When you like a poet , When you want to get all his poetry data , This problem can be solved by crawling , Use the crawler to climb down all the poems , Then save it to txt In the document , Print it out and recite , Beauty is not true .
Tips : The following is the main body of this article , The following cases can be used for reference
We have to crawl Zhang Ruoxu All the poems of this poet and his personal profile
Get the poet information on this page first , But it is difficult to get all the poetry content on this page , In this page, you can get the detailed url, According to the poem details page url Continue to crawl the details page further , And then get the content of poetry
The code is as follows ( Example ):
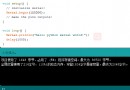
import requests
from lxml import etree
import re
import time
# Set the to crawl url
base_url = "https://www.shicimingju.com/chaxun/zuozhe/04.html"
# Anti creep
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Referer":"https://www.shicimingju.com"
}
# requests Crawl source code
resp = requests.get(url=base_url,headers=headers)
# XPATH analysis
html = etree.HTML(resp.text)
# xpath location , Get the author's name
author_name = html.xpath('//*[@id="main_right"]/div[1]/div[2]/div[1]/h4/a/text()')[0]
# Parsing data
# Set up re Regular expressions get the page elements of the author's profile
obj_introduction = re.compile(r'<div class="des">(?P<introduction>.*?)</div>', re.S)
# Start matching regular
result_introduction = obj_introduction.finditer(resp.text)
# Set author profile
author_introduction = ""
# Regular elimination of superfluous elements on the author's profile page html label , And assign a value to the author's profile to obtain text information
for it in result_introduction:
author_introduction = it.group("introduction")
pattern = re.compile(r'<[^>]+>', re.S)
author_introduction = pattern.sub('', author_introduction).strip()
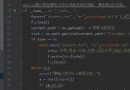
# xpath location , Get every piece url link , For the next level of access
poet_list = html.xpath('//*[@id="main_left"]/div[1]/div')
poet_list = poet_list[1::2]
for poet in poet_list:
url = poet.xpath('./div[2]/h3/a/@href')[0]
url = "https://www.shicimingju.com" + url
# Crawling through specific poetic information
resp_poet = requests.get(url=url)
resp_poet.encoding = 'utf-8'
# XPATH analysis
html_child = etree.HTML(resp_poet.text)
# xpath location , Get the author's name
poet_name = html_child.xpath('//*[@id="zs_title"]/text()')[0]
# Parsing data , Set the rules for getting poetry content
obj_content = re.compile(r'<div class="item_content" id="zs_content">(?P<poetry_content>.*?)</div>', re.S)
# Filter the regularization to get the regularized content
result_content = obj_content.finditer(resp_poet.text)
poetry_content = ""
# Filter the regularized content html label , Connect to poetry_content Poetry content string
for it in result_content:
poetry_content = it.group("poetry_content")
pattern = re.compile(r'<[^>]+>', re.S)
poetry_content = pattern.sub('', poetry_content).strip()
with open('poet.txt', 'a', encoding='utf-8') as file:
file.write(" Author's name :" + author_name + "\n Author's brief introduction :" + author_introduction + "\n Poem title :" + poet_name+"\n Poetry content :"+poetry_content+"\n")
print(" Author's name :" + author_name + "\n Author's brief introduction :" + author_introduction + "\n Poem title :" + poet_name+"\n Poetry content :"+poetry_content+"\n")
time.sleep(1)
print(" end !")
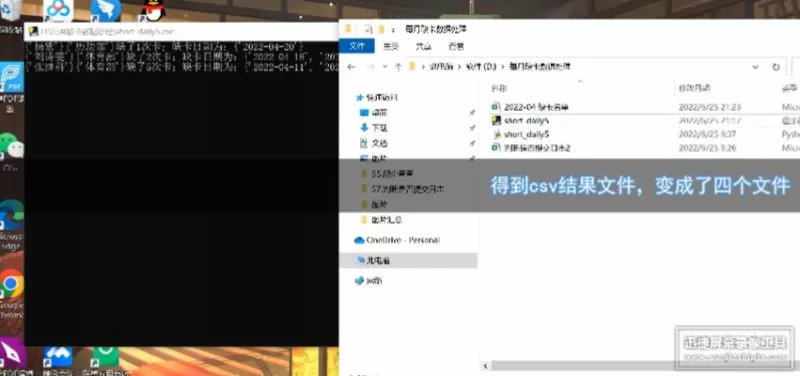
The following is the output of the program

Here is what we saved to txt The content of the document

The basic steps of a reptile :
1. Check whether there is anti climbing , Set the normal reverse crawl ,User-Agent and referer Are the most common anti climbing methods
2. utilize xpath and re Technology positioning , Get the desired data after positioning
3. utilize file File operations are written to text
4. Pay attention to the settings time Sleep