自己學習python的初衷就是為了能在支持micropython的芯片上編程,比如早期接觸到的openmv,以及擁有arm linux環境的樹莓派上(樹莓派的python不是micropython)還有後面接觸到的esp32和esp8266上編寫程序。於是乎進入了python編程的自學行列,經過一段時間在b站看小甲魚視頻後自己的基礎知識方面知道的差不多了,後面就想著運用到實際上。於是就接觸python最經典的東西“爬蟲”,一開始學習爬蟲的時候是在mooc跟著嵩天老師學習的,講到關於requests和bs4在內的很多爬蟲。自己也慢慢的有了進步,但是在自己想依靠爬蟲去白嫖“百度文庫”的時候第一次碰壁,自己爬取的內容是空的。很奇怪,明明自己按了F12後能看到文字在html後面怎麼爬蟲就爬取的是空呢?後來幾經百度發現它的頁面是通過js渲染的,而requests庫能得到的就是原始的html頁面,於是也就只能不了了之。時過境遷,後來我准備利用esp32裡的micropython制作一個up主點贊關注的顯示機的時候,又碰到了這個問題,我也百度過也知道它百度後能查到它的api,但是這次我想親自分析出這個api,也為我爬蟲學習畫上一個小句號
關於這個selenium庫,是一個網頁自動化的庫,個人理解就是做網頁腳本的一個好用的庫,這裡如果用它做爬蟲的話能夠獲取渲染過後的結果,它pip下載之後還要去安裝對應的網頁驅動比如我就是用的是谷歌浏覽器的驅動,這裡推薦一篇博文windows環境下安裝selenium這裡要說的是要會看自己浏覽器的版本去下對應的驅動,chrome是在【幫助】->【關於Google chrome】裡面
這是我的版本。
在你要爬取的地方右擊然後copy Xpath就行了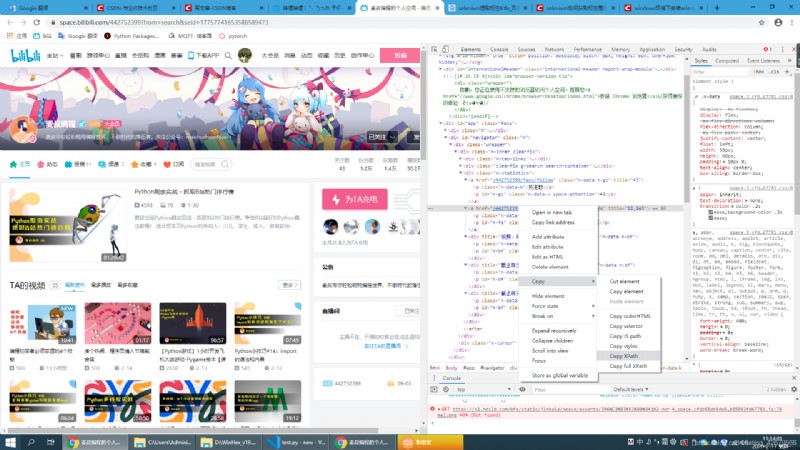
後面的我就貼出代碼來了
from selenium import webdriver
Browser = webdriver.Chrome()
Browser.get("https://space.bilibili.com/442752399?from=search&seid=17757741653586589473")
content = Browser.find_element_by_xpath('//*[@id="navigator"]/div/div[1]/div[3]/a[2]')
print("粉絲數:",content.get_attribute("title"),content.text)
Browser.close()
實際上對於micropython來說並不是python它沒有那麼豐富的庫,不過最基礎的requests庫還是有的(micropython裡叫urequests庫)那麼這麼基礎的庫我們就只能抓它的api了,於是就要對網頁數據包進行分析。
按下F12後首先我對一個數字產生了興趣那就是粉絲數12243這個數字那麼如果有數據包,數據包就必然有這個數字(前提是沒做加密處理的情況),然後我就習慣性的去network裡面的XHR找,
結果找了一圈沒找到,後來進入了,Sources裡搜索這個數字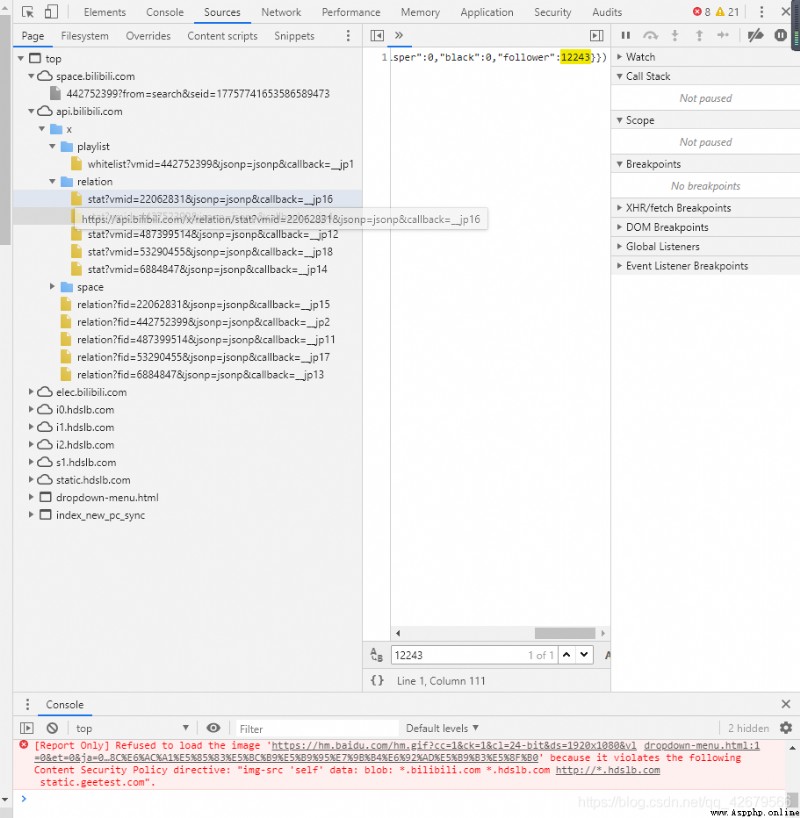
終於在這裡找到了,但是當我右鍵open in new tab的時候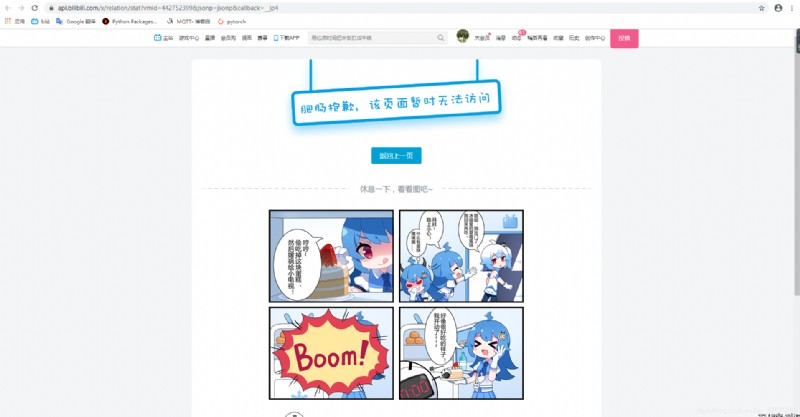
結果就是無法訪問,最後分析url後我i選擇刪除&callback=__jp4後發現成功返回json
至此它的api就分析出來啦,下面貼出源碼
import requests
uid = input('please input your uid:')
url = 'https://api.bilibili.com/x/relation/stat?vmid=%s&jsonp=jsonp'%(uid)
r = requests.get(url)
print(r.json()["data"]["follower"])
以上就是自己的兩種方法,第一種適合pc,但是相對看、來說可能局限性很大。第二種很明顯就是要抓取源數據的url,這裡通過一些手段獲得相應的url後對url分析後獲取真正的url,雖然很簡單但是寫出了自己的心路歷程,算是給後來的人少走彎路吧。