資源下載地址:https://download.csdn.net/download/sheziqiong/85820698
資源下載地址:https://download.csdn.net/download/sheziqiong/85820698
在python官網https://www.python.org/downloads/ 下載計算機對應的python版本,本人使用的是Python2.7.13的版本。
本實例代碼的實現使用到了多個著名的第三方模塊,主要模塊如下所示:
本文使用中科院計算所中文自然語言處理開放平台發布的中文停用詞表,包含了1208個停用詞。下載地址:http://www.hicode.cc/download/view-software-13784.html
文本從http://www.datatang.com/data/11936 下載“有關中文情感挖掘的酒店評論語料”作為訓練集與測試集,該語料包含了4種語料子集,本文選用正負各1000的平衡語料(ChnSentiCorp_htl_ba_2000)作為數據集進行分析。
下載並解壓ChnSentiCorp_htl_ba_2000.rar文件,得到的文件夾中包含neg(負向語料)和pos(正向語料)兩個文件夾,而文件夾中的每一篇評論為一個txt文檔,為了方便之後的操作,需要把正向和負向評論分別規整到對應的一個txt文件中,即正向語料的集合文檔(命名為2000_pos.txt)和負向語料的集合文檔(命名為2000_neg.txt)。
具體Python實現代碼如下所示:
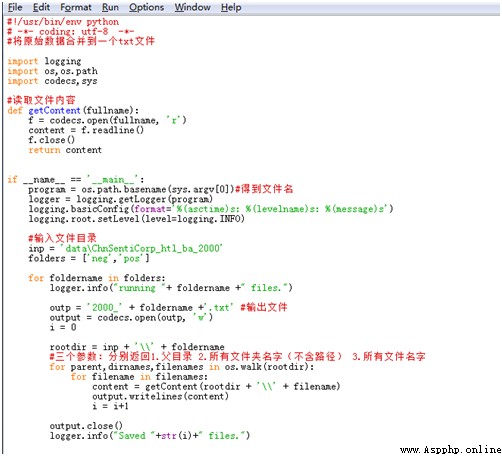
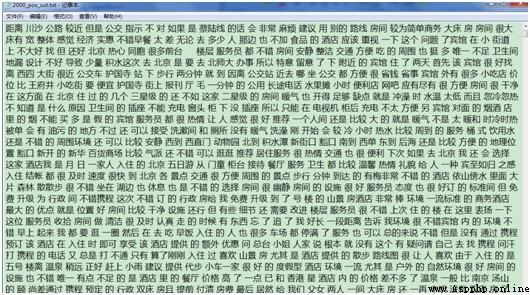
運行完成後得到2000_pos.txt和2000_neg.txt兩個文本文件,分別存放正向評論和負向評論,每篇評論為一行。文檔部分截圖如下所示:

本文采用結巴分詞分別對正向語料和負向語料進行分詞處理。特別注意,在執行代碼前需要把txt源文件手動轉化成UTF-8格式,否則會報中文編碼的錯誤。在進行分詞前,需要對文本進行去除數字、字母和特殊符號的處理,使用python自帶的string和re模塊可以實現,其中string模塊用於處理字符串操作,re模塊用於正則表達式處理。
具體實現代碼如下所示:
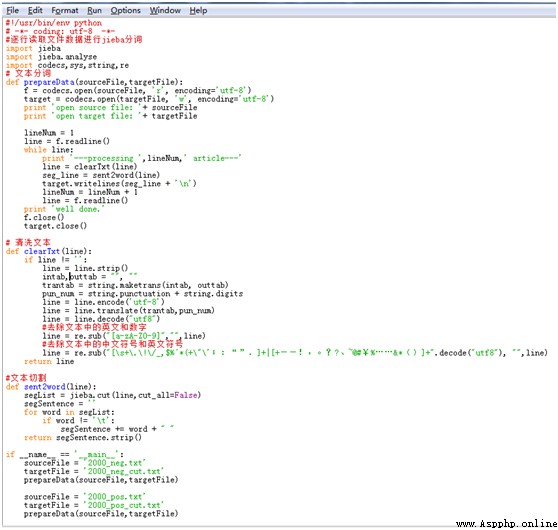
處理完成後,得到2000_pos_cut.txt和2000_neg_cut.txt兩個txt文件,分別存放正負向語料分詞後的結果。分詞結果部分截圖如下所示:
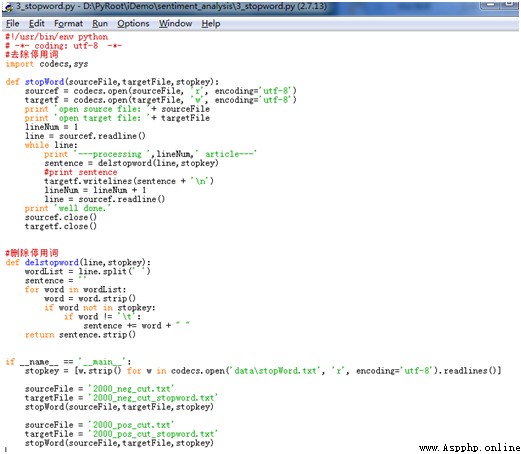
分詞完成後,即可讀取停用詞表中的停用詞,對分詞後的正負向語料進行匹配並去除停用詞。去除停用詞的步驟非常簡單,主要有兩個:
具體實現代碼如下所示:
根據代碼所示,停用詞表的獲取使用到了python特有的廣播形式,一句代碼即可搞定:
stopkey = [w.strip() for w in codecs.open('data\stopWord.txt', 'r', encoding='utf-8').readlines()]
讀取出的每一個停用詞必須要經過去符號處理即w.strip(),因為讀取出的停用詞還包含有換行符和制表符,如果不處理則匹配不上。代碼執行完成後,得到2000_neg_cut_stopword.txt和2000_pos_cut_stopword.txt兩個txt文件。
由於去停用詞的步驟是在句子分詞後執行的,因此通常與分詞操作在同一個代碼段中進行,即在句子分詞操作完成後直接調用去停用詞的函數,並得到去停用詞後的結果,再寫入結果文件中。本文是為了便於步驟的理解將兩者分開為兩個代碼文件執行,各位可根據自己的需求進行調整。
根據以上步驟得到了正負向語料的特征詞文本,而模型的輸入必須是數值型數據,因此需要將每條由詞語組合而成的語句轉化為一個數值型向量。常見的轉化算法有Bag of Words(BOW)、TF-IDF、Word2Vec。本文采用Word2Vec詞向量模型將語料轉換為詞向量。
由於特征詞向量的抽取是基於已經訓練好的詞向量模型,而wiki中文語料是公認的大型中文語料,本文擬從wiki中文語料生成的詞向量中抽取本文語料的特征詞向量。Wiki中文語料的Word2vec模型訓練在之前寫過的一篇文章“利用Python實現wiki中文語料的word2vec模型構建” 中做了詳盡的描述,在此不贅述。即本文從文章最後得到的wiki.zh.text.vector中抽取特征詞向量作為模型的輸入。
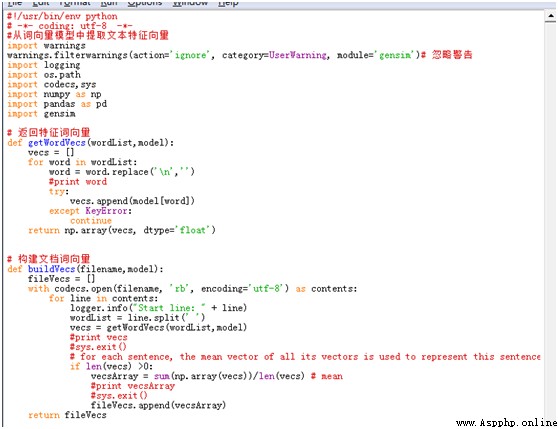
獲取特征詞向量的主要步驟如下:
主要代碼如下圖所示:
代碼執行完成後,得到一個名為2000_data.csv的文件,第一列為類別對應的數值(1-pos, 0-neg),第二列開始為數值向量,每一行代表一條評論。結果的部分截圖如下所示:

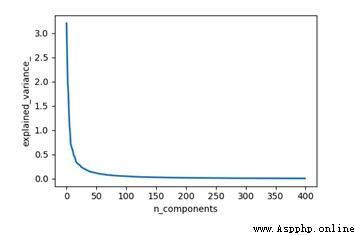
Word2vec模型設定了400的維度進行訓練,得到的詞向量為400維,本文采用PCA算法對結果進行降維。具體實現代碼如下所示:

運行代碼,根據結果圖發現前100維就能夠較好的包含原始數據的絕大部分內容,因此選定前100維作為模型的輸入。
本文采用支持向量機(SVM)作為本次實驗的中文文本分類模型,其他分類模型采用相同的分析流程,在此不贅述。
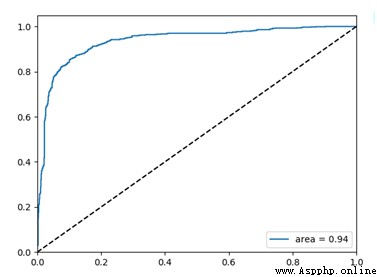
支持向量機(SVM)是一種有監督的機器學習模型。本文首先采用經典的機器學習算法SVM作為分類器算法,通過計算測試集的預測精度和ROC曲線來驗證分類器的有效性,一般來說ROC曲線的面積(AUC)越大模型的表現越好。
首先使用SVM作為分類器算法,隨後利用matplotlib和metric庫來構建ROC曲線。具體python代碼如下所示:

運行代碼,得到Test Accuracy: 0.88,即本次實驗測試集的預測准確率為88%,ROC曲線如下圖所示。
資源下載地址:https://download.csdn.net/download/sheziqiong/85820698
資源下載地址:https://download.csdn.net/download/sheziqiong/85820698