#獲取當前時間戳
t1 = time.time()
a = []
for x in range(1000000):
a.append(x**2)
t2 = time.time()
print(t2-t1)

t3 = time.time()
b = np.arange(1000000)**2
t4 = time.time()
print(t4-t3)
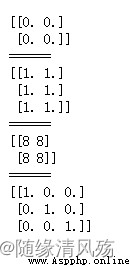
b = np.array([1,2,3,4])
print(b)
print(type(b))

arr2 = np.arange(0,10,2)
print(arr2)
print(type(arr2))

arr3 = np.random.random(10)
print(arr3)
print(type(arr3))

a1 = np.zeros((2,2))
a2 = np.ones((3,2))
a3 = np.full((2,2),8) #生成一個所有元素都是8的2行2列的數組
a4 = np.eye(3) #生成一個在斜方形上元素為1,其余元素為0的3*3的矩陣
print(a1)
print(a2)
print(a3)
print(a4)
bool,int8,int16,int32,int64,uint8,uint16,uint32,uint64
object_,string_,unicode_
c = np.array([1,2,3,4],dtype=np.float16)
print(c)
print(c.dtype)

import numpy as np
a1 = np.array([1,2,3])
print(a1.dtype) # windows下默認為int32
a2 = a1.astype(np.int8) #astype不會修改數組本身,二十返回修改數據結果
print(a2)

shape:查看數組維度
ndim:查看數組維度
size:查看數組元素個數
itemsize:查看數組中每個元素所占大小,單位是字節
a1 = np.array([1,2,3,4])
a2 = np.array([[1,2,3,4],[5,6,7,8]])
a3 = np.array([[[1,2,3,4],[1,2,3,4]],[[1,2,3,4],[1,2,3,4]]])
print(a1.shape)
print(a2.shape)
print(a3.shape)

reshape:維度轉換,不會修改數組本身
resize:維度轉換,會修改數組本身
flatten:維度轉換成一維,返回原數組副本
ravel:維度轉換為一維,返回原數組引用
a4 = a3.reshape((4,4))
print(a4)
print(a4.shape)

a1 = np.random.randint(0,5,size=(3,2,2))
a2 = np.random.randint(0,5,size=(2,2))
print(a1.flatten())
print("========")
print(a1)
print("========")
print(a2.ravel())
print("========")
print(a2)
print("========")
print(a1+a2)
a5 = a3.reshape((16,))
print(a5)
print(a5.shape)

arr1 = np.arange(0,6).reshape(2,3)
arr2 = np.arange(6,12).reshape(2,3)
print(arr1+arr2)

1、數組一般達到三維就已經很復雜了,不太方便計算,所以我們一般都會把3維以上的數組轉換成2維數組來計算
2、ndarray.ndim:查看數組維度
3、ndarray.shape:查看數組形狀,shape是一個元組,裡面有幾個元素代表幾維數組
4、ndarray.reshape:修改數組的形狀,修改前後的元素總數必須一致
5、ndarray.size:看到數組總共元素個數
6、ndarray.itemsize:查看數組每個元素所占內存大小
包括:[起始位置:結束位置:步長]
a6 = np.arange(10)
print(a6)
print(a6[1])
print(a6[0:4])
print(a6[0:6:2])
print(a6[::-1])

多維數組:
中括號一個值:代表行
中括號兩個值:逗號分隔,都好前面是行,逗號後面是列,結果為一維數組
a7 = np.random.randint(0,10,size=(4,6))
print(a7)
print("============")
print(a7[1])
print("============")
print(a7[0:2])
print("============")
print(a7[[0,2,3]])
print("============")
print(a7[0:2,0])

布爾索引:<,>,<=,>=,==,!=,&,|
a8 = [(a7 < 5) & (a7>3)]
print(a8)
print("============")
print(a7[a8])

布爾索引:通過相同數組上的True還是False來進行提取
提取條件多個: & 代表且, | 代表或, 每個條件都要用圓括號括起來
a7[a7 < 3] = 1
a7

np.where(條件,0,1)
result = np.where(a7 > 5 ,0,1)
result

a1 = np.arange(10).reshape(2,5)
print(a1)
a2 = a1 + 10
print(a2)

(1)相同結構運算
直接相加
a1 = np.arange(10).reshape(2,5)
print(a1)
print("=======")
a2 = a1 + 10
print(a2)
print("=======")
a3 = a1 + a2
print(a3)
print("=======")

(2)不同結構運算
1、兩數組其中一方長度為1,則廣播兼容
2、兩數組從末尾開始算起的維度的軸長度相符,則廣播兼容
a1 = np.random.randint(0,5,size=(3,8,2))
a2 = np.random.randint(0,5,size=(8,1))
print(a1)
print("========")
print(a2)
print("========")
print(a1+a2)

a1 = np.random.randint(0,5,size=(3,2,2))
a2 = np.random.randint(0,5,size=(2,2))
print(a1)
print("========")
print(a2)
print("========")
print(a1+a2)
(1)垂直方向疊加
vstack:數組垂直方向疊加,
前提條件:數組列數必須相同
a1 = np.random.randint(0,5,size=(2,2))
a2 = np.random.randint(0,5,size=(2,2))
a3 = np.vstack([a1,a2])
print(a3)

(2)水平方向疊加
hstack:將數組按水平方向疊加
前提條件:數組的行必須相同才能疊加
a1 = np.random.randint(0,5,size=(2,2))
a2 = np.random.randint(0,5,size=(2,2))
a3 = np.hstack([a1,a2])
print(a3)

(3)手動指定
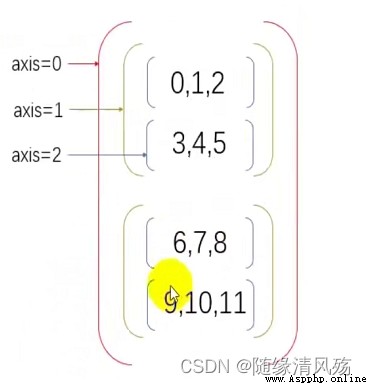
concatenate:將兩個數組進行疊加,具體方向看參數axis
a1 = np.random.randint(0,5,size=(2,2))
a2 = np.random.randint(0,5,size=(2,2))
a3 = np.concatenate([a1,a2],axis=None)
a4 = np.concatenate([a1,a2],axis=1)
a5 = np.concatenate([a1,a2],axis=0)
print(a3)
print(a4)
print(a5)

(1)水平切割
hsplit:水平切割
a1 = np.random.randint(0,5,size=(2,2))
np.hsplit(a1,2)

(2)垂直切割
vsplit:按照垂直方向進行分割
a1 = np.random.randint(0,5,size=(2,2))
np.vsplit(a1,2)
(3)指定方向
split:指定方向切割,參數axis0為行,1為列
a1 = np.random.randint(0,5,size=(2,2))
a2 = np.split(a1,2,axis=0)
print(a2)
a3 = np.split(a1,2,axis=1)
print(a3)

轉置:矩陣內積計算
a1 = np.random.randint(0,5,size=(2,2))
print(a1)
print("=====")
print(a1.T)
print("=====")
print(a1.dot(a1.T))

不拷貝:簡單賦值不會拷貝
淺拷貝:變量拷貝,所指向內存空間相同
深拷貝:
a = np.random.randint(0,5,size=(2,2))
b = a
print(b is a)
print("======")
c = a.view()
print(c is a)
c[[0],[0]] = 100
print(c)
print(a)
print("======")
d = a.copy()
d[[1],[1]] = 10
print(d)
print(a)

numpy文件格式:npy或者npz結尾
np.savetxt:保存文件格式,頂部標記,分隔符
a = np.random.randint(0,100,size=(4,4))
np.savetxt("a.csv",a,delimiter=",",header="a,b,c,d")

np.loadtxt:數據類型,分隔符,跳行
data = np.loadtxt("b.csv",delimiter=",")
data

np.load:讀取非文本文件格式,可用於三維數組以上
np.load("a.npy")

np.save:保存非文本文件格式,可用於三維數組以上
a = np.random.randint(0,100,size=(4,4,4))
np.save("a.npy",a)

with open(文件名稱,讀,編碼方式) as 對象名稱:
reader = csv.reader(fp)
reader = csv.DictReader(fp)
CSV文件特征
:1、純文本,使用某個字符集,比如ASCII、Unicode
:2、由記錄組成
:3、每條記錄被分割符分割為字段(典型分隔符有逗號,分號,制表符)
:4、每條字段有同樣的字段序列
import csv
with open('b.csv','r') as fp:
#reader是一個迭代器
reader = csv.reader(fp)
#next取出第一個指針指向的數據,之後下移
titles = next(reader)
print(titles)
print("=========")
for x in reader:
print(x)
print("========")
a = x[0]
b = x[1]
print(a+b+"結果")

with open("b.csv",'r') as fp:
reader = csv.DictReader(fp)
for x in reader:
print(x)

with open(文件名稱,寫入,編碼格式):
writer = csv.writer(fp)
writer.writerow #寫入一行
writer.writerows #寫入多行
headers = {
"username","age","height"}
values = [('張三',18,200),('李四',19,180)]
with open('c.csv','w',encoding='utf-8') as fp:
writer = csv.writer(fp)
writer.writerow(headers)
writer.writerows(values)

NAN:Not A Number,不是一個數字,屬於浮點類型
INF:Infinity,代表無窮大,除數為0時出現,也是與浮點類型
:1、NAN和NAN不相等,比如np.NAN 1= np.NAN這個條件是成立的
:2、NAN和任何值做運算,結果都是NAN
(1)刪除缺失值
data[~np.isnan(data)] :刪除空值,將數組轉換為一維數組
np.delete(data,np.where(np.isnan(data))[0],axis=0) :刪除為NAN的行
import numpy as np
# 1、刪除所有NAN的值,因為刪除了值後數組不知道怎麼變化,所以會變成一維數組
data = np.random.randint(0,10,size = (3,5)).astype(np.float)
data[0:1] = np.nan
data = data[~np.isnan(data)]
print(data)

import numpy as np
# 1、刪除所有NAN的值,因為刪除了值後數組不知道怎麼變化,所以會變成一維數組
data = np.random.randint(0,10,size = (3,5)).astype(np.float)
#將0,1和1,2兩個值設置為NAN
data[[0,1],[1,2]] = np.nan
#獲取那些行有NAN
lines = np.where(np.isnan(data))[0]
#使用delete方法刪除指定的行,axis = 0表示刪除,lines表示刪除的符號
data1 = np.delete(data,lines,axis=0)
print(data1)

(2)用其他值進行替換
1、將空值替換為0
2、將空值替換為均值
#CSV文件空缺值為空字符串,讀取時限定字符串格式
scores = np.loadtxt("學習成績.csv",delimiter = ',',encoding='utf-8',skiprows=1,dtype=np.str)
# 將空字符串轉換為NAN
scores[scores == ""] = np.NAN
scores.astype(np.float)
# 將字符串全部轉換為浮點類型
scores.astype(np.float)
查詢結果
注意事項
讀取CSV文本中的空值:
:1、先以字符串類型讀取,
:2、空字符串轉換為NAN
:3、將字符串轉換為浮點類型
(1)隨機數種子seed
相同seed值:每次生成的隨機數都相同
不設置seed值:根據系統時間選擇這個值
np.random.seed(1)
print(np.random.rand()) #打印固定值
print(np.random.rand()) #打印其他值,因為隨機數種子只對下一次隨機數的產生有影響
(2)隨機數數組
print(np.random.rand(2,3,4)) #生成兩塊3行4列的數組,值在0-1之間

(3)隨機數數組 - 標准正態分布
print(np.random.randn(2,3)) #生成一個2行3列的數組,數組中的值都滿足正態分布

(4)隨機數數組 - 指定范圍
print(np.random.randint(10,size=(3,6)))

(5)隨機采樣
前提條件:必須是一維數組
data = [1,2,3,4,5,6,7,8,9,10]
result1 = np.random.choice(data,3)
result2 = np.random.choice(data,size=(2,2))
print(result1)
print("========")
print(result2)

data = np.random.randint(10,size=(3,4))
print(np.any(data == 5))
print(np.all(data == 5))

data = np.random.randint(10,size=(3,4))
data1 = np.sort(data)
data2 = np.sort(data,axis=0)
data3 = np.argsort(data)
print(data1)
print("========")
print(data2)
print("========")
print(data3)
print("========")