python的安裝只需要去官網進行下載最新版本,成熟的語言的主要語法是不會隨著版本的更新發生很大的變化,所以版本的選擇實際上問題不大
推薦使用anaconda3進行版本控制,使用的最大的方便就是很好的控制每一個python的版本和需要的庫,在開發的過程中,往常都是開發的時候需要用到什麼樣的庫文件再進行安裝和配置,不同的開發需要的庫文件環境不相同,後期的項目打包的時候,不需要打包沒有用到的庫,提高打包的效率

下載環境配置
官網下載鏈接
在系統高級設置的用戶環境變量配置環境變量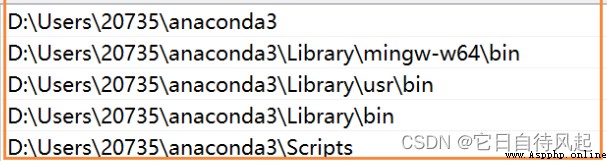
基本使用方法
環境配置完成之後可以在可以直接在cmd窗口使用conda 命令
#設置清華鏡像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
#設置bioconda
conda config --add channels bioconda
conda config --add channels conda-forge
#設置搜索時顯示通道地址
conda config --set show_channel_urls yes
#查看虛擬環境
conda env list
#激活虛擬環境
conda activate 虛擬環境的名字
#退出虛擬環境
conda deactivate
#創建虛擬環境
conda install -n 虛擬環境名字 python=版本號
#刪除虛擬環境
conda remove 虛擬環境名字
#查看已經安裝了的包
conda list
#獲得環境中的所有配置
conda env export --name myenv > myenv.yml
#重新還原環境
conda env create -f myenv.yml
#輸入
a=input("請輸入:")
#輸出
print(a)
#換行
print("\n")
在cmd窗口輸入 jupyter notebook就可以進入交互界面,相當於是自帶的shell,不過相較於它,notebook的界面更加美觀以及功能也更加全面
#變量不用聲明,可以直接賦值使用
#命名規則,關鍵字除外,使用字母,下劃線 ,數字組成,但是不能用數字開頭,命名規范化
a=1
b='ct'
#字符串的賦值可以使用單引號或者是雙引號,但是當字符串裡面有單引號的時候,外面就要用雙引號,反之裡面是雙引號外面就要是單引號
#在寫爬蟲的時候通常用這個方法處理正則表達式,在代碼裡面使用不了的,一般來說代碼
#裡面的/要在前面加上反斜槓進行轉義或者是,在字符串前加上 r,當前的字符串的 轉義字符\就會失效
#windows的路徑是用反斜槓分割的,在python裡面,會把反斜槓當成是轉義,會造成沖突
url = "https://translate.google.cn/?sl=auto&" \
"tl=zh-CN&text=hello&op=translate"
headers = {
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0"}
html = requests.get(url, headers=headers)
result = re.match(r"^<span.*?>(.*?)</span>", html)
print(result)
print(r'ct\n')
#字符串之間可以通過加號合並,也可以通過乘號進行操作,不能-/*
常見的字符串的處理函數
a="https://www.baidu.com"
#find() 在一個較長的字符串中查找子串,返回的是子串坐在位置的最左端的索引,如果沒找到的話就返回-1.
print(a.find("t")
#replace() 將字符串內匹配到的舊的字符替換成後面的新的字符串
print(a.replace("h","wa"))
#split() 通過指定的切割符對字符串進行切片,如果參數num有值的話,表示分割成num個字符
print(a.split("w"))
# format() 很方便的字符串拼接函數,很常用,在字符串裡面加入大括號{},在引號結束之後使用,方法裡面的參數對字符串裡面的括號進行替換
b="aaa"
c="t{},h{}".format(b,"cc")
#bool()函數可以評估任意值,返回的結果是Ture或者False,空值如([],{}'',"")
#和值為0或者是None的結果都是False,其他的都是True,和循環,條件語句配合使用
#運算符有 and or字面意思,
學校的離散作業用這個來做,很方便
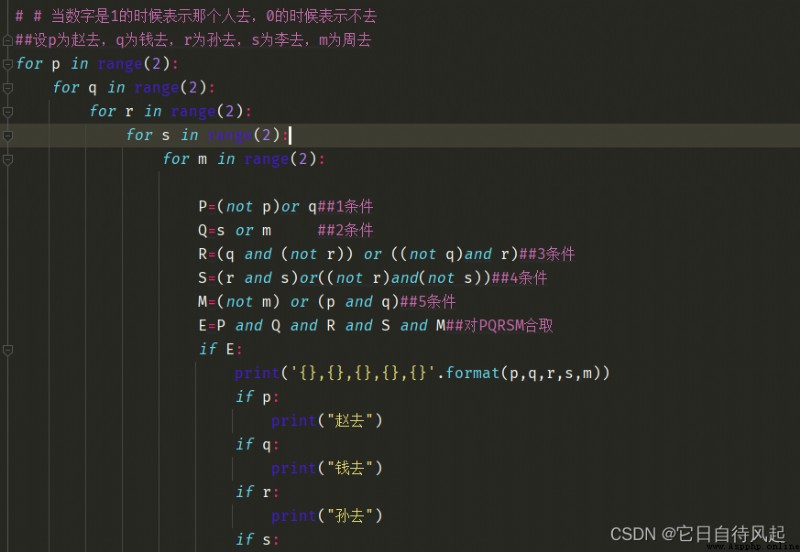
跟c語言的條件語句判斷大體上是一樣的,只是要注意格式的正確性。
#縮進是四個空格,直接敲tab鍵就行了
a=1
if a:
print("hello")
else:
pass
for循環
#可以是一個數字循環,只有一個數字,默認是從零開始到這個數字的前一位,不包括該數字
for i in range(10):
print(i)
#可以是range()多個參數,起點,終點,步長
for i in range(1,10,3)
#可以是一個列表
for i in ["小明","小紅","小。"]:
print(i)
#也可以是一個字符串
for i in "range":
print(i)
while循環
continue,pass和break使用
a=10
while a<20:
a=a+1
if a%2==0:
continue
elif a==15:
pass
else:
print('1')
用來存儲不同的數據類型,用小括號括起來,字符串要加引號,數字不用加
service=[3,'ht','ssh']
print(service[1]) ##輸出第二個元素
print(service[-1]) ##輸出最後一個元素
#切片
print(service[1:]) ##打印第一個元素之後的內容
print(service[:-1]) ##打印最後一個元素之前的內容
print(service[::-1]) ##倒序輸出
#列表操作函數
service.pop() ##彈出最後一個元素
a = service.pop(0) ##彈出第1個元素 ###可以將其賦值
service.remove('ssh') ##指定刪除對象的名字 ##直接刪除,不能將其賦值 ##不能指定序號,只能指定要刪除對象的
del service ##刪除列表
del service ##直接刪除整個列表
print(service)
names = ['alice','Bob','coco','Harry']
names.sort()
names ###按照ASCLL排序 ###先排序首字母為大寫的,再排序首字母是小寫的
names.sort(key=str.lower) ###對字符串排序不區分大小寫,相當於將所有元素轉換為小寫,再排序
names.sort(key=str.upper) ###相當於將所有元素轉換為大寫,再排序
元組一旦被創建,它的元素就不可更改,所以元組是不可變的列表,標志是用小括號()包起來
使用大括號括起來,與列表等不同,不能使用下標訪問到裡面的元素,可以使用循環用便利得到元素,集合裡面的元素是不能重復的,可以對一個列表使用set()方法轉換成為集合,間接實現了去重操作
字典是可變容器模型,可以存儲任意對象,采用鍵值對的方式存儲,中間使用冒號隔開,每一對鍵值對之間使用逗號,分割,整個字典使用大括號{}括起來
#字典格式
dict={
"name":"小明","age":12,"like":['ball','book']}
#字典訪問
print(dict["name"])
print(dict["like"][0])
函數裡面要注意局部變量和全局變量
def 函數名(參數):
pass
#使用import 導入寫好的文件
# from 模塊名 import 方法/類/*
使用內置的open函數進行讀取操作
讀取完之後要使用close()關閉文件
#mode表示打開方式,w就是寫入,r表示讀取,r+即可以讀取又可以寫入,返回值是一個文件對象
f = open("文件路徑","mode")
f.write("文本")
f.flush() #將內存內容立即寫入硬盤
f.close()
# 常用
with open(filename, 'wb') as f: #以二進制形式打開文件
f.write("圖片資源")
try的工作原理是,當開始一個try語句後,python就在當前程序的上下文中作標記,這樣當異常出現時就可以回到這裡,try子句先執行,接下來會發生什麼依賴於執行時是否出現異常。
try:
<語句> #運行別的代碼
except <名字>:
<語句> #如果在try部份引發了'name'異常
except <名字>,<數據>:
<語句> #如果引發了'name'異常,獲得附加的數據
else:
<語句> #如果沒有異常發生
#try-finally 語句無論是否發生異常都將執行最後的代碼。
try:
<語句>
finally:
<語句> #退出try時總會執行
#基本格式
class Persion:
name="小明"
age=12
def fun(self):
print(age)
p=Persion()
print(p.name)
#每一次創建對象的時候,都會自動調用__init__()方法,類似於java的構造方法
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
p1 = Person("Bill", 63)
print(p1.name)
print(p1.age)
import threading
import time
def run(n):
print("task", n)
time.sleep(1)
print('2s')
time.sleep(1)
print('1s')
time.sleep(1)
print('0s')
time.sleep(1)
if __name__ == '__main__':
t1 = threading.Thread(target=run, args=("t1",))
t2 = threading.Thread(target=run, args=("t2",))
t1.start()
t2.start()
#繼承threading.Thread來自定義線程類,其本質是重構Thread類中的run方法
import threading
import time
class MyThread(threading.Thread):
def __init__(self, n):
super(MyThread, self).__init__() # 重構run函數必須要寫
self.n = n
def run(self):
print("task", self.n)
time.sleep(1)
print('2s')
time.sleep(1)
print('1s')
time.sleep(1)
print('0s')
time.sleep(1)
if __name__ == "__main__":
t1 = MyThread("t1")
t2 = MyThread("t2")
t1.start()
t2.start()
pyqt5庫的gui編程,可以在可視化添加窗口組件,定義UI