c.d.pool_name_driver
driver_pool.putDriver(name)
self.queue_print.put(f' Request completed :{goods_url}')
goods = get_info_(self,data_info)
write in excel
def export_excel(self, results):
'''
write in excel Method
:param results:
:return:
'''
now_dir_str = self.now
now_file_str = time.strftime('%Y_%m_%d__%H_%M_%S', time.localtime())
img_path = os.path.join('data', 'xls', now_dir_str)
if not os.path.exists(img_path):
os.mkdir(img_path)
img_path = os.path.join('data', 'xls', now_dir_str, self.url_id)
if not os.path.exists(img_path):
os.mkdir(img_path)
if not os.path.exists(img_path):
os.mkdir(img_path)
img_path = os.path.join(img_path, f"{now_file_str}.xlsx")
workbook = xlsxwriter.Workbook(img_path)
sheet = workbook.add_worksheet(name=' Alibaba information ')
titles = list(results[0].keys())
for i, title in enumerate(titles):
sheet.write_string(0, i, title)
for row, result in enumerate(results):
row = row + 1
col = 0
for value in result.values():
sheet.write_string(row, col, str(value))
col += 1
workbook.close()
Because of universal selenium The browser operation is not as efficient as the interface request , So in the end, we used multithreading to improve the execution efficiency .