這次是針對需要網頁分析的爬蟲,分析過後往往會獲得你需要的每節視頻源地址,但是假如一節視頻課是有很多節課你就必須要去一個個的去搜尋每個視頻的源地址,這樣一來非常浪費時間而且也沒有打到我們的對於爬蟲自動化的需求,於是我們就需要去對整個頁面進行分析試圖把它連根拔起。
這次我們准備爬取的是mooc裡的猴博士電路系列。
打開我們的mooc找到猴博士的電路系列課程點進去第一課,F12後刷新。我分析的數據包的習慣就是先把包按照從大到小的排序
我們挨個從大到小查看,看到第二個的時候我們點擊它的鏈接話會自動給你下載一個.m3u8文件
通過百度我們知道這m3u8文件是存放視頻的,視頻會被切割成十秒一份的.ts格式的視頻.ts格式是日本發明的一種可以每段分段解析的一種視頻格式有了這個格式我們的視頻才可能實時傳輸,才能改變分辨率後不會從頭開始播。了解了後我們用記事本(這裡我用的notepad++)打開該文件。
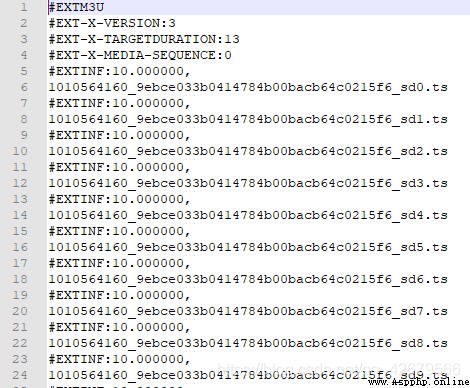
果然不出所料這個裡面確實有鏈接,但是好像不完整這個,於是我看了一下.m3u8的鏈接https://jdvodrvfb210d.vod.126.net/jdvodrvfb210d/nos/hls/2018/09/28/1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8?ak=7909bff134372bffca53cdc2c17adc27a4c38c6336120510aea1ae1790819de83648959c0963d7b517df373715a0a62630c89a42b26e6c7c455cd73d745bce253059f726dc7bb86b92adbc3d5b34b13258d0932fcf70014da46f4120a3f55e664426afeac364f76a817da3b2623cd41e
這個鏈接很長但是仔細看一下就知道.m3u8後面的是參數,使用https://jdvodrvfb210d.vod.126.net/jdvodrvfb210d/nos/hls/2018/09/28/1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8這個鏈接也能訪問下載的到.m3u8的文件。仔細對比一下不難發現1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8這段和我們的視頻片段鏈接很像,不難找到視頻鏈接需要帶上https://jdvodrvfb210d.vod.126.net/jdvodrvfb210d/nos/hls/2018/09/28/來湊成整的鏈接,於是我能不難寫出這個視頻的爬取代碼
import requests
url = "https://jdvodrvfb210d.vod.126.net/jdvodrvfb210d/nos/hls/2018/09/28/"
m3u8 = '1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8'
r = requests.get(url+m3u8)
content = r.text
content = content.split('\n')
ts = []
num = 4
f = open("猴博士電路第一課.ts", 'wb')
while True:
if content[num][:7] == '#EXTINF':
res = requests.get(url+content[num+1])
f.write(res.content)
elif content[num] == '#EXT-X-ENDLIST':
break
num = num+2
f.close()
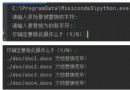
print('ok')
還是回到前言說說的內容,如果單純爬取一課這麼做可以,但是一系列的爬取你就需要去手動的去找每一個鏈接了,這樣就特別麻煩那麼有沒有辦法呢?當然是有的,我們想找尋每個鏈接之間的規律,最好的辦法就是找到鏈接的來源。於是在F12裡搜索1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8
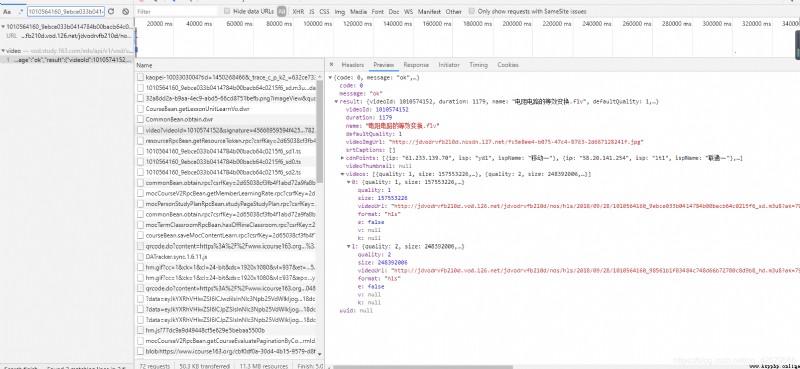
結果還真給我搜到了https://vod.study.163.com/eds/api/v1/vod/video?videoId=1010574152&signature=45666959594f425950516d3679506e65537539334145562f665130584a4c31362b35572b633632317a5848514d7032314f756333355269334b517a4b733351446d5731704e3341334f4e2f632b67654c70557073713033564947356154724e536b55437131685a486343364b4a46646f6339766e7432544c614573414a62572f682f6d4762762f517873595a754c4b2b304e6b37536d3739344e782b585a6d3175382f38455967574e34633d&clientType=1,在它返回的json中還有兩個鏈接,其中一個就是我們的鏈接,還有一個是畫質更好的
嗯,現在我們可以獲取了,但是我們還是沒有找到這個鏈接的源頭,通過分析不難看出鏈接有三個參數一個是videoId,一個是signature,還有一個是clientType,那我們就繼續搜索45666959594f425950516d3679506e65537539334145562f665130584a4c31362b35572b633632317a5848514d7032314f756333355269334b517a4b733351446d5731704e3341334f4e2f632b67654c70557073713033564947356154724e536b55437131685a486343364b4a46646f6339766e7432544c614573414a62572f682f6d4762762f517873595a754c4b2b304e6b37536d3739344e782b585a6d3175382f38455967574e34633d來溯源它的上一層是什麼
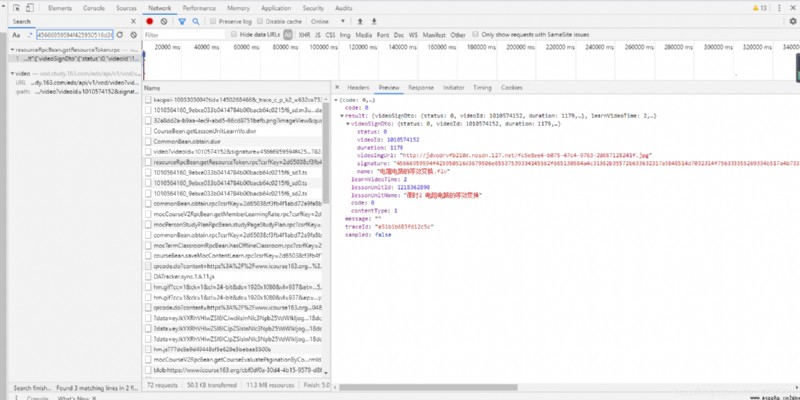
追查著源頭我們找到了https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey=2d65038cf3fb4f1abd72a9fa8b0023e3這個post鏈接,我們看到了它post的data
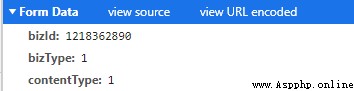
通過requests庫裡的post我們可以模仿浏覽器向服務器的post。(這裡需要添加cookies不然會返回跨區域請求)那麼問題來了這個1218362890我們從何而來呢?
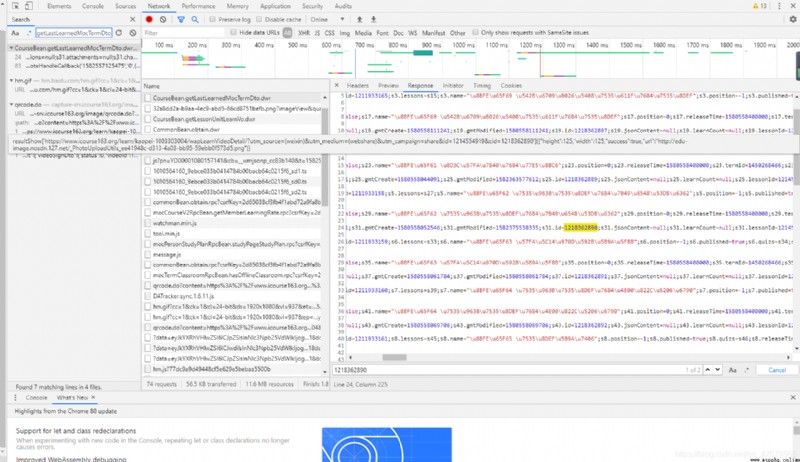
通過搜索找到了https://www.icourse163.org/dwr/call/plaincall/CourseBean.getLastLearnedMocTermDto.dwr它返回一個貌似是js的代碼,並且找到了其它的視頻的bizId那麼至此我們就可以通過程序將它連根拔起了,我我們通過多線程將它全部爬取下來
import requests
import re
import threading
cookie = {
'EDUWEBDEVICE':'4e11983bda394e54ad6138086e05561b;'
# 這裡為了保護自己的隱私我就沒有寫完自己的cookies,在寫的時候需要按照上面的形式本來是等號的改成冒號,把
# 數值用鍵值對表示不同的用分號隔開
}
def GitID():
heards = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36',
'content-type':'text/plain'
}
data = 'callCount=1\nscriptSessionId=${scriptSessionId}190\nhttpSessionId=2d65038cf3fb4f1abd72a9fa8b0023e3\nc0-scriptName=CourseBean\nc0-methodName=getLastLearnedMocTermDto\nc0-id=0\nc0-param0=number:1450268466\nbatchId=1582376246318'
r = requests.post('https://www.icourse163.org/dwr/call/plaincall/CourseBean.getLastLearnedMocTermDto.dwr',data=data,headers=heards,cookies=cookie)
content = re.findall('id=1218\d*', r.text)
for i in range(len(content)):
content[i] = content[i][3:]
return content
def GetSignature(num):
heards = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36',
'content-type':'application/x-www-form-urlencoded'
}
data = 'bizId=%s&bizType=1&contentType=1'%(num)
r = requests.post('https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey=2d65038cf3fb4f1abd72a9fa8b0023e3',data=data,headers=heards,cookies=cookie)
return r.json()['result']['videoSignDto']['videoId'],r.json()['result']['videoSignDto']['signature']
def GetUrl(signature):
r = requests.get('https://vod.study.163.com/eds/api/v1/vod/video?videoId=%s&signature=%s&clientType=1'%(signature[0],signature[1]))
return r.json()['result']['videos'][0]['videoUrl']
def GetMp4(Url,name):
r = requests.get(Url)
content = r.text.split('\n')
num = 4
f = open('猴博士電路%d.mp4'%(int(name)-89),'wb')
while True:
if content[num][:7] == '#EXTINF':
res = requests.get(Url[:66]+content[num+1])
f.write(res.content)
elif content[num] == '#EXT-X-ENDLIST':
break
num = num+2
f.close()
def mutilprocess():
Id = GitID()
threads = []
url = []
for i in range(len(Id)):
try:
url.append(GetUrl(GetSignature(Id[i])))
threads.append(threading.Thread(target=GetMp4,args=(url[i],Id[i][-2:])))
except:
pass
for i in range(len(threads)):
threads[i].start()
for i in range(len(threads)):
threads[i].join()
print('"猴博士電路%d.mp4"爬取完成'%(int(Id[i][-2:])-89))
if __name__ == "__main__":
mutilprocess()
print('爬取成功!')
這裡對cookies還是要說一下[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-4W8rd8qU-1582558032317)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20200224232144234.png)]
if name == “main”:
mutilprocess()
print(‘爬取成功!’)
這裡對cookies還是要說一下
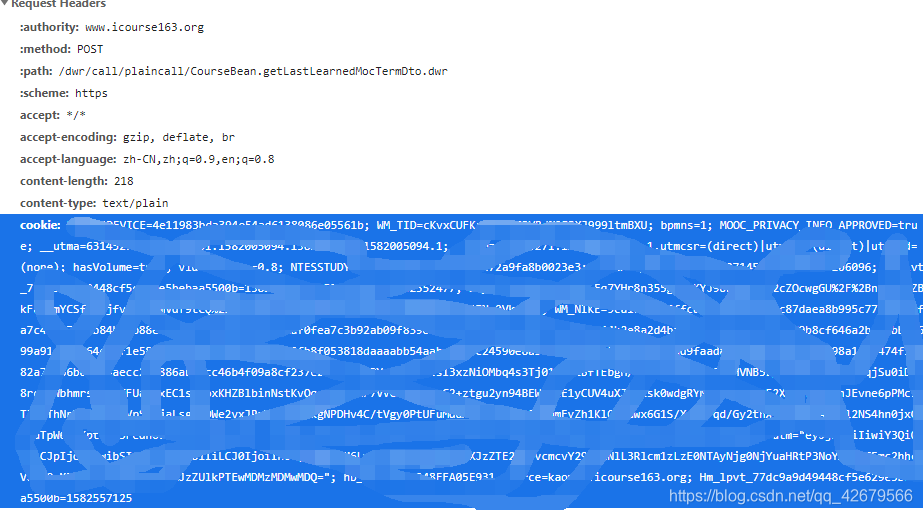
源cookies信息在F12的headers裡的Requests Headers 裡,但是自己要把它改寫字典形式。