大家好鴨, 又是我小熊貓啦
我們在做采集數據的時候,過快或者訪問頻繁,或者一訪問就給彈出驗證碼,然後就蚌珠了~
今天就給大家來一個簡單處理驗證碼的方法
Python和pycharm如果還有小伙伴沒安裝的話,可以在文章最下方掃碼獲取安裝包。
這裡需要用到一個 ddddocr 模塊 ,這是別人開源寫好的一個東西,簡單又好用,但是精確度差一點點,但是還是非常好用的。
如果你追求精確度的話,可以調用別人寫好的一些API 。
咱們直接 win+r 彈出搜索框後輸入 cmd ,點擊確定彈出命令提示符窗口, 輸入pip install ddddocr 即可安裝。
不會的話詳細參考我置頂文章有詳細講解。
代碼不多,非常簡單。
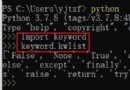
模塊安裝好之後咱們先導入一下
import ddddocr
然後實例化一下,用一個 cor 接收一下這個數據。
ocr = ddddocr.DdddOcr()
我這裡准備了四個驗證碼



博客水印好像擋住了,但是我是不會關掉滴 ,嘿嘿~
回到正題,分別實現一下驗證碼。
首先我們用 with open 來讀取一下這文件,讀取方式使用 rb ,因為是圖片的話就讀取它的二進制數據
with open('img_3.png', 'rb') as f:
使用 f.read() 將數據讀取出來,再自定義一個變量接收一下。
img_bytes = f.read()
然後我們通過 classification 將它傳進去,把結果打印出來就可以了。
result = ocr.classification(img_bytes)
print(result)
純數字的
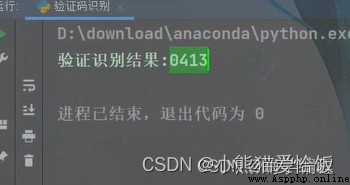
字母+數字的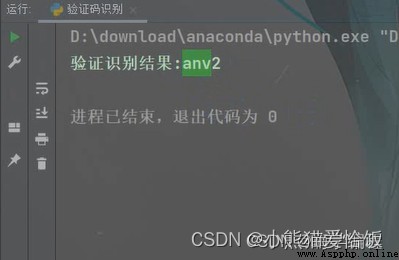

可以看到都完整的識別出來了,即使上面有一些花裡胡哨的橫線啥的。
import ddddocr
ocr = ddddocr.DdddOcr()
with open('img_3.png', 'rb') as f:
img_bytes = f.read()
result = ocr.classification(img_bytes)
print(result)
(https://jq.qq.com/?_wv=1027&k=3uTc6UFb)
大家可以自己去試試,也可以直接應用在采集數據實踐當中~
創作不易,大家幫忙點個收藏吧~