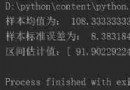
1、 Dynamic packet capture demo
2、json Data analysis
3、requests Use of modules
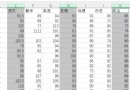
4、 preservation csv
Installation command :requests >>> pip install requests

Through developer tools for packet capture analysis , Analyze the data you want Where can I get
Analyze the data From the second page
Open developer tools
Click on the second page
Click the search button , Search for content
View the contents of the response data returned by the server
Use code to simulate the browser to send a request to obtain data

1. The import module
import requests # Data request module
import pprint # Format output module
import csv # Built-in module
import time
import re
def get_shop_info(html_url):
# url = 'https://www.meituan.com/xiuxianyule/193306807/'
headers = {
'Cookie': '_lxsdk_cuid=17e102d3914c8-000093bbbb0ed8-4303066-1fa400-17e102d3914c8; __mta=48537241.1640948906361.1640948906361.1640948906361.1; _hc.v=e83bebb5-d6ee-d90e-dd4b-4f2124f8f982.1640951715; ci=70; rvct=70; mt_c_token=2Tmbj8_Qihel3QR9oEXS4nEpnncAAAAABBEAAB9N2m2JXSE0N6xtRrgG6ikfQZQ3NBdwyQdV9vglW8XGMaIt38Lnu1_89Kzd0vMKEQ; iuuid=3C2110909379198F1809F560B5E33A58B83485173D8286ECD2C7F8AFFCC724B4; isid=2Tmbj8_Qihel3QR9oEXS4nEpnncAAAAABBEAAB9N2m2JXSE0N6xtRrgG6ikfQZQ3NBdwyQdV9vglW8XGMaIt38Lnu1_89Kzd0vMKEQ; logintype=normal; cityname=%E9%95%BF%E6%B2%99; _lxsdk=3C2110909379198F1809F560B5E33A58B83485173D8286ECD2C7F8AFFCC724B4; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; latlng=28.302546%2C112.868692; ci3=70; uuid=f7c4d3664ab34f13ad7f.1650110501.1.0.0; mtcdn=K; lt=9WbeLmhHHLhTVpnVu264fUCMYeIAAAAAQREAAKnrFL00wW5eC7mPjhHwIZwkUL11aa7lM7wOfgoO53f0uJpjKSRpO6LwCBDd9Fm-wA; u=266252179; n=qSP946594369; token2=9WbeLmhHHLhTVpnVu264fUCMYeIAAAAAQREAAKnrFL00wW5eC7mPjhHwIZwkUL11aa7lM7wOfgoO53f0uJpjKSRpO6LwCBDd9Fm-wA; unc=qSP946594369; firstTime=1650118043342; _lxsdk_s=18032a80c4c-4d4-d30-e8f%7C%7C129',
'Referer': 'https://chs.meituan.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
# print(response.text)
phone = re.findall('"phone":"(.*?)"', response.text)[0]
# \n It's not a newline , \n Just symbols \ The escape character is transferred
openTime = re.findall('"openTime":"(.*?)"', response.text)[0].replace('\\n', '')
address = re.findall('"address":"(.*?)"', response.text)[0]
shop_info = [phone, openTime, address]
return shop_info
# Save the file Create folder encoding='utf-8' Specified encoding If I use utf-8 What if you mess with the code
# w Will be covered , a Will not cover
f = open(' The ultimate version of the invincible man's Secret .csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
' Shop name ',
' Per capita consumption ',
' minimum consumption ',
' Business circle ',
' Store type ',
' score ',
' Telephone ',
' Business Hours ',
' Address ',
' latitude ',
' longitude ',
' Details page ',
])
csv_writer.writeheader() # Write header
# html_url = 'https://apimobile.meituan.com/group/v4/poi/pcsearch/70?uuid=f7c4d3664ab34f13ad7f.1650110501.1.0.0&userid=266252179&limit=32&offset=64&cateId=-1&q=%E4%BC%9A%E6%89%80&token=9WbeLmhHHLhTVpnVu264fUCMYeIAAAAAQREAAKnrFL00wW5eC7mPjhHwIZwkUL11aa7lM7wOfgoO53f0uJpjKSRpO6LwCBDd9Fm-wA'
1. Send a request , For the just analyzed url Address send request Turn the page to analyze the request url The law of address change
for page in range(0, 321, 32): # from 0 32 64 96 128 160 192 .... 320
time.sleep(1.5) # Delay waiting for 1.5S
url = 'https://apimobile.meituan.com/group/v4/poi/pcsearch/70'
# pycharm function Fast batch replacement , ctrl + R Select the target you want to replace , Use regular expressions for batch replacement
data = {
'uuid': 'f7c4d3664ab34f13ad7f.1650110501.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': page,
'cateId': '-1',
'q': ' The clubhouse ',
'token': '9WbeLmhHHLhTVpnVu264fUCMYeIAAAAAQREAAKnrFL00wW5eC7mPjhHwIZwkUL11aa7lM7wOfgoO53f0uJpjKSRpO6LwCBDd9Fm-wA',
}
# headers camouflage python Code coat
# User-Agent The user agent Basic identity information of browser .... The simplest means of anti climbing To prevent being identified as a crawler
# Referer Anti theft chain Tell the server that we request url Where does the address jump from
headers = {
'Referer': 'https://chs.meituan.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36'
}
response = requests.get(url=url, params=data, headers=headers)
# print(response) # <Response [403]> Status code Indicates no access rights Anti theft chain 200 The request is successful

2. get data response.text Get text data string data type response.json() Dictionary data type
# print(response.json())
# pprint.pprint(response.json()) # The teacher's version is python 3.8
searchResult = response.json()['data']['searchResult']
for index in searchResult: # Put the data in the list One by one
# pprint.pprint(index)
href = f'https://www.meituan.com/xiuxianyule/{index["id"]}/'
shop_info = get_shop_info(href)
title = index['title'] # Shop name
price = index['avgprice'] # Per capita consumption
lost_price = index['lowestprice'] # minimum consumption
area = index['areaname'] # Business circle
shop_type = index['backCateName'] # Store type
score = index['avgscore'] # score
latitude = index['latitude'] # latitude
longitude = index['longitude'] # longitude ctrl + D Copy quickly
# tab Collective indent
# shift + tab remove indent
dit = {
' Shop name ': title,
' Per capita consumption ': price,
' minimum consumption ': lost_price,
' Business circle ': area,
' Store type ': shop_type,
' score ': score,
' Telephone ': shop_info[0],
' Business Hours ': shop_info[1],
' Address ': shop_info[2],
' latitude ': latitude,
' longitude ': longitude,
' Details page ': href,
}
4. Save the data
csv_writer.writerow(dit)
print(dit)
Okay , My article ends here !
There are more suggestions or questions to comment on or send me a private letter ! Come on together and work hard (ง •_•)ง
If you like, just pay attention to the blogger , Or like the collection and comment on my article !!!