pandas Use pipe Official documents of :https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.pipe.html
import pandas as pd
def drop_duplicates(df, column_name):
""" Delete """
return df.drop_duplicates(subset=column_name)
def add_new_column(dataframe, new_column={
}):
""" Add new data """
for key, value in new_column.items():
dataframe[key] = value
return dataframe
def main():
dataframe = pd.DataFrame({
"a": [1, 2, 3, 4, 4],
'b': [1, None, None, 4, 4],
})
df_processed = (
dataframe
.pipe(drop_duplicates, column_name=['a'])
.pipe(add_new_column, new_column={
"c": [1, 2, 3, 4]})
)
print(df_processed)
if __name__ == '__main__':
main()
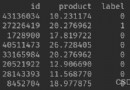
The result is as follows :
a b c
0 1 1.0 1
1 2 NaN 2
2 3 NaN 3
3 4 4.0 4