如果你需要在 Python 中處理一個大的 JSON 文件,會很容易出現耗盡內存的情況。即使原始數據大小小於內存容量,Python 也
會進一步增加內存使用量。這意味著程序會在與磁盤交互時處理緩慢,或在內存不足時崩潰。
一種常見的解決方案是流解析,也就是惰性解析、迭代解析或分塊處理。讓我們看看如何將此技術應用於 JSON 處理。
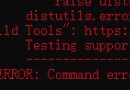
問題:Python中加載JSON內存效率低
我們使用這個大小為24MB的JSON文件來舉例,它在加載時會對內存產生明顯的影響。這個JSON對象是在GitHub中,用戶對存
儲庫執行操作時的事件列表:
python學習交流Q群:903971231###
[{
"id":"2489651045","type":"CreateEvent","actor":
{
"id":665991,"login":"petroav","gravatar_id":"","url":"https://api.github.com/users/petroav","avatar_url":"https://avatars.githubusercontent.com/u/665991?"},"repo":
{
"id":28688495,"name":"petroav/6.828","url":"https://api.github.com/repos/petroav/6.828"},"payload":
{
"ref":"master","ref_type":"branch","master_branch":"master","description":"Solution to homework and assignments from MIT's 6.828 (Operating Systems Engineering). Done in my spare time.","pusher_type":"user"},"public":true,"created_at":"2015-01-01T15:00:00Z"},
...
]
我們的目標是找出給定用戶在與哪些存儲庫進行交互。下面是一個簡單的 Python 程序:
import json
with open("large-file.json", "r") as f:
data = json.load(f)
user_to_repos = {
}
for record in data:
user = record["actor"]["login"]
repo = record["repo"]["name"]
if user not in user_to_repos:
user_to_repos[user] = set()
user_to_repos[user].add(repo)

輸出結果是一個用戶名映射到存儲庫名稱的字典。我們使用 Fil 內存分析器運行它時,可以發現內存使用的峰值達到了124MB,還可以發現兩個主要的內存分配來源:
1.讀取文件
2.將生成的字節解碼為 Unicode 字符串
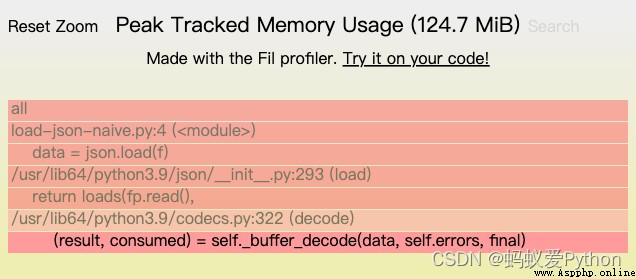
但我們加載的原始文件是24MB。一旦我們將它加載到內存中並將其解碼為文本 (Unicode)Python 字符串,它需要的空間遠遠超過
24MB。這是為什麼?
Python字符串在表示時會被更少使用內存的方法優化。每個字符串都有固定的開銷,如果字符串可以表示為 ASCII,則每個字符
只使用一個字節的內存。如果字符串使用更多擴展字符,則每個字符可能使用4個字節。我們可以使用 sys.getsizeof() 查看一個對
象需要多少內存:
>>> import sys
>>> s = "a" * 1000
>>> len(s)
1000
>>> sys.getsizeof(s)
1049
>>> s2 = "" + "a" * 999
>>> len(s2)
1000
>>> sys.getsizeof(s2)
2074
>>> s3 = "" + "a" * 999
>>> len(s3)
1000
>>> sys.getsizeof(s3)
4076

在上面的例子中3個字符串都是 1000 個字符長,但它們使用的內存量取決於它們包含的字符。
在本例中我們的大JSON 文件裡包含不適合ASCII編碼的字符,正是因為它是作為一個巨大的字符串加載的,所以整個巨大的字符
串會使用效率較低的內存表示。
很明顯,將整個JSON文件直接加載到內存中是一種內存浪費。
對一個結構為對象列表的 JSON 文件,理論上我們可以一次解析一個塊,而不是一次全部解析,以此來減少內存的使用量。目前
有許多 Python 庫支持這種 JSON 解析方式,下面我們使用 ijson 庫來舉例。
PYTHON學習交流Q群:903971231###
import ijson
user_to_repos = {
}
with open("large-file.json", "r") as f:
for record in ijson.items(f, "item"):
user = record["actor"]["login"]
repo = record["repo"]["name"]
if user not in user_to_repos:
user_to_repos[user] = set()
user_to_repos[user].add(repo)
如果使用json標准庫,數據一旦被加載文件就會被關閉。而使用ijson,文件必須保持打開狀態,因為當我們遍歷記錄時,JSON
解析器正在按需讀取文件。有關更多詳細信息,請參閱 ijson 文檔。
在內存分析器運行它時,可以發現內存使用的峰值降到了3.6MB,問題解決了!而且在此例子中,使用 ijson 的流式處理也會提升
運行時的性能,當然這個性能取決於數據集或算法。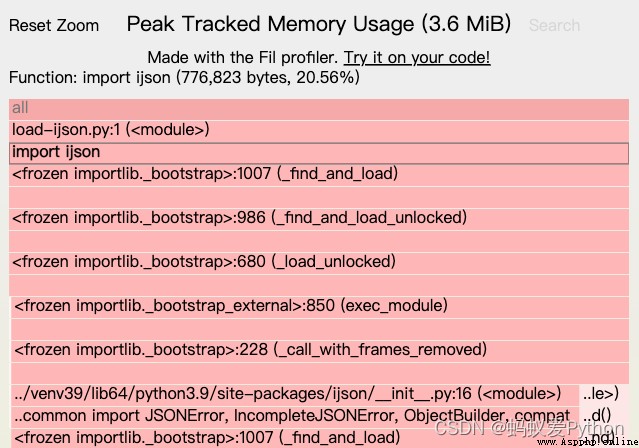

•Pandas:Pandas 具有讀取 JSON 的能力,理論上它可以以更節省內存的方式讀取。
•SQLite:SQLite 數據庫可以解析 JSON,將 JSON 存儲在列中,以及查詢 JSON數據。因此,可以將 JSON 加載到磁盤支持的
數據庫文件中,並對它運行查詢來提取相關的數據子集。
最後,如果可以控制輸出格式,則可以通過切換到更高效的表示來減少 JSON 處理的內存使用量。例如,從單個巨大的 JSON 對
象列表切換到每行一條 JSON 記錄,這意味著每條解碼的 JSON 記錄將只使用少量內存。