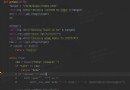
solver.prototxt File parameter settings for
Generate solver file
Easy way
Training models (training)
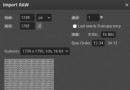
solver.prototxt File parameter settings forcaffe During training , Some parameter settings are required , We usually set these parameters to a value called solver.prototxt In the document of , as follows :
base_lr: 0.001
display: 782
gamma: 0.1
lr_policy: “step”
max_iter: 78200
momentum: 0.9
snapshot: 7820
snapshot_prefix: “snapshot”
solver_mode: GPU
solver_type: SGD
stepsize: 26067
test_interval: 782
test_iter: 313
test_net: “/home/xxx/data/val.prototxt”
train_net: “/home/xxx/data/proto/train.prototxt”
weight_decay: 0.0005
There are some parameters that need to be calculated , It's not random .
Suppose we have 50000 Training samples ,batch_size by 64, That is, each batch is processed 64 Samples , So you need to iterate 50000/64=782 All samples are processed once . We will process all the samples once , Call it a generation , namely epoch. therefore , there test_interval Set to 782, That is, after processing all training data once , To test . If we want to train 100 generation , You need to set max_iter by 78200.
Empathy , If there is 10000 Three test samples ,batch_size Set to 32, So you need to iterate 10000/32=313 The test is completed only once , So set test_iter by 313.
As the number of iterations increases, the learning rate is set to , Slowly lower . Total iterations 78200 Time , We will change lr_rate Three times , therefore stepsize Set to 78200/3=26067, That is, every iteration 26067 Time , Let's reduce the learning rate once .
Generate solver fileHere is the generation solver Of documents python Code , Relatively simple :
# -*- coding: utf-8 -*-"""Created on Sun Jul 17 18:20:57 [email protected]: root"""path='/home/xxx/data/'solver_file=path+'solver.prototxt' #solver File save location sp={}sp['train_net']=‘“'+path+'train.prototxt”' # Training profile sp['test_net']=‘“'+path+'val.prototxt”' # Test profile sp['test_iter']='313' # Test iterations sp['test_interval']='782' # Test interval sp['base_lr']='0.001' # Basic learning rate sp['display']='782' # Screen log display interval sp['max_iter']='78200' # Maximum number of iterations sp['lr_policy']='“step”' # The law of learning rate change sp['gamma']='0.1' # Learning rate change index sp['momentum']='0.9' # momentum sp['weight_decay']='0.0005' # Weight attenuation sp['stepsize']='26067' # How often does the learning rate change sp['snapshot']='7820' # preservation model interval sp['snapshot_prefix']=‘"snapshot"' # The saved model Prefix sp['solver_mode']='GPU' # Whether to use gpusp['solver_type']='SGD' # optimization algorithm def write_solver(): # write file with open(solver_file, 'w') as f: for key, value in sorted(sp.items()): if not(type(value) is str): raise TypeError('All solver parameters must be strings') f.write('%s: %s\n' % (key, value))if __name__ == '__main__': write_solver()Execute the above file , We'll get one solver.prototxt file , With this document , We can train next .
Of course , If you think the above key value pair dictionary way , It is easy to make mistakes in writing , We can also use another simple method , No quotes , It's not easy to make mistakes , as follows :
Easy way# -*- coding: utf-8 -*-from caffe.proto import caffe_pb2s = caffe_pb2.SolverParameter()path='/home/xxx/data/'solver_file=path+'solver1.prototxt's.train_net = path+'train.prototxt's.test_net.append(path+'val.prototxt')s.test_interval = 782 s.test_iter.append(313) s.max_iter = 78200 s.base_lr = 0.001 s.momentum = 0.9s.weight_decay = 5e-4s.lr_policy = 'step's.stepsize=26067s.gamma = 0.1s.display = 782s.snapshot = 7820s.snapshot_prefix = 'shapshot's.type = “SGD”s.solver_mode = caffe_pb2.SolverParameter.GPUwith open(solver_file, 'w') as f: f.write(str(s)) Training models (training)If you don't visualize , Just want to get a final workout model, So the code is very simple , as follows :
import caffecaffe.set_device(0)caffe.set_mode_gpu()solver = caffe.SGDSolver('/home/xxx/data/solver.prototxt')solver.solve()That's all caffe Of python Interface generation solver The document explains the details of the study , More about caffe python Interface generation solver Please pay attention to other relevant articles of the software development network for the information of the document !