<html>..</html> 表示標記中間的元素是網頁
<body>..</body> 表示用戶可見的內容
<div>..</div> 表示框架
<p>..</p> 表示段落
<li>..</li>表示列表
<img>..</img>表示圖片
<h1>..</h1>表示標題
<a href="">..</a>表示超鏈接
<html>
<head>
<title> Python 3 爬蟲與數據清洗入門與實戰</title>
</head>
<body>
<div>
<p>Python 3爬蟲與數據清洗入門與實戰</p>
</div>
<div>
<ul>
<li><a href="http://c.biancheng.net">爬蟲</a></li>
<li>數據清洗</li>
</ul>
</div>
</body>


User-Agent:*
Disallow:/






復制純文本復制
- import requests #導入requests包
- url = 'http://www.cntour.cn/'
- strhtml = requests.get(url) #Get方式獲取網頁數據
- print(strhtml.text)
import requests #導入requests包 url = 'http://www.cntour.cn/' strhtml = requests.get(url) #Get方式獲取網頁數據 print(strhtml.text)運行結果如圖 10 所示:

requests.get
將獲取到的數據存到 strhtml 變量中,代碼如下:strhtml = request.get(url)
這個時候 strhtml 是一個 URL 對象,它代表整個網頁,但此時只需要網頁中的源碼,下面的語句表示網頁源碼:strhtml.text




url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
POST 的請求獲取數據的方式不同於 GET,POST 請求數據必須構建請求頭才可以。
From_data={'i':'我愛中國','from':'zh-CHS','to':'en','smartresult':'dict','client':'fanyideskweb','salt':'15477056211258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'1547705621125','bv':'b33a2f3f9d09bde064c9275bcb33d94e','doctype':'json','version':'2.1','keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'}
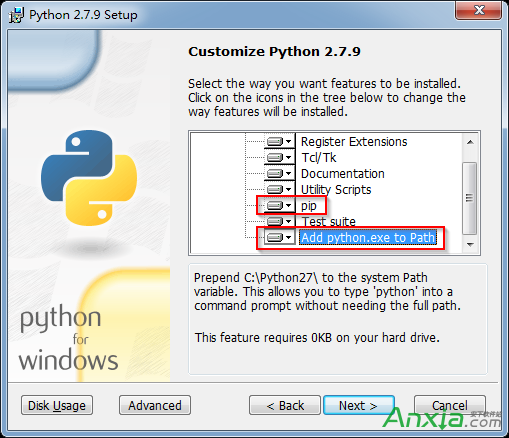
接下來使用 requests.post 方法請求表單數據,代碼如下: import requests #導入requests包
response = requests.post(url,data=payload)
復制純文本復制
- import json
- content = json.loads(response.text)
- print(content['translateResult'][0][0]['tgt'])
import json content = json.loads(response.text) print(content['translateResult'][0][0]['tgt'])使用 requests.post 方法抓取有道翻譯結果的完整代碼如下:
復制純文本復制
- import requests #導入requests包
- import json
- def get_translate_date(word=None):
- url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
- From_data={
'i':word,'from':'zh-CHS','to':'en','smartresult':'dict','client':'fanyideskweb','salt':'15477056211258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'1547705621125','bv':'b33a2f3f9d09bde064c9275bcb33d94e','doctype':'json','version':'2.1','keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'}
- #請求表單數據
- response = requests.post(url,data=From_data)
- #將Json格式字符串轉字典
- content = json.loads(response.text)
- print(content)
- #打印翻譯後的數據
- #print(content['translateResult'][0][0]['tgt'])
- if __name__=='__main__':
- get_translate_date('我愛中國')
import requests #導入requests包
import json
def get_translate_date(word=None):
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
From_data={'i':word,'from':'zh-CHS','to':'en','smartresult':'dict','client':'fanyideskweb','salt':'15477056211258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'1547705621125','bv':'b33a2f3f9d09bde064c9275bcb33d94e','doctype':'json','version':'2.1','keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'}
#請求表單數據
response = requests.post(url,data=From_data)
#將Json格式字符串轉字典
content = json.loads(response.text)
print(content)
#打印翻譯後的數據
#print(content['translateResult'][0][0]['tgt'])
if __name__=='__main__':
get_translate_date('我愛中國')
復制純文本復制
- import requests #導入requests包
- from bs4 import BeautifulSoup
- url='http://www.cntour.cn/'
- strhtml=requests.get(url)
- soup=BeautifulSoup(strhtml.text,'lxml')
- data = soup.select('#main>div>div.mtop.firstMod.clearfix>div.centerBox>ul.newsList>li>a')
- print(data)
import requests #導入requests包
from bs4 import BeautifulSoup
url='http://www.cntour.cn/'
strhtml=requests.get(url)
soup=BeautifulSoup(strhtml.text,'lxml')
data = soup.select('#main>div>div.mtop.firstMod.clearfix>div.centerBox>ul.newsList>li>a')
print(data) 代碼運行結果如圖 17 所示。 
from bs4 import BeautifulSoup
首先,HTML 文檔將被轉換成 Unicode 編碼格式,然後 Beautiful Soup 選擇最合適的解析器來解析這段文檔,此處指定 lxml 解析器進行解析。解析後便將復雜的 HTML 文檔轉換成樹形結構,並且每個節點都是 Python 對象。這裡將解析後的文檔存儲到新建的變量 soup 中,代碼如下:soup=BeautifulSoup(strhtml.text,'lxml')
接下來用 select(選擇器)定位數據,定位數據時需要使用浏覽器的開發者模式,將鼠標光標停留在對應的數據位置並右擊,然後在快捷菜單中選擇“檢查”命令,如圖 18 所示:

#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a
由於這條路徑是選中的第一條的路徑,而我們需要獲取所有的頭條新聞,因此將 li:nth-child(1)中冒號(包含冒號)後面的部分刪掉,代碼如下:#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a
使用 soup.select 引用這個路徑,代碼如下:data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a')
復制純文本復制
- for item in data:
- result={
- 'title':item.get_text(),
- 'link':item.get('href')
- }
- print(result)
for item in data:
result={
'title':item.get_text(),
'link':item.get('href')
}
print(result) 代碼運行結果如圖 20 所示: 
\d匹配數字
+匹配前一個字符1次或多次
復制純文本復制
- import re
- for item in data:
- result={
- "title":item.get_text(),
- "link":item.get('href'),
- 'ID':re.findall('\d+',item.get('href'))
- }
- print(result)
import re
for item in data:
result={
"title":item.get_text(),
"link":item.get('href'),
'ID':re.findall('\d+',item.get('href'))
}
print(result) 運行結果如圖 21 所示: 

headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
response = request.get(url,headers=headers)
import time
time.sleep(3)
復制純文本復制
- proxies={
- "http":"http://10.10.1.10:3128",
- "https":"http://10.10.1.10:1080",
- }
- response = requests.get(url, proxies=proxies)
proxies={
"http":"http://10.10.1.10:3128",
"https":"http://10.10.1.10:1080",
}
response = requests.get(url, proxies=proxies)