Learn by yourself python Our original intention is to support micropython On chip programming , For example, early exposure openmv, And having arm linux Environmental raspberry pie ( Raspberry pie python No micropython) There is also the contact behind esp32 and esp8266 Write program on . So I entered python Programming self-study ranks , After a while, I was in b After watching the video of little turtle, I know almost my basic knowledge , Then I want to apply it to practice . So I contacted python The most classic thing “ Reptiles ”, When I first learned to crawl, I was mooc I learned from teacher Songtian , Talking about requests and bs4 A lot of reptiles . I have made progress slowly , But I want to rely on reptiles to go whoring for nothing “ Baidu library ” When I met the wall for the first time , The content you crawl is empty . It's strange , Obviously I pressed F12 Then you can see the text in html How can the crawler crawl in the back to get empty ? Later, baidu found several times that its page was through js Rendered , and requests What the library can get is the original html page , So it can only be settled . Times have changed , Later I was going to use esp32 Inside micropython To make a up When the main point likes the concerned display machine , This problem comes up again , I also know that Baidu can find it after Baidu api, But this time I want to analyze this for myself api, It also draws a short stop for my reptile learning
About this selenium library , Is a web page automation library , Personal understanding is a useful library for web script , Here, if you use it as a crawler, you can get the rendered results , it pip After downloading, I have to install the corresponding web driver. For example, I use the driver of Google browser , Here is a blog post windows Installation in environment selenium What I want to say here is that I need to look at the version of my browser and download the corresponding driver ,chrome Is in 【 help 】->【 About Google chrome】 Inside 
This is my version .
Right click where you want to crawl and copy Xpath That's it 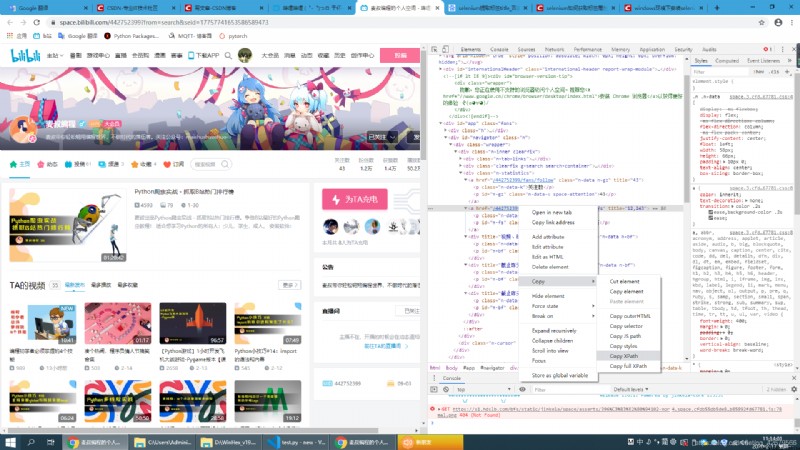
I will post the code later
from selenium import webdriver
Browser = webdriver.Chrome()
Browser.get("https://space.bilibili.com/442752399?from=search&seid=17757741653586589473")
content = Browser.find_element_by_xpath('//*[@id="navigator"]/div/div[1]/div[3]/a[2]')
print(" Number of fans :",content.get_attribute("title"),content.text)
Browser.close()
In fact for micropython It's not python It doesn't have that rich library , But the most basic requests The library still has (micropython Call in urequests library ) Then we can only catch such a basic library api 了 , So it is necessary to analyze the web packet .
Press down F12 First of all, I became interested in the number of fans 12243 This number, if there are packets , The packet must have this number ( The premise is that no encryption processing is performed ), Then I used to go network Inside XHR look for ,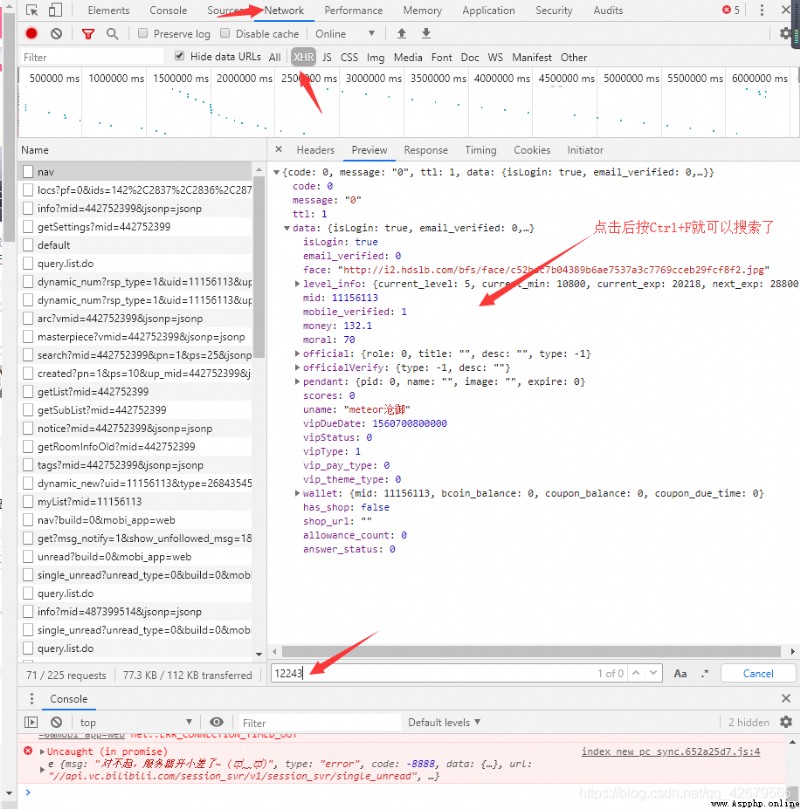
As a result, I looked around and couldn't find , And then came ,Sources Search for this number in 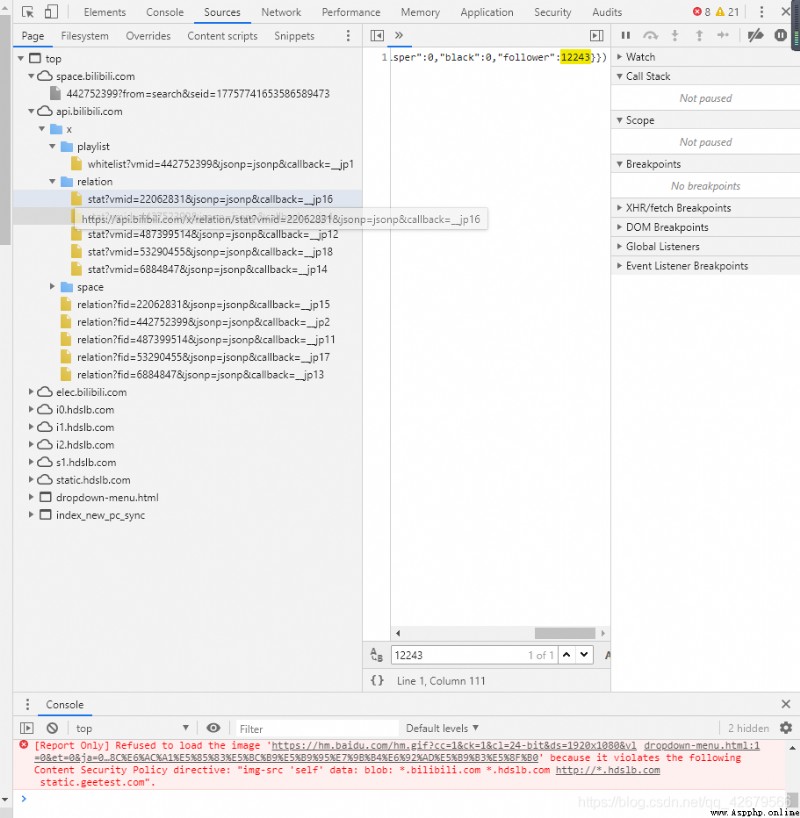
Finally found here , But when I right click open in new tab When 
The result is no access to , Final analysis url After me i Choose Delete &callback=__jp4 After discovery, the system successfully returns json
So far its api It was analyzed , The source code is posted below
import requests
uid = input('please input your uid:')
url = 'https://api.bilibili.com/x/relation/stat?vmid=%s&jsonp=jsonp'%(uid)
r = requests.get(url)
print(r.json()["data"]["follower"])
These are my two methods , The first fit pc, But in contrast 、 It may be very limited . The second is to capture the source data url, Here we can get the corresponding url After the url After analysis, get the real url, Although it is very simple, I have written my own mental journey , It can be regarded as a way to avoid detours for later people .