Resource download address :https://download.csdn.net/download/sheziqiong/85820698
Resource download address :https://download.csdn.net/download/sheziqiong/85820698
stay python Official website https://www.python.org/downloads/ Download the corresponding python edition , I use Python2.7.13 Version of .
The implementation of this example code uses several well-known third-party modules , The main modules are as follows :
This paper uses the Chinese stop words list published by the Chinese naturallanguageprocessing open platform of the Institute of computing, Chinese Academy of Sciences , Contains 1208 Stop words . Download address :http://www.hicode.cc/download/view-software-13784.html
Text from http://www.datatang.com/data/11936 download “ Hotel comment corpus about Chinese emotion mining ” As training set and test set , This corpus contains 4 Language material subset , In this paper, positive and negative 1000 A balanced corpus of (ChnSentiCorp_htl_ba_2000) Analysis as a data set .
Download and unzip ChnSentiCorp_htl_ba_2000.rar file , The resulting folder contains neg( Negative corpus ) and pos( Positive corpus ) Two folders , Each comment in the folder is a txt file , In order to facilitate the later operation , It is necessary to normalize the positive and negative comments to the corresponding one respectively txt In file , That is, the collection document of forward corpus ( Name it 2000_pos.txt) And negative corpus ( Name it 2000_neg.txt).
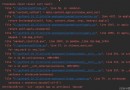
Specifically Python The implementation code is as follows :
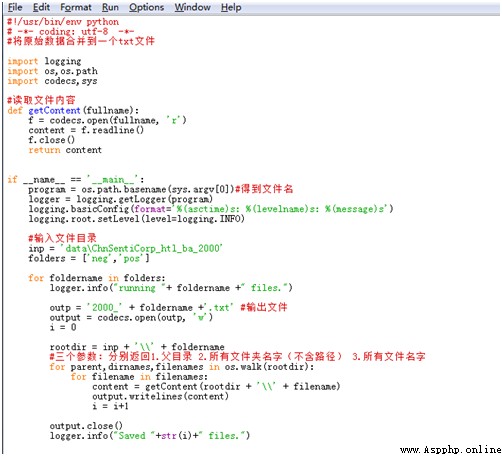
After the operation is completed, you will get 2000_pos.txt and 2000_neg.txt Two text files , Store positive and negative comments respectively , Each comment is on one line . The screenshot of the document section is shown below :

In this paper Stuttering participle Word segmentation is performed on positive and negative corpus respectively . Particular attention , Before executing the code, you need to put txt Source files are manually converted to UTF-8 Format , Otherwise, the Chinese code error will be reported . Before the participle , You need to remove numbers from the text 、 Handling of letters and special symbols , Use python Self contained string and re Modules can implement , among string Module is used to handle string operations ,re Module for regular expression processing .
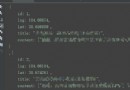
The specific implementation code is as follows :
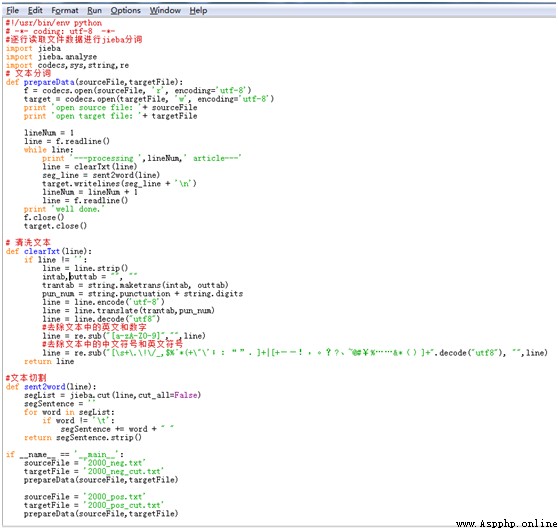
After processing , obtain 2000_pos_cut.txt and 2000_neg_cut.txt Two txt file , Store the results of word segmentation of positive and negative corpus respectively . The screenshot of the word segmentation result is shown below :

When the participle is finished , You can read the stop words in the stop words list , Match the positive and negative corpus after word segmentation and remove the stop words . The process of removing stop words is very simple , There are two main ones :
The specific implementation code is as follows :
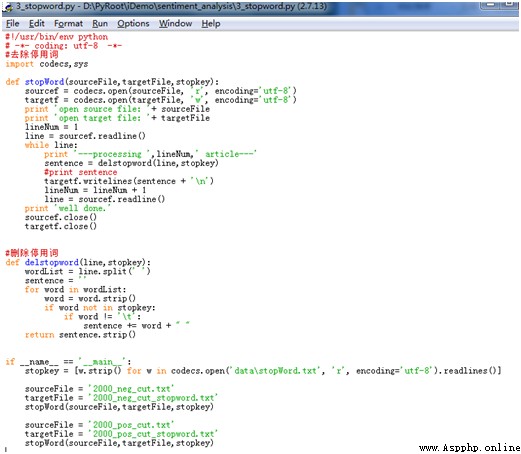
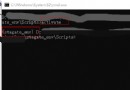
According to the code , The acquisition of the stoplist uses python Peculiar radio broadcast form , One sentence of code is enough :
stopkey = [w.strip() for w in codecs.open('data\stopWord.txt', 'r', encoding='utf-8').readlines()]
Every stop word read out must be de signed, that is w.strip(), Because the stop words read out also contain line breaks and tabs , If it is not processed, it will not match . After the code is executed , obtain 2000_neg_cut_stopword.txt and 2000_pos_cut_stopword.txt Two txt file .
Because the step of removing the stop word is performed after the sentence word segmentation , Therefore, it is usually carried out in the same code segment as the word segmentation operation , That is, after the sentence word segmentation operation is completed, directly call the function to stop the word , And get the result after removing the stop word , Then write to the result file . This article is to facilitate the understanding of the steps and separate them into two code files for execution , You can adjust it according to your own needs .
According to the above steps, we get the characteristic word text of the positive and negative corpus , The input of the model must be numerical data , Therefore, each sentence composed of words needs to be transformed into a numerical vector . Common conversion algorithms are Bag of Words(BOW)、TF-IDF、Word2Vec. In this paper Word2Vec Word vector model converts corpus into word vector .
Because the extraction of feature word vector is based on the trained word vector model , and wiki Chinese corpus is recognized as a large-scale Chinese corpus , This paper intends to start from wiki From the word vectors generated by Chinese corpus, the feature word vectors of this corpus are extracted .Wiki Of Chinese corpus Word2vec A previous article on model training “ utilize Python Realization wiki Of Chinese corpus word2vec model building ” It is described in detail in , I won't go into details here . That is, from the end of the article wiki.zh.text.vector Extracting feature word vector as input of model .
The main steps to obtain the feature word vector are as follows :
The main code is shown in the figure below :
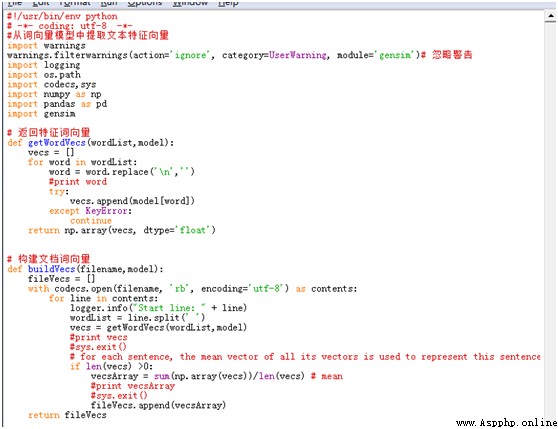
After the code is executed , Get one called 2000_data.csv The file of , The first column is the value corresponding to the category (1-pos, 0-neg), The second column starts with a numeric vector , Each line represents a comment . A partial screenshot of the results is shown below :
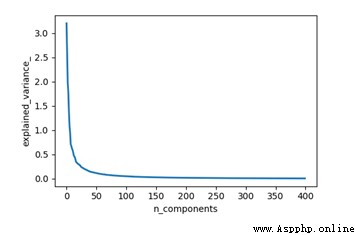
Word2vec The model sets 400 The dimension of training , The resulting word vector is 400 dimension , In this paper PCA The algorithm reduces the dimension of the result . The specific implementation code is as follows :

Run code , According to the result graph, before 100 Dimension can better contain most of the original data , So before selecting 100 Dimension as input to model .
This paper uses support vector machine (SVM) As the Chinese text classification model of this experiment , Other classification models use the same analysis process , I won't go into details here .
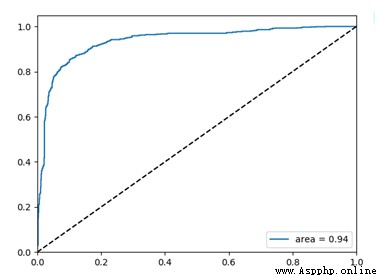
Support vector machine (SVM) It's a supervised machine learning model . Firstly, this paper adopts the classical machine learning algorithm SVM As a classifier algorithm , By calculating the prediction accuracy and ROC Curve to verify the effectiveness of the classifier , Generally speaking ROC The area of the curve (AUC) The larger the model, the better .
use first SVM As a classifier algorithm , Then use matplotlib and metric Library to build ROC curve . Specifically python The code is as follows :

Run code , obtain Test Accuracy: 0.88, That is to say, the prediction accuracy of the experimental test set is 88%,ROC The curve is shown in the figure below .
Resource download address :https://download.csdn.net/download/sheziqiong/85820698
Resource download address :https://download.csdn.net/download/sheziqiong/85820698