編寫簡短高效的 Python 代碼並不總是那麼容易或直接。然而,我們經常看到一段代碼,卻沒有意識到其編寫方式背後的思考過程。我們將看一下片段,它返回兩個迭代之間的差異,以了解其結構。
根據片段功能的描述,我們可以天真地寫成這樣:
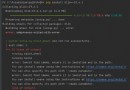
def difference(a, b):
return [item for item in a if item not in b]此實現可能運行良好,但不考慮b. 如果第二個列表中有許多重復項,這會使代碼花費更多的時間。為了解決這個問題,我們可以使用set()只保留列表中唯一值的方法:
def difference(a, b):
return [item for item in a if item not in set(b)]這個版本雖然看起來像是一個改進,但實際上可能比以前的版本慢。如果你仔細觀察,你會發現set()每次都會調用 everyitem導致a結果set(b)被評估。這是一個示例,我們set()用另一種方法包裝以更好地展示問題:
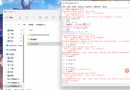
def difference(a, b):
return [item for item in a if item not in make_set(b)]
def make_set(itr):
print('Making set...')
return set(itr)
print(difference([1, 2, 3], [1, 2, 4]))
# Making set...
# Making set...
# Making set...
# [3]此問題的解決方案是set()在列表推導之前調用一次並存儲結果以加快處理速度:
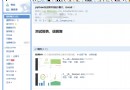
def difference(a, b):
_b = set(b)
return [item for item in a if item not in _b]在性能方面值得一提的另一個選項是使用列表推導與filter()and list()。使用後一個選項實現相同的代碼將導致如下所示:
def difference(a, b):
_b = set(b)
return list(filter(lambda item: item not in _b, a))使用timeit分析最後兩個代碼示例的性能,很明顯使用列表推導可以比替代方法快十倍。這是因為它是一種本地語言功能,其工作方式與簡單循環非常相似,for沒有額外函數調用的開銷。這解釋了為什麼我們更喜歡它,除了可讀性。