https://mydreamambitious.blog.csdn.net/article/details/125459959
對於了解目前這篇文章(YOLO-V3實時檢測實現),讀者只要了解下面給出的知識點,即可,不需要太關心論文中的細節。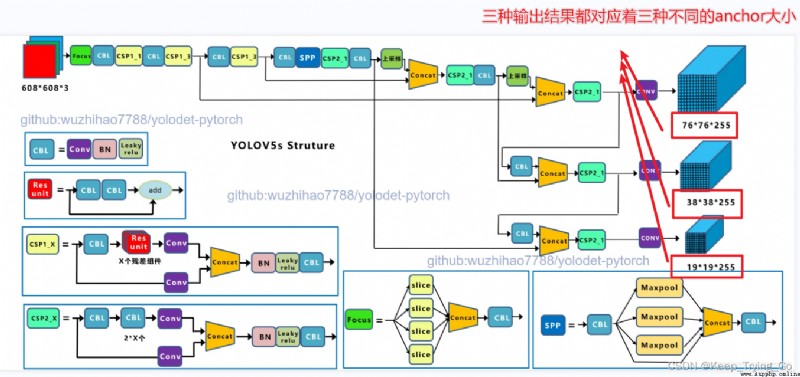



表的來源:https://blog.csdn.net/qq_37541097/article/details/81214953
圖片來源:圖片地址
https://pjreddie.com/darknet/yolo/
https://github.com/pjreddie/darknet/blob/master/data/coco.names
https://github.com/pjreddie/darknet
下載之後如下:
YOLO-V3輸出的結果形式;知道了輸出結果的形式,對於後面獲取預測結果的預測框的坐標(x,y),高寬(w,h),置信度(confidence)以及預測類別的概率很有幫助(這些值是最後的輸出結果,所以需要映射回原來的圖像)。
#讀取網絡配置文件和權重文件
net=cv2.dnn.readNet(model='dnn_model/yolov3.weights',
config='dnn_model/yolov3.cfg')
#由yolo-v3的結構可知,最終有三個尺度的輸出
layerName=net.getLayerNames()
#存儲輸出的三個尺度名稱,用於後面進行前向推斷的
ThreeOutput_layers_name=[]
for i in net.getUnconnectedOutLayers():
ThreeOutput_layers_name.append(layerName[i-1])
#因為yolo-v3中檢測包含80個類別,所以首先獲取類別
with open('dnn_model/coco.names','r') as fp:
classes=fp.read().splitlines()
#指定過濾的置信度阈值:confidence
Confidence_thresh=0.2
#指定非極大值抑制的值:對候選框進行篩選
Nms_thresh=0.35
# 參數情況:圖像 ,歸一化,縮放的大小,是否對RGB減去一個常數,R和B交換(因為R和B是反著的,所以需要交換),是否裁剪
blob = cv2.dnn.blobFromImage(frame, 1 / 255, (416, 416), (0, 0, 0), swapRB=True, crop=False)
#獲取圖像的高寬
height,width,channel=frame.shape
#設置網絡輸入
net.setInput(blob)
#進行前向推斷:采用的最後三個尺度輸出層作為前向推斷
predict=net.forward(ThreeOutput_layers_name)
# 存放預測框的坐標
boxes = []
#存在預測物體的置信度
confid_object=[]
#存放預測的類別
class_prob=[]
#存放預測物體的id
class_id=[]
#存放預測類別的名稱
class_names=[]
#根據輸出的是三個尺度,所以分別遍歷三個尺度
for scale in predict:
for box in scale:
#獲取坐標值和高寬
#首先獲取矩形中心坐標值(這裡需要映射回原圖)
center_x=int(box[0]*width)
center_y=int(box[1]*height)
#計算框的高寬
w=int(box[2]*width)
h=int(box[3]*height)
#獲取矩形框的左上角坐標
left_x=int(center_x-w/2)
left_y=int(center_y-h/2)
boxes.append([left_x,left_y,w,h])
#獲取檢測物體的置信度
confid_object.append(float(box[4]))
#獲取概率最大值
#首先獲取最高值概率的下標
index=np.argmax(box[5:])
class_id.append(index)
class_names.append(classes[index])
class_prob.append(box[index])
confidences=np.array(class_prob)*np.array(confid_object)
#計算非極大值抑制
all_index=cv2.dnn.NMSBoxes(boxes,confidences,Confidence_thresh,Nms_thresh)
#遍歷,繪制矩形框
for i in all_index.flatten():
x,y,w,h=boxes[i]
#四捨五入,保留2位小數
confidence=str(round(confidences[i],2))
#繪制矩形框
cv2.rectangle(img=frame,pt1=(x,y),pt2=(x+w,y+h),
color=(0,255,0),thickness=2)
text=class_names[i]+' '+confidence
cv2.putText(img=frame,text=text,org=(x,y-10),
fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=1.0,color=(0,0,255),thickness=2)
#單張圖片的檢測
def signa_Picture(image_path='images/smile.jpg'):
img=cv2.imread(image_path)
img=cv2.resize(src=img,dsize=(416,416))
dst=Forward_Predict(img)
cv2.imshow('detect',dst)
key=cv2.waitKey(0)
if key==27:
exit()
#實時的檢測
def detect_time():
cap=cv2.VideoCapture(0)
while cap.isOpened():
OK,frame=cap.read()
if not OK:
break
#將圖片進行一下翻轉,因為Opencv讀取的圖片和我們正常是反著的
frame=cv2.flip(src=frame,flipCode=2)
frame=cv2.resize(src=frame,dsize=(416,416))
dst=Forward_Predict(frame)
cv2.imshow('detect',dst)
key=cv2.waitKey(1)
if key==27:
break
cap.release()
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取網絡配置文件和權重文件
net=cv2.dnn.readNet(model='dnn_model/yolov3.weights',
config='dnn_model/yolov3.cfg')
#由yolo-v3的結構可知,最終有三個尺度的輸出
layerName=net.getLayerNames()
#存儲輸出的三個尺度名稱,用於後面進行前向推斷的
ThreeOutput_layers_name=[]
for i in net.getUnconnectedOutLayers():
ThreeOutput_layers_name.append(layerName[i-1])
#因為yolo-v3中檢測包含80個類別,所以首先獲取類別
with open('dnn_model/coco.names','r') as fp:
classes=fp.read().splitlines()
#指定過濾的置信度阈值:confidence
Confidence_thresh=0.2
#指定非極大值抑制的值:對候選框進行篩選
Nms_thresh=0.35
#檢測的過程已經圖形的繪制
def Forward_Predict(frame):
# 參數情況:圖像 ,歸一化,縮放的大小,是否對RGB減去一個常數,R和B交換(因為R和B是反著的,所以需要交換),是否裁剪
blob = cv2.dnn.blobFromImage(frame, 1 / 255, (416, 416), (0, 0, 0), swapRB=True, crop=False)
#獲取圖像的高寬
height,width,channel=frame.shape
#設置網絡輸入
net.setInput(blob)
#進行前向推斷:采用的最後三個尺度輸出層作為前向推斷
predict=net.forward(ThreeOutput_layers_name)
# 存放預測框的坐標
boxes = []
#存在預測物體的置信度
confid_object=[]
#存放預測的類別
class_prob=[]
#存放預測物體的id
class_id=[]
#存放預測類別的名稱
class_names=[]
#根據輸出的是三個尺度,所以分別遍歷三個尺度
for scale in predict:
for box in scale:
#獲取坐標值和高寬
#首先獲取矩形中心坐標值(這裡需要映射回原圖)
center_x=int(box[0]*width)
center_y=int(box[1]*height)
#計算框的高寬
w=int(box[2]*width)
h=int(box[3]*height)
#獲取矩形框的左上角坐標
left_x=int(center_x-w/2)
left_y=int(center_y-h/2)
boxes.append([left_x,left_y,w,h])
#獲取檢測物體的置信度
confid_object.append(float(box[4]))
#獲取概率最大值
#首先獲取最高值概率的下標
index=np.argmax(box[5:])
class_id.append(index)
class_names.append(classes[index])
class_prob.append(box[index])
confidences=np.array(class_prob)*np.array(confid_object)
#計算非極大值抑制
all_index=cv2.dnn.NMSBoxes(boxes,confidences,Confidence_thresh,Nms_thresh)
#遍歷,繪制矩形框
for i in all_index.flatten():
x,y,w,h=boxes[i]
#四捨五入,保留2位小數
confidence=str(round(confidences[i],2))
#繪制矩形框
cv2.rectangle(img=frame,pt1=(x,y),pt2=(x+w,y+h),
color=(0,255,0),thickness=2)
text=class_names[i]+' '+confidence
cv2.putText(img=frame,text=text,org=(x,y-10),
fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=1.0,color=(0,0,255),thickness=2)
return frame
#實時的檢測
def detect_time():
cap=cv2.VideoCapture(0)
while cap.isOpened():
OK,frame=cap.read()
if not OK:
break
#將圖片進行一下翻轉,因為Opencv讀取的圖片和我們正常是反著的
frame=cv2.flip(src=frame,flipCode=2)
frame=cv2.resize(src=frame,dsize=(416,416))
dst=Forward_Predict(frame)
cv2.imshow('detect',dst)
key=cv2.waitKey(1)
if key==27:
break
cap.release()
#單張圖片的檢測
def signa_Picture(image_path='images/smile.jpg'):
img=cv2.imread(image_path)
img=cv2.resize(src=img,dsize=(416,416))
dst=Forward_Predict(img)
cv2.imshow('detect',dst)
key=cv2.waitKey(0)
if key==27:
exit()
cv2.destroyAllWindows()
if __name__ == '__main__':
print('Pycharm')
# signa_Picture()
detect_time()

yolov3視頻演示