需要安裝requests模塊和lxml模塊
利用pip安裝
pip install requests
pip install lxml
關於requests庫的使用我在上一篇文章上寫了所以在這裡不多做贅述
這裡lxml我們用到它的etree庫
用法如下:
首先我們先需要找到我們要爬取的網站https://www.dxsjz.com/part/注意此時我們滑到最低端
選擇下一頁,再選擇下一頁
https://www.dxsjz.com/part/page_2.html
https://www.dxsjz.com/part/page_3.html
對比兩次鏈接可以發現這兩個url只有最後有區別那麼有理由猜測第一頁除了是https://www.dxsjz.com/part/還是https://www.dxsjz.com/part/page_1.html
import requests
for num in range(100):
r = requests.get("https://www.dxsjz.com/part/page_%d.html"%(num+1))
這裡通過循環可以爬取多個頁面的內容
在此基礎之下開始使用lxml
import requests
from lxml import etree
for num in range(100):
r = requests.get("https://www.dxsjz.com/part/page_%d.html"%(num))
html = etree.HTML(r.text)
建立一個etree對象,然後就可以調用xpath
我們打開鏈接按下F12進入開發者模式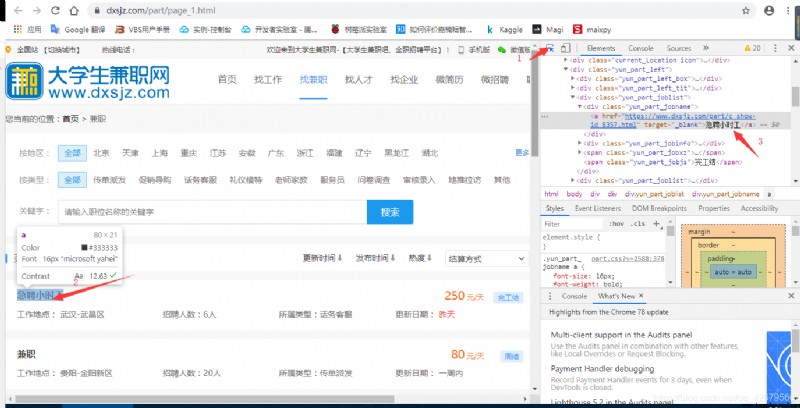
點擊開發者模式左上角的的鼠標圖標然後點擊要爬取得內容即可看到右邊給了html相應的定位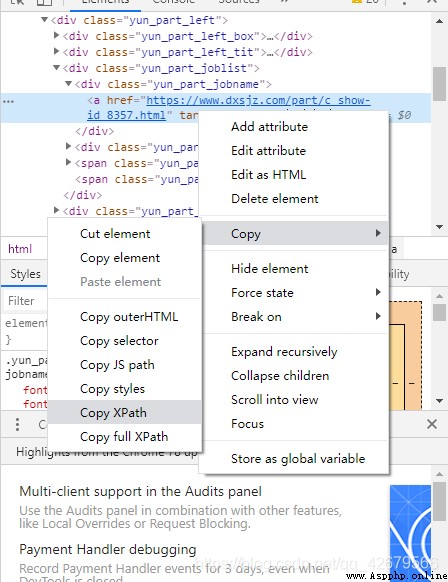
定位的地方右擊選擇Copy Xpath即可拷貝下xpath路徑
html.xpath("/html/body/div[5]/div[2]/div[3]/div[1]/a"))
通過這一行就可以提取一個列表,列表裡有一個對象,我們通過索引的方式把它取出來並且通過.text屬性獲取內容
html.xpath("/html/body/div[5]/div[2]/div[3]/div[1]/a"))[0].text
接下來通過其它的xpath我們可以找到規律
從而寫出最終程序、
import requests
from lxml import etree
for num in range(100):
r = requests.get("https://www.dxsjz.com/part/page_%d.html"%(num))
html = etree.HTML(r.text)
with open("大學生兼職網%d.txt"%(num),'w') as f:
for i in range(10):
try:
html.xpath("/html/body/div[5]/div[2]/div[%d]/div[1]/span"%(i+3))[0].text
except:
f.write(html.xpath("/html/body/div[5]/div[2]/div[%d]/div[1]/a"%(i+3))[0].text)
f.write('\n')
f.write(html.xpath("/html/body/div[5]/div[2]/div[%d]/div[2]/span[1]"%(i+3))[0].text)
f.write('\n')
f.write(html.xpath("/html/body/div[5]/div[2]/div[%d]/div[2]/span[2]"%(i+3))[0].text)
f.write('\n')
else:
f.write(html.xpath("/html/body/div[5]/div[2]/div[%d]/div[2]/a"%(i+3))[0].text)
f.write('\n')
f.write(html.xpath("/html/body/div[5]/div[2]/div[%d]/div[3]/span[1]"%(i+3))[0].text)
f.write('\n')
f.write(html.xpath("/html/body/div[5]/div[2]/div[%d]/div[3]/span[2]"%(i+3))[0].text)
f.write('\n')