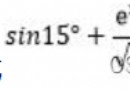If you need in Python Dealing with a large JSON file , It is easy to run out of memory . Even if the original data size is smaller than the memory capacity ,Python also
Will further increase memory usage . This means that the program will be slow when interacting with the disk , Or crash when memory is low .
A common solution is stream parsing , That is, lazy parsing 、 Iterative parsing or block processing . Let's see how to apply this technique to JSON Handle .
problem :Python Load in JSON Low memory efficiency
We use this size as 24MB Of JSON Document for example , It will have a significant impact on memory when loading . This JSON Object is in GitHub in , User deposit
List of events when the repository performs an operation :
python Exchange of learning Q Group :903971231###
[{
"id":"2489651045","type":"CreateEvent","actor":
{
"id":665991,"login":"petroav","gravatar_id":"","url":"https://api.github.com/users/petroav","avatar_url":"https://avatars.githubusercontent.com/u/665991?"},"repo":
{
"id":28688495,"name":"petroav/6.828","url":"https://api.github.com/repos/petroav/6.828"},"payload":
{
"ref":"master","ref_type":"branch","master_branch":"master","description":"Solution to homework and assignments from MIT's 6.828 (Operating Systems Engineering). Done in my spare time.","pusher_type":"user"},"public":true,"created_at":"2015-01-01T15:00:00Z"},
...
]
Our goal is to find out which repositories a given user is interacting with . Here's a simple one Python Program :
import json
with open("large-file.json", "r") as f:
data = json.load(f)
user_to_repos = {
}
for record in data:
user = record["actor"]["login"]
repo = record["repo"]["name"]
if user not in user_to_repos:
user_to_repos[user] = set()
user_to_repos[user].add(repo)

The output is a dictionary that maps user names to repository names . We use Fil When the memory analyzer runs it , You can see that the peak memory usage has reached 124MB, You can also find two main sources of memory allocation :
1. Read the file
2. Decode the generated bytes into Unicode character string
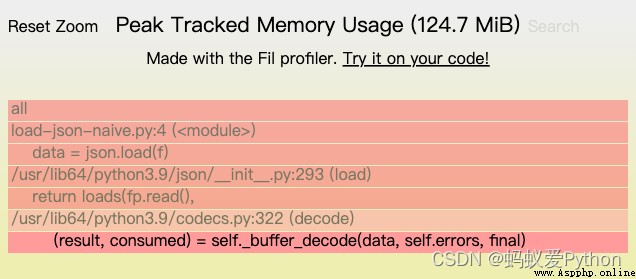
But the original file we loaded was 24MB. Once we load it into memory and decode it into text (Unicode)Python character string , It requires far more space than
24MB. Why is that ?
Python Strings are optimized for presentation using less memory . Each string has a fixed overhead , If the string can be expressed as ASCII, Then each character
Use only one byte of memory . If the string uses more extended characters , Then... May be used for each character 4 Bytes . We can use sys.getsizeof() View a pair
Like how much memory you need :
>>> import sys
>>> s = "a" * 1000
>>> len(s)
1000
>>> sys.getsizeof(s)
1049
>>> s2 = "" + "a" * 999
>>> len(s2)
1000
>>> sys.getsizeof(s2)
2074
>>> s3 = "" + "a" * 999
>>> len(s3)
1000
>>> sys.getsizeof(s3)
4076

In the example above 3 Each string is 1000 Characters long , But the amount of memory they use depends on the characters they contain .
In this case, our big JSON The file contains information that is not suitable for ASCII Encoded character , Because it is loaded as a huge string , So the whole huge character
Strings are represented by less efficient memory .
Obviously , Will the whole JSON Loading files directly into memory is a waste of memory .
For a structure that is a list of objects JSON file , In theory, we can parse one block at a time , Not all at once , To reduce memory usage . at present
There are many Python The library supports this JSON Analytical way , Let's use ijson Library as an example .
PYTHON Exchange of learning Q Group :903971231###
import ijson
user_to_repos = {
}
with open("large-file.json", "r") as f:
for record in ijson.items(f, "item"):
user = record["actor"]["login"]
repo = record["repo"]["name"]
if user not in user_to_repos:
user_to_repos[user] = set()
user_to_repos[user].add(repo)
If you use json Standard library , Once the data is loaded, the file is closed . While using ijson, The file must remain open , Because when we traverse the records ,JSON
The parser is reading the file on demand . For more details , see also ijson file .
When the memory analyzer runs it , You can see that the peak memory usage has dropped to 3.6MB, Problem solved ! And in this case , Use ijson The streaming processing of will also be improved
Runtime performance , Of course, this performance depends on the data set or Algorithm .

•Pandas:Pandas With read JSON The ability of , In theory, it can read in a more memory efficient way .
•SQLite:SQLite The database can be parsed JSON, take JSON Stored in columns , And inquiry JSON data . therefore , Can be JSON Load into disk supported
In the database file , And run a query against it to extract the relevant subset of data .
Last , If you can control the output format , Can be reduced by switching to a more efficient representation JSON Memory usage processed . for example , From a single huge JSON Yes
Like a list switching to one per line JSON Record , This means that each decoded JSON Logging will use only a small amount of memory .