Randomly found a website to crawl , Our goal is
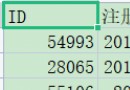
1. Using reptilian re、xpath Such as knowledge , Crawl to the news on this official website , The content includes : News headlines , Release time , News link , Reading times , Five attributes of news sources .
2. Put the data we crawled into a csv In the file of !
So let's start !
Tips : Reptiles cannot be used as illegal activities , Set the sleep time when crawling , Do not over crawl , Causing server downtime , Be legally liable !!!
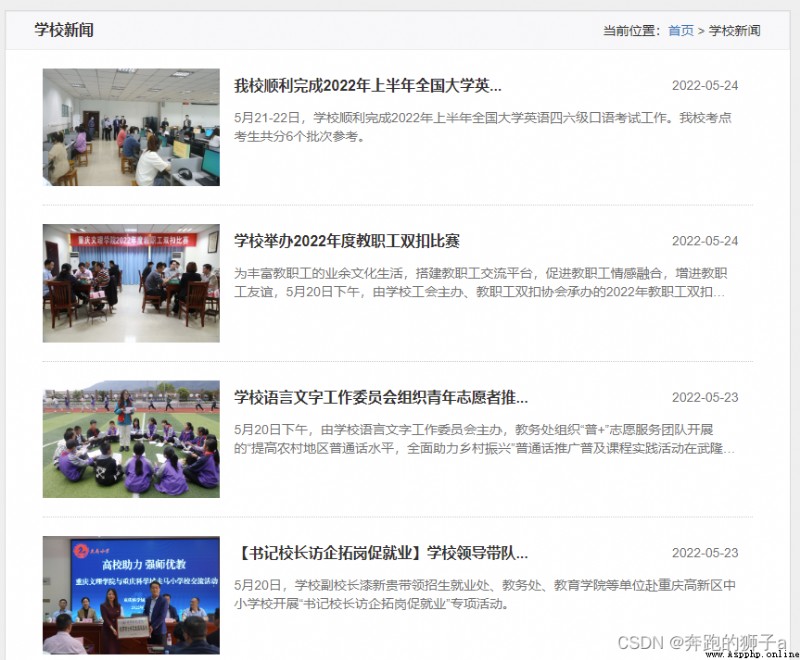
Our goal is to crawl this https://www.cqwu.edu.cn/channel_23133_0310.html News data of the website
import re
import time
import requests
from lxml import etree
import csv
# With crawling URL
base_url = "https://www.cqwu.edu.cn/channel_23133_0310.html"
# Anti creep
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9"
}
# Crawling information
resp = requests.get(url=base_url,headers=headers)
# Pass the information through etree Assign a value
html = etree.HTML(resp.text)
# xpath Locate news list information
news_list = html.xpath("/html/body/div/div[3]/div/div/div[2]/div/ul/li")
data_list = []
# Loop through the news list
for news in news_list:
# Get news links
news_url = news.xpath("./a/@href")[0]
# Continue to crawl to the details page of the news
news_resp = requests.get(url=news_url)
# Put the details page html Information assignment
news_html = etree.HTML(news_resp.text)
# xpath Locate the title of the news details page
news_title = news_html.xpath("/html/body/div/div[3]/div[1]/div/div[2]/div/div/h4/text()")[0]
# re Regular get date and reference source
time_refer_obj = re.compile(r'<div class="news-date">.*? Release time :(?P<time>.*?) Browse :.*? Time source :(?P<refer>.*?)</div>', re.S)
result = time_refer_obj.finditer(news_resp.text)
for it in result:
# Assign values to dates and references
news_time = it.group("time")
news_refer = it.group("refer").strip()
# re Regular access to traffic data
count_obj = re.compile(r" Browse :<Script Language='Javascript' src='(?P<count_url>.*?)'>", re.S)
result = count_obj.finditer(news_resp.text)
for it in result:
count_url = "https://www.cqwu.edu.cn" + it.group("count_url")
count_resp = requests.get(url=count_url)
news_read = count_resp.text.split("'")[1].split("'")[0]
# Create a dictionary , Assign the crawled information to the dictionary
data = {
}
data[' News headlines '] = news_title
data[' Release time '] = news_time
data[' News link '] = news_url
data[' Reading times '] = news_read
data[' News source '] = news_refer
# Add dictionary to list , Then it becomes xml Use
data_list.append(data)
# Sleep for a second
time.sleep(1)
print(data)
# 1. Create a file object ,encoding='utf-8' Is to set the encoding format ,newline='' To prevent blank lines
f = open('news.csv', 'w', encoding='utf-8',newline='')
# 2. Build on file objects csv Write object
csv_write = csv.writer(f)
# 3. Build list headers
csv_write.writerow([' News headlines ', ' Release time ', ' News link ', ' Reading times ', ' News source '])
for data in data_list:
# 4. write in csv file
csv_write.writerow([data[' News headlines '], data[' Release time '], data[' News link '], data[' Reading times '], data[' News source ']])
print(" End of climb !")
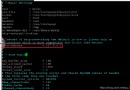
The following is the output process of our program 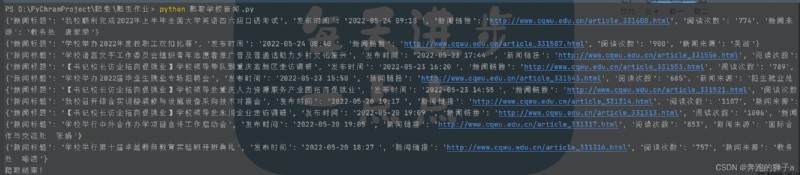
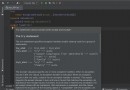
This is a program that stores data in csv The document of the document 
The basic steps of a reptile :
1. Check whether there is anti climbing , Set the normal reverse crawl ,User-Agent and referer Are the most common anti climbing methods
2. utilize xpath and re Technology positioning , Get the desired data after positioning
3. utilize csv The library writes data to csv In file