For personal study only
originate mofi Python:https://mofanpy.com/tutorials/python-basic/basic/ Invasion and deletion
>>> print(1)
1
>>> print("we're going to do something")
we're going to do something
>>> print('apple' + 'car')
applecar
>>> print('apple' + str(4))
apple4
>>> print(1+2)
3
>>> print(int('1') + 2)
3
>>> print(float('1.2') + 2)
3.2
>>> a, b, c = 1, 2, 3
condition = 1
while condition < 10:
print(condition)
condition = condition + 1
# Dead cycle Ctrl + C To terminate the program
while True:
print(condition)
# Output 1-9
for i in range(1, 10):
print(i)
range(start, stop, step)
list
list list = [1, 2, 3]
tuple
Tuples tup = (‘python’, 1.7, 64)
dict
dictionary Dictionaries During the iteration key Return as an iterated object . In the dictionary key It's out of order .
A dictionary in the same order :collections Module OrderedDict object
dic{
}
dic['lan'] = 'python'
dic['version'] = 3.7
dic['platform'] = 64
for key in dic:
print(key, dic[key])
set
set The collection removes duplicates , The output is not in the order of input .
s = set([‘python’, ‘python2’, ‘python3’,‘python’])
if x==y:
print('x is equal to y')
# To judge equality ==, For assignment =
if condition:
true
else:
false
python There is no
? : :Binocular expression . It can be done byif-elseThe inline expression of does something similar .
var = var1 if condition else var2
If
conditionThe value of isTrue, It will bevar1The value is assigned tovar; IfFalseWillvar2The value is assigned tovar
if condition1:
true1_expressions
elif condition2:
true2_expressions
elif condtion3:
true3_expressions
elif ...
...
else:
else_expressions
def function():
a = 1
return a
def function(a, b):
c = a + b
return c
print(function(1, 2))
def function(a = 1, b) # Wrong writing
def function(b, a = 1) # Write it correctly
# Use... Where default parameters are required `=` No. is given
# Note that all default parameters cannot appear before non default functions
def report(name, *grades):
total_grade = 0
for grade in grades:
total_grade += grade
return total_grade
Parameters can be encapsulated into a
listortuplePass inVariable parameters are used here * The number modifies , Variable parameters cannot appear before specific parameters and default parameters , Because variable parameters will devour these parameters .
def func(name, **kw):
print('name is', name)
for k,v in kw.items():
print(k, v)
func('Mike', age=24, country='China', education='bachelor')
# These parameters are automatically encapsulated into a dictionary inside the function (dict)
install :pip install numpy
to update :pip install -U numpy
\n
myFile = open('file.txt', 'w') # w Write ,r read ,a Additional
myFile.write(text) # take text write file
myFile.close() # Close file
\t achieve tab Alignment effect
file.read()
Read everything in the text
file.readline()
Read a line
file.readlines()
Read all lines , return list
class Calculator: # The first letter should be capitalized , The colon cannot be missing
name='Good Calculator' # The act class Properties of
price=18
def add(self,x,y): # self As the default value
print(self.name)
result = x + y
print(result)
def minus(self,x,y):
result=x-y
print(result)
def times(self,x,y):
print(x*y)
def divide(self,x,y):
print(x/y)
"""" >>> cal=Calculator() # Note that this runs class When it comes to "()", Otherwise, an error will occur when calling the following functions , Cause unable to call . >>> cal.name 'Good Calculator' >>> cal.price 18 >>> cal.add(10,20) Good Calculator 30 >>> cal.minus(10,20) -10 >>> cal.times(10,20) 200 >>> cal.divide(10,20) 0.5 >>> """"
__init__It can be understood as initializationclassThe variable of , From EnglishinitialThe original meaning . Available at run time , Attach value to initial value ,function
c=Calculator('bad calculator',18,17,16,15), Then call up the value of each initial value . Look at the code below .The underline here is a double underline
class Calculator:
name='good calculator'
price=18
def __init__(self,name,price,height,width,weight): # Be careful , The underline here is a double underline
self.name=name
self.price=price
self.h=height
self.wi=width
self.we=weight
"""" >>> c=Calculator('bad calculator',18,17,16,15) >>> c.name 'bad calculator' >>> c.price 18 >>> c.h 17 >>> c.wi 16 >>> c.we 15 >>> """"
score = int(input('please input your scor:\n'))
Tuple
Use parentheses 、 Or without brackets , It's a sequence of numbers
Tuple Immutable after definition , Can be nested
a_tuple = (1, 2, 3)
b_tuple = 1, 2, 3
List
Same as Tuple, but List Is named after brackets
variable , Can be nested
a_list = [1, 2, 3]
a_list.append(0) # Last append
a_list.insert(1, 0) # In position 1 Add at 0
a_list.remove(2) # The first value in the delete list is 2 The item
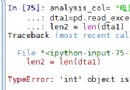
print(a[0]) # Display list a Of the 0 The value of a
print(a[-1]) # Display list a The last value of
print(a[0:3]) # Display list a From the first 0 position To The first 2 position ( The first 3 Bit before ) Values of all items of
print(a[5:]) # Display list a Of the 5 Bit and all subsequent items
print(a[-3:]) # Display list a The last of 3 Bit and all subsequent items
print(a.index(2)) # Display list a The value that first appears in is 2 Index of the item
a.count(-1) # Count the number of times a value appears in the list
a.sort() # The default order is from small to large
a.sort(reverse=True) # Sort from large to small
a = [1,2,3,4,5] # One row and five columns
multi_dim_a = [[1,2,3],
[2,3,4],
[3,4,5]] # Three lines and three columns
print(a[1])
# 2
print(multi_dim_a[0][1])
# 2
a_list = [1,2,3,4,5,6,7,8]
d1 = {
'apple':1, 'pear':2, 'orange':3} # Dictionaries are unordered containers
d2 = {
1:'a', 2:'b', 3:'c'}
d3 = {
1:'a', 'b':2, 'c':3}
print(d1['apple']) # 1
print(a_list[0]) # 1
del d1['pear']
print(d1) # {'orange': 3, 'apple': 1}
d1['b'] = 20
print(d1) # {'orange': 3, 'b': 20, 'apple': 1}
def func():
return 0
d4 = {
'apple':[1,2,3], 'pear':{
1:3, 3:'a'}, 'orange':func}
print(d4['pear'][3]) # a
import time as t # Need to add t. Prefix to derive functions
from time import time, localtime # only import The function you want .
from time import * # All functions of the input module
try:
file=open('eeee.txt','r') # Error code
except Exception as e: # Store the error in e in
print(e)
try:
file=open('eeee.txt','r+')
except Exception as e:
print(e)
response = input('do you want to create a new file:')
if response=='y':
file=open('eeee.txt','w')
else:
pass # Empty statement
else:
file.write('ssss')
file.close()
"""
[Errno 2] No such file or directory: 'eeee.txt'
do you want to create a new file:y
ssss #eeee.txt Will be written in 'ssss'
zip Accept any number of ( Include 0 And 1 individual ) Sequence as a parameter , Merge and return to
Tuplelist
a=[1,2,3]
b=[4,5,6]
ab=zip(a,b)
print(list(ab)) # Need to add list To visualize this function
""" [(1, 4), (2, 5), (3, 6)] """
for i,j in zip(a,b):
print(i/2,j*2)
""" 0.5 8 1.0 10 1.5 12 """
fun = lambda x,y : x+y, Before the colonx,yIndependent variable , After the colonx+yFor concrete operations .
fun= lambda x,y:x+y
x=int(input('x=')) # Here's the definition int Integers , Otherwise, it defaults to string
y=int(input('y='))
print(fun(x,y))
""" x=6 y=6 12 """
mapIs to bind functions and parameters together .
>>> def fun(x,y):
return (x+y)
>>> list(map(fun,[1],[2]))
""" [3] """
>>> list(map(fun,[1,2],[3,4]))
""" [4,6] """
1. assignment : Only the reference to the new object is copied , Will not open up new memory space .
It does not produce an independent object that exists alone , Just put a new label on the original data block , So when one of the tags is changed , Data blocks will change , The other label will also change .
import copy
a = [1,2]
b = a
a.append(3)
print(a)
print(b)
2. Shallow copy : Create new objects , Its content is a reference to the original object .
3. Deep copy : Corresponding to shallow copy , Deep copy copies all the elements of the object , Including multiple nested elements . The deep copy object is a brand new object , No longer associated with the original object .
Multithreading Threading It is a method to make the program have a separate effect . Can handle multiple things at the same time . A normal program can only execute code from top to bottom , however Multithreading (Threading) Can break this restriction . Make your program live .
Multi process Multiprocessing It can make the computer assign tasks to each processor more efficiently , This approach solves the drawbacks of multithreading . It can also improve efficiency .
GUI Design module .
import pickle
a_dict = {
'da': 111, 2: [23,1,4], '23': {
1:2,'d':'sad'}}
# pickle Is a variable to a file
file = open('pickle_example.pickle', 'wb')
pickle.dump(a_dict, file)
file.close()
# need close()
file = open('pickle_example.pickle', 'rb')
a_dict1 = pickle.load(file)
file.close()
# There is no need to close()
with open('pickle_example.pickle', 'rb') as file:
a_dict1 =pickle.load(file)
print(a_dict1)
set The main function is to find a sentence or a list Different elements
char_list = ['a', 'b', 'c', 'c', 'd', 'd', 'd']
sentence = 'Welcome Back to This Tutorial'
print(set(char_list))
>>> {
'b', 'd', 'a', 'c'}
print(set(sentence))
>>> {
'l', 'm', 'a', 'c', 't', 'r', 's', ' ', 'o', 'W', 'T', 'B', 'i', 'e', 'u', 'h', 'k'}
print(set(char_list+ list(sentence)))
>>> {
'l', 'm', 'a', 'c', 't', 'r', 's', ' ', 'd', 'o', 'W', 'T', 'B', 'i', 'e', 'k', 'h', 'u', 'b'}
addAdd an element , But not all elements can be added , Like a list .
unique_char = set(char_list)
unique_char.add('x')
# unique_char.add(['y', 'z']) this is wrong
print(unique_char)
# {'x', 'b', 'd', 'c', 'a'}
Clear an element with
removeordiscardClear all with
clear
unique_char.remove('x')
print(unique_char)
# {'b', 'd', 'c', 'a'}
unique_char.discard('d')
print(unique_char)
# {'b', 'c', 'a'}
unique_char.clear()
print(unique_char)
# set()
We can also do some filtering , For example, compare another thing , Look at the original set Is there anything different from him (
difference). Or compare it to another thing , have a look set Do you have the same (intersection).
unique_char = set(char_list)
print(unique_char.difference({
'a', 'e', 'i'}))
# {'b', 'd', 'c'} Different
print(unique_char.intersection({
'a', 'e', 'i'}))
# {'a'} identical
pattern1 = "cat"
pattern2 = "bird"
string = "dog runs to cat"
print(pattern1 in string) # True
print(pattern2 in string) # False
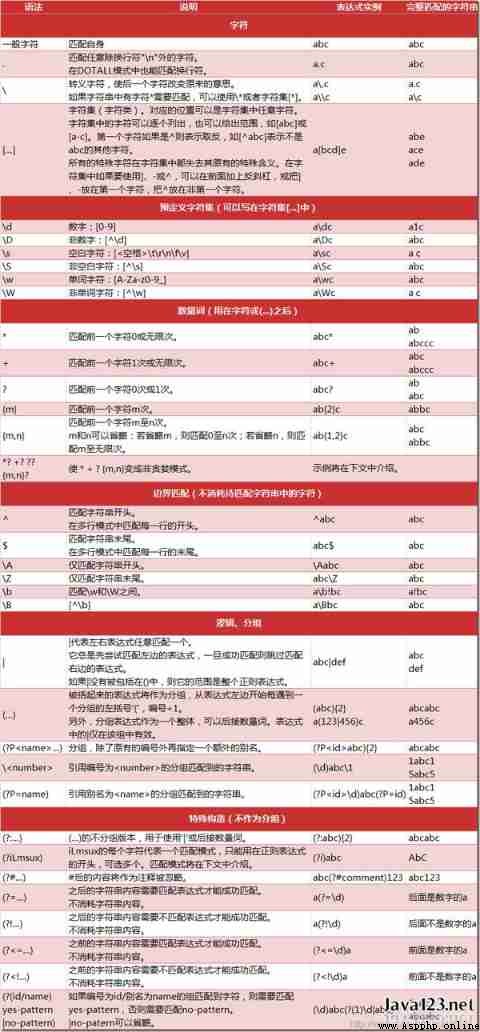
python Medium re modular .re.search() : No return found None, Found return match Of object
import re
# regular expression
pattern1 = "cat"
pattern2 = "bird"
string = "dog runs to cat"
print(re.search(pattern1, string)) # <_sre.SRE_Match object; span=(12, 15), match='cat'>
print(re.search(pattern2, string)) # None
Use special pattern To flexibly match the text you need to find .
If you need to find potential multiple possibilities , We can use
[]Include possible characters . such as[ab]It means that the character I want to find can beaIt can also beb. Here we also need to pay attention to , Establish a regular rule , We are pattern Of “ You need to add arUsed to indicate that this is a regular expression , Instead of ordinary strings . Through the following form , If... Appears in the string run Or is it ran”, It can find .
# multiple patterns ("run" or "ran")
ptn = r"r[au]n" # start with "r" means raw string
print(re.search(ptn, "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 7), match='run'>
Again , brackets
[]It can also be the following or a combination of these . such as[A-Z]It means all capital English letters .[0-9a-z]The representation can be a number or any lowercase letter .
print(re.search(r"r[A-Z]n", "dog runs to cat")) # None
print(re.search(r"r[a-z]n", "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 7), match='run'>
print(re.search(r"r[0-9]n", "dog r2ns to cat")) # <_sre.SRE_Match object; span=(4, 7), match='r2n'>
print(re.search(r"r[0-9a-z]n", "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 7), match='run'>
In addition to defining their own rules , There are many matching rules that are defined for you in advance . Here are some special matching types for you to summarize .
- \d : Any number
- \D : Not numbers
- \s : whatever white space, Such as [\t\n\r\f\v]
- \S : No white space
- \w : Any upper and lower case letters , Numbers and _ [a-zA-Z0-9_]
- \W : No \w
- \b : Blank character ( only At the beginning or end of a word )
- \B : Blank character ( No At the beginning or end of a word )
- \ : matching \
- . : Match any character ( except \n)
- ^ : Match the beginning
- $ : Match the end
- ? : The preceding characters are optional
# \d : decimal digit
print(re.search(r"r\dn", "run r4n")) # <_sre.SRE_Match object; span=(4, 7), match='r4n'>
# \D : any non-decimal digit
print(re.search(r"r\Dn", "run r4n")) # <_sre.SRE_Match object; span=(0, 3), match='run'>
# \s : any white space [\t\n\r\f\v]
print(re.search(r"r\sn", "r\nn r4n")) # <_sre.SRE_Match object; span=(0, 3), match='r\nn'>
# \S : opposite to \s, any non-white space
print(re.search(r"r\Sn", "r\nn r4n")) # <_sre.SRE_Match object; span=(4, 7), match='r4n'>
# \w : [a-zA-Z0-9_]
print(re.search(r"r\wn", "r\nn r4n")) # <_sre.SRE_Match object; span=(4, 7), match='r4n'>
# \W : opposite to \w
print(re.search(r"r\Wn", "r\nn r4n")) # <_sre.SRE_Match object; span=(0, 3), match='r\nn'>
# \b : empty string (only at the start or end of the word)
print(re.search(r"\bruns\b", "dog runs to cat")) # <_sre.SRE_Match object; span=(4, 8), match='runs'>
# \B : empty string (but not at the start or end of a word)
print(re.search(r"\B runs \B", "dog runs to cat")) # <_sre.SRE_Match object; span=(8, 14), match=' runs '>
# \\ : match \
print(re.search(r"runs\\", "runs\ to me")) # <_sre.SRE_Match object; span=(0, 5), match='runs\\'>
# . : match anything (except \n)
print(re.search(r"r.n", "r[ns to me")) # <_sre.SRE_Match object; span=(0, 3), match='r[n'>
# ^ : match line beginning
print(re.search(r"^dog", "dog runs to cat")) # <_sre.SRE_Match object; span=(0, 3), match='dog'>
# $ : match line ending
print(re.search(r"cat$", "dog runs to cat")) # <_sre.SRE_Match object; span=(12, 15), match='cat'>
# ? : may or may not occur
print(re.search(r"Mon(day)?", "Monday")) # <_sre.SRE_Match object; span=(0, 6), match='Monday'>
print(re.search(r"Mon(day)?", "Mon")) # <_sre.SRE_Match object; span=(0, 3), match='Mon'>
If a string has many lines , We want to use
^Form to match the characters at the beginning of the line , If it is not successful in the usual form . Like the following I Appears at the beginning of the second line , But user"^I"But it doesn't match the second line , Now , We're going to use Another parameter , Give Wayre.search()Each line can be processed separately . This parameter isflags=re.M, Or it can be written like thisflags=re.MULTILINE.
string = """ dog runs to cat. I run to dog. """
print(re.search(r"^I", string)) # None
print(re.search(r"^I", string, flags=re.M)) # <_sre.SRE_Match object; span=(18, 19), match='I'>
If we want a rule to be repeated , It can also be implemented in regular , And there are many ways to realize . It can be divided into these three types :
*: Repeat zero or more times+: Repeat one or more times{n, m}: repeat n to m Time{n}: repeat n Time
# * : occur 0 or more times
print(re.search(r"ab*", "a")) # <_sre.SRE_Match object; span=(0, 1), match='a'>
print(re.search(r"ab*", "abbbbb")) # <_sre.SRE_Match object; span=(0, 6), match='abbbbb'>
# + : occur 1 or more times
print(re.search(r"ab+", "a")) # None
print(re.search(r"ab+", "abbbbb")) # <_sre.SRE_Match object; span=(0, 6), match='abbbbb'>
# {n, m} : occur n to m times
print(re.search(r"ab{2,10}", "a")) # None
print(re.search(r"ab{2,10}", "abbbbb")) # <_sre.SRE_Match object; span=(0, 6), match='abbbbb'>
We can even group what we find , Use
()Can easily achieve this . By grouping , We can easily locate what we find . Like here(\d+)In the group , What we need to find is some numbers , stay(.+)In this group , We will find Date: All the rest . When usingmatch.group()when , He will return the contents of all groups , And if you give.group(2)Add a number , It can locate which group of information you need to return .
match = re.search(r"(\d+), Date: (.+)", "ID: 021523, Date: Feb/12/2017")
print(match.group()) # 021523, Date: Feb/12/2017
print(match.group(1)) # 021523
print(match.group(2)) # Date: Feb/12/2017
occasionally , There will be many groups , Using numbers alone may be difficult to find the group you want , Now , If you have a name as an index , It will be a very easy thing . We need to write this form at the beginning of parentheses
?P< name >Just define a name for this group . Then you can use this name to find the content of this group .
match = re.search(r"(?P<id>\d+), Date: (?P<date>.+)", "ID: 021523, Date: Feb/12/2017")
print(match.group('id')) # 021523
print(match.group('date')) # Date: Feb/12/2017
What we said earlier is that we only found the first match , If you need to find all the matches , We can use
findallfunction . And then it goes back to a list . Note that there is a new knowledge point below ,|yes or It means , If it weren't for the former, if it weren't for the latter .
# findall
print(re.findall(r"r[ua]n", "run ran ren")) # ['run', 'ran']
# | : or
print(re.findall(r"(run|ran)", "run ran ren")) # ['run', 'ran']
We can also match some forms of strings through regular expressions and then replace them . Use this matching
re.sub(), Will compare python Self containedstring.replace()Be flexible .
print(re.sub(r"r[au]ns", "catches", "dog runs to cat")) # dog catches to cat
Come again Python There is a string segmentation function in , For example, if you want to get all the words in a sentence . such as
"a is b".split(" "), This will produce a list of all the words . But in regular , This ordinary segmentation can also be done incisively and exquisitely .
print(re.split(r"[,;\.]", "a;b,c.d;e")) # ['a', 'b', 'c', 'd', 'e']
Last , We can still use compile After the regular , To reuse this regular . Let's start with regular compile Enter a variable , such as
compiled_re, Then use this directlycompiled_reTo search for .
compiled_re = re.compile(r"r[ua]n")
print(compiled_re.search("dog ran to cat")) # <_sre.SRE_Match object; span=(4, 7), match='ran'>