numpy:處理數值數據
pandas:字符串,時間數據等
Pandas是一個強大的分析結構化數據的工具集,基於Numpy構建,提供了高級數據結構和數據操作工作
1、基礎是numpy,提供了高效性能矩陣的運算;
2、提供數據清洗功能
3、應用於數據挖掘,數據分析
4、提供了大量能快速便捷地處理數據的函數和方法
Series:是一種一維標記的數據型對象,能夠保存任何數據類型(int,str,float,python object),包含了數據標簽,稱為索引

(1)通過列表創建
# 1、通過list創建
s1 = pd.Series([1,2,3,4,5])
s1

(2)通過數組創建
# 2、通過數組創建
arr1= np.arange(1,6)
s2 = pd.Series(arr1)
print(s2)

(3)通過字典創建
# 3、通過字典創建
dict = {
'name':'李寧','age':18,'class':'三班'}
s3 = pd.Series(dict,index = ['name','age','class','sex'])
s3

(1)空值判斷
# isnull和not null檢測缺失值
s3.isnull()
(2)獲取數據
獲取數據方式:索引,下標,標簽名
# 1、索引獲取數據
print(s3.index)
print(s3.values)
# 2、下標獲取數據
print(s3[1:3])
# 3、標簽名獲取數據
print(s3['age':'class'])

標簽切片和下標切片的區別
標簽切片:包含末端數據
索引切片:不包含末端數據
(3)索引與數據的對應關系
索引和數據的對應關系不被運算結果影響
(4)name屬性
s3.name = "temp" #對象名
s3.index.name = 'values' #對象索引名
s3

DataFrame是一個表格型的數據結構,它含有一組有序的列,每列可以是不同類型的索引值,DataFrame既有行索引也有列索引,它可以被看作是由series組成的字典,數據以二維結構存放
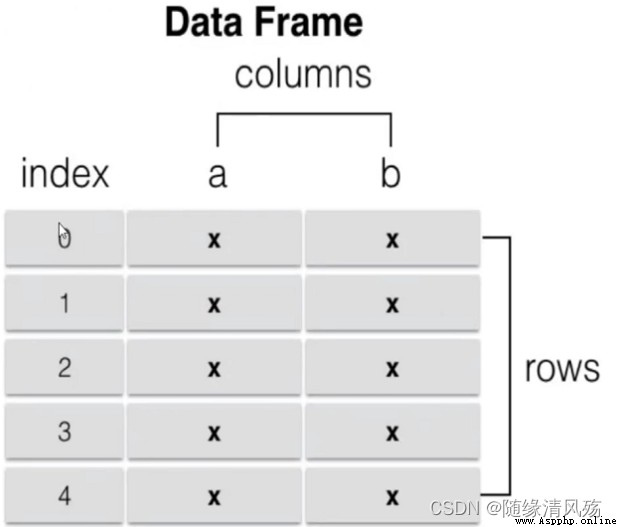
# 數組、列表或元組構成的字典構造DataFrame
data = {
'a':[1,2,3,4],
'b':(5,6,7,8),
'c':np.arange(9,13)}
frame = pd.DataFrame(data)
# 相關屬性
print(frame.index)
print(frame.columns)
print(frame.values)

1、Series和DataFrame中的索引都是index對象
2、索引對象不可改變,保證數據安全
ps = pd.Series(range(5))
pd = pd.DataFrame(np.arange(9).reshape(3,3),index = ['a','b','c'],columns = ['A','B','C'])
type(ps.index)
常見索引類型
:1、Index - 索引
:2、Inet64index - 整數索引
:3、MultiIndex - 層級索引
:4、DatetiemIndex - 時間戳索引
(1)重新索引
reindex:將索引重新排序,創建一個符合新索引的新對象
s = pd.Series(np.random.randn(5),index=['a','b','c','d','e'])
print(s)
s.reindex(['e','b','f','d'])

(2)增
1、在原有數據結構上增加數據
2、在新建數據結構上增加數據
s = pd.Series(np.random.randn(5),index=['a','b','c','d','e'])
s['f'] = 100
print(s)

import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(1,10).reshape(3,3),index=['a','b','c'],columns = ['A1','B1','C1'])
print(df)
print("======")
df['D1'] = np.arange(100,103)
df2 = df
print(df2)
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(1,10).reshape(3,3),index=['a','b','c'],columns = ['A1','B1','C1'])
print(df)
print("======")
df.loc['d'] = np.arange(100,103)
df2 = df
print(df2)

(3)刪
1、del:刪除,會更改原有結構
2、drop:刪除軸上數據,產生新的對象
# 刪除
ps = pd.Series(np.random.randn(5),index=['a','b','c','d','e'])
del ps['e']
print(ps)
ps2 = ps.drop(['a','b'])
print(ps2)
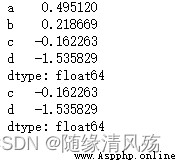
import numpy as np
import pandas as pd
pd = pd.DataFrame(np.random.randn(9).reshape(3,3),columns=['a','b','c'])
print(pd)
# 刪除列
pd1 = pd.drop(['c'],axis=1)
print(pd1)
# 刪除行
pd2 = pd.drop(2)
print(pd2)

(4)改
1、修改列:對象.索引,對象.列
2、修改行:標簽索引loc
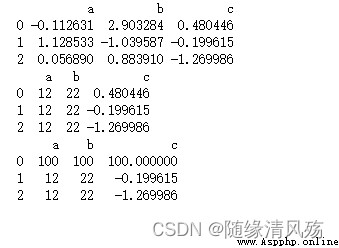
import numpy as np
import pandas as pd
pd = pd.DataFrame(np.random.randn(9).reshape(3,3),columns=['a','b','c'])
print(pd)
# 修改列
pd['a'] = 12
pd.b = 22
print(pd)
# 修改行
pd.loc[0] = 100
print(pd)
(5)查
1、行索引
2、切片索引:位置切片,標簽切片
3、不連續索引
import numpy as np
import pandas as pd
ps = pd.Series(np.random.randn(5),index=['a','b','c','d','e'])
# 行索引
print(ps['a'])
# 位置切片索引
print(ps[1:3])
# 標簽切片索引,包含終止索引
print(ps['a':'c'])
# 不連續索引
print(ps[['a','c']])
# 布爾索引
print(ps[ps>0])
1、loc標簽索引:基於標簽名的索引 pd.loc[2:3,'a']
2、iloc位置索引:基於索引編號索引
3、ix標簽與位置混合索引:知道就行
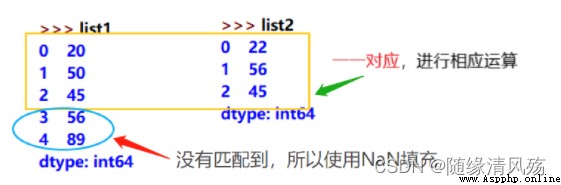
import numpy as np
import pandas as pd
pd = pd.DataFrame(np.random.randn(9).reshape(3,3),index = [7,8,9],columns=['a','b','c'])
# 標簽索引 - 第一個參數索引行,第二個參數是列
print(pd.loc[7:8,'a'])
# 位置索引 - 兩個參數,行列
print(pd.iloc[0:2,0:2])

import numpy as np
import pandas as pd
s1 = pd.Series(np.arange(5),index=['a','b','c','d','e'])
s2 = pd.Series(np.arange(5,10),index=['a','b','c','d','e'])
print(s1)
print(s2)
print(s1+s2)

DataFrame和Series混合運算:Series的行索引匹配DataFrame的列索引進行廣播運算,index屬性可沿列運算
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(9).reshape(3,3),index = ['A','B','C'],columns=['A','B','C'])
ds = df.iloc[0]
# 行運算,列廣播
print(df-ds)
# 列運算,行廣播
df.sub(ds,axis = 'index')

運算規則:索引匹配運算
(1)apply函數
apply:將函數應用到行或列
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(9).reshape(3,3),index = ['A','B','C'],columns=['A','B','C'])
f = lambda x:x.max()
# 應用在行上,進行列運算
print(df.apply(f))
# 應用在列上,進行行運算
print(df.apply(f,axis=1))

(2)applymap函數
applymap:將函數應用到每個數據
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(9).reshape(3,3),index = ['A','B','C'],columns=['A','B','C'])
f = lambda x:x**2
print(df.applymap(f))

(3)排序
索引排序:sort_index(ascending,axis)
按值排序:sort_values(by,sacending,axis)
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(9).reshape(3,3),index = ['B','D','C'],columns=['A','C','B'])
# 按行索引排序
print(df.sort_index(ascending=False,axis=1))
# 按列值進行排序
print(df.sort_values(by = 'A'))

(4)唯一值和成員屬性
(5)處理缺失值
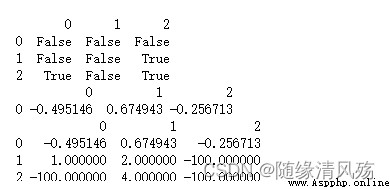
import pandas as pd
import numpy as np
df = pd.DataFrame([np.random.randn(3),[1,2,np.nan],[np.nan,4,np.nan]])
# 1、判斷是否存在缺失值
print(df.isnull())
# 2、丟棄缺失數據,默認丟棄行
print(df.dropna())
# 3、填充缺失數據
print(df.fillna(-100))
層級索引**:在輸入索引Index時,輸入了由兩個子list組成的list,第一個子list是外層索引,第二個list是內層索引。**
作用:通過層級索引配合不同等級的一級索引使用,可以將高維數組轉化為Series或DataFrame對向形式
范例
import pandas as pd
import numpy as np
ser_obj = pd.Series(np.random.randn(12),index=[
['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c', 'd', 'd', 'd'],
[0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2]
])
# 選取子集
''' 根據索引獲取數據。因為現在有兩層索引,當通過外層索引獲取數據的時候,可以直接利用外層索引的標簽來獲取。 當要通過內層索引獲取數據的時候,在list中傳入兩個元素,前者是表示要選取的外層索引,後者表示要選取的內層索引。 '''
print(ser_obj['a',1])
# 交換內外層
print(ser_obj.swaplevel())

統計計算:默認按列計算
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(32).reshape(8,4))
# 選取
df.sum()

平均數:np.mean()
總和:np.sum()
中位數:np.median()
最大值:np.max()
最小值:np.min()
頻次(計數): np.size()
方差:np.var()
標准差:np.std()
乘積:np.prod()
協方差: np.cov(x, y)
偏度系數(Skewness): skew(x)
峰度系數(Kurtosis): kurt(x)
正態性檢驗結果: normaltest(np.array(x))
四分位數:np.quantile(q=[0.25, 0.5, 0.75], interpolation=“linear”)
四分位數:describe() – 顯示25%, 50%, 75%位置上的數據
相關系數矩陣(Spearman/ Person/ Kendall)相關系數: x.corr(method=“person”))
讀取csv文件read_csv(file_path or buf,usecols,encoding):file_path:文件路徑,usecols:指定讀取的列名,encoding:編碼
范例
data = pd.read_csv('D:/jupyter_notebook/bfms_w2_out.csv',encoding='utf8')
data.head()
pd.merge:(left, right, how='inner',on=None,left\_on=None, right\_on=None \)
left:合並時左邊的DataFrame
right:合並時右邊的DataFrame
how:合並的方式,默認'inner', 'outer', 'left', 'right'
on:需要合並的列名,必須兩邊都有的列名,並以 left 和 right 中的列名的交集作為連接鍵
left\_on: left Dataframe中用作連接鍵的列
right\_on: right Dataframe中用作連接鍵的列
* 內連接 inner:對兩張表都有的鍵的交集進行聯合
import pandas as pd
import numpy as np
left = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left,right,on='key') #指定連接鍵key

concat:可指定軸進行橫向或者縱向合並
df1 = pd.DataFrame(np.arange(6).reshape(3,2),index=list('abc'),columns=['one','two'])
df2 = pd.DataFrame(np.arange(4).reshape(2,2)+5,index=list('ac'),columns=['three','four'])
print(df1)
print(df2)
pd.concat([df1,df2],axis='columns') #指定axis=1連接

stack:stack函數會將數據從”表格結構“變成”花括號結構“,即將其行索引變成列索引
unstack:unstack函數將數據從”花括號結構“變成”表格結構“,即要將其中一層的列索引變成行索引。

import numpy as np
import pandas as pd
df_obj = pd.DataFrame(np.random.randint(0,10, (5,2)), columns=['data1', 'data2'])
print(df_obj)
print("stack")
stacked = df_obj.stack()
print(stacked)
print("unstack")
# 默認操作內層索引
print(stacked.unstack())
# 通過level指定操作索引的級別
print(stacked.unstack(level=0))