Four 、 Custom request header
1, Basic usage
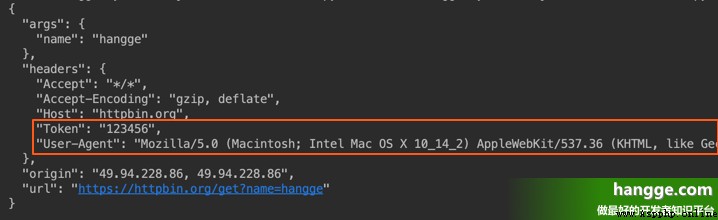
(1) If we want to add HTTP Request header ( Request Header), Just simply pass on one dict to headers Parameters are OK .
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Token': '123456'
}
r = requests.get('http://httpbin.org/get?name=hangge', headers=headers)
print(r.text) (2) Running the program, you can see that the request header has been added successfully :
2, matters needing attention
(1) customized header The priority of is lower than that of some specific information sources , for example :
- If in .netrc User authentication information is set in , Use headers= The set authorization will not take effect . And if you set it auth= Parameters ,``.netrc`` The settings of are invalid .
- If redirected to another host , to grant authorization header It will be deleted .
- Agency authorization header Will be URL The proxy identity provided in overrides .
- When we can judge the length of the content ,header Of Content-Length Will be rewritten .
(2) Simply speaking , Requests Not based on customization header Change your behavior . Just in the last request , be-all header Information will be passed in .
5、 ... and 、 timeout
1,timeout Parameters
(1) By default , requests There is no time-out limit , If the request does not respond , Our program will wait forever . (2) We can use timeout Parameter set duration ( Company : second ), tell requests How long does it take to stop waiting for a response . Be careful :timeout Only valid for connection process , Nothing to do with the download of the response body .
timeout It's not the entire download response time limit , But if the server is timeout No response in seconds , An exception will be thrown ( To be more precise , Is in timeout When no bytes of data are received from the underlying socket within seconds )
2, Use samples
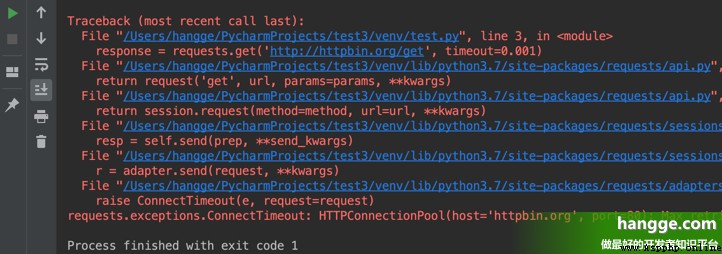
(1) Next, set the timeout to 0.001 second ( This will definitely time out )
import requests
response = requests.get('http://httpbin.org/get', timeout=0.001)
print(response.text) (2) When running, you can find that a timeout exception is thrown :
6、 ... and 、Cookie
1, see cookie Information
(1) Here we ask Baidu to translate the home page , It can be seen that Baidu has generated a project named BAIDUID Of cookie, Put it in RequestsCookieJar[] In the . Because we didn't save this locally cookie And carry it on the next request , Every time the following code is executed, Baidu will generate a new cookie:
import requests
response = requests.get("https://fanyi.baidu.com")
print(type(response.cookies), response.cookies)
print("-------------------")
for key, value in response.cookies.items():
print(key + "=" + value)
(2) requests The library also provides a way to RequestsCookieJar convert to dict Dictionaries :
import requests
response = requests.get("https://fanyi.baidu.com")
print(type(response.cookies), response.cookies)
print("-------------------")
cookies = requests.utils.dict_from_cookiejar(response.cookies)
print(cookies)
2, Customize cookie
(1) If you want to add some... When sending a request cookie, The easiest way is to set cookies Parameters . Let's build a dictionary cookie, Request Baidu translation page again , You can see that there will be no new... In the returned results cookie, It shows that Baidu doesn't think we are a new client request :
import requests
cookies = {'BAIDUID': 'DEBE4AEE74931831BD0406630BEC3B5C:FG=1'}
response = requests.get("https://fanyi.baidu.com",cookies=cookies)
print(type(response.cookies), response.cookies)
(2) structure cookie A more professional way is to instantiate a RequestCookieJar Class , Then put the value set go in . The effect of the following code is the same as that of the above : RequestsCookieJar The behavior of is similar to that of a dictionary , But the interface is more complete , It is suitable for cross domain and cross path use
import requests
cookie_jar = requests.cookies.RequestsCookieJar()
cookie_jar.set('BAIDUID', 'DEBE4AEE74931831BD0406630BEC3B5C:FG=1', domain='fanyi.baidu.com')
response = requests.get("https://fanyi.baidu.com",cookies=cookies)
print(type(response.cookies), response.cookies) 7、 ... and 、 Setting agent
If you need to use a proxy for some requests , have access to requests Of proxies Parameter setting :
proxies = {
"http": "http://192.168.43.1:58300",
"https": "https://192.168.43.1:58300"
}
response = requests.get("http://httpbin.org/get", proxies=proxies)
print(response.text)