四、文件下載
1,普通下載
(1)對於非文本請求,我們可以通過 Response 對象的 content 屬性以字節的方式訪問請求響應體。 注意:這種模式只能下載小文件。因為在這種模式下,從網站接受到的數據是一直儲存在內存中,只有當 write 時才寫入硬盤,如果文件很大,那麼所占用的內存也是很大的。
(2)下面將一張網絡上的圖片下載到本地並保存(文件名不變):
import requests
url = 'http://www.hangge.com/blog/images/logo.png'
r = requests.get(url)
with open("logo.png", "wb") as code:
code.write(r.content) (3)代碼運行後可以看到圖片已經成功下載下來了。

2,流式下載
下面代碼我們改成流式下載,即邊下載邊保存。這種方式適合用來下載大文件。
import requests
url = 'http://www.hangge.com/blog/images/logo.png'
r = requests.get(url, stream=True)
with open("logo.png", "wb") as f:
for bl in r.iter_content(chunk_size=1024):
if bl:
f.write(bl) 3,帶進度的文件下載
(1)如果文件體積很大,下載時我們最好能實時顯示當前的下載進度。為方便使用,我這裡封裝了一個下載方法(內部同樣使用流式下載的方式)。
import requests
from contextlib import closing
# 文件下載器
def down_load(file_url, file_path):
with closing(requests.get(file_url, stream=True)) as response:
chunk_size = 1024 # 單次請求最大值
content_size = int(response.headers['content-length']) # 內容體總大小
data_count = 0
with open(file_path, "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
data_count = data_count + len(data)
now_jd = (data_count / content_size) * 100
print("\r 文件下載進度:%d%%(%d/%d) - %s"
% (now_jd, data_count, content_size, file_path), end=" ")
if __name__ == '__main__':
fileUrl = 'http://www.hangge.com/hangge.zip' # 文件鏈接
filePath = "hangge.zip" # 文件路徑
down_load(fileUrl, filePath)
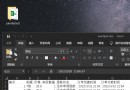
(3)運行效果如下,可以看到在文件下載的過程會實時顯示當前的進度:

4,帶下載速度顯示的文件下載
這裡對上面的方法做個改進,增加實時下載速度的計算和顯示:
import requests
import time
from contextlib import closing
# 文件下載器
def down_load(file_url, file_path):
start_time = time.time() # 文件開始下載時的時間
with closing(requests.get(file_url, stream=True)) as response:
chunk_size = 1024 # 單次請求最大值
content_size = int(response.headers['content-length']) # 內容體總大小
data_count = 0
with open(file_path, "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
data_count = data_count + len(data)
now_jd = (data_count / content_size) * 100
speed = data_count / 1024 / (time.time() - start_time)
print("\r 文件下載進度:%d%%(%d/%d) 文件下載速度:%dKB/s - %s"
% (now_jd, data_count, content_size, speed, file_path), end=" ")
if __name__ == '__main__':
fileUrl = 'http://www.hangge.com/hangge.zip' # 文件鏈接
filePath = "hangge.zip" # 文件路徑
down_load(fileUrl, filePath)