Need to install requests Module and lxml modular
utilize pip install
pip install requests
pip install lxml
About requests I use the library in Last one It's written in the article, so I won't repeat it here
here lxml We use it etree library
Usage is as follows :
First, we need to find the website we want to crawl https://www.dxsjz.com/part/ Notice that at this point we slide to the lowest end
Select next page , Then select the next page
https://www.dxsjz.com/part/page_2.html
https://www.dxsjz.com/part/page_3.html
Comparing the two links, you can find the two url Only the last difference makes it reasonable to guess that the first page is except https://www.dxsjz.com/part/ still https://www.dxsjz.com/part/page_1.html
import requests
for num in range(100):
r = requests.get("https://www.dxsjz.com/part/page_%d.html"%(num+1))
Here, the contents of multiple pages can be crawled through the loop
Start using on this basis lxml
import requests
from lxml import etree
for num in range(100):
r = requests.get("https://www.dxsjz.com/part/page_%d.html"%(num))
html = etree.HTML(r.text)
Build a etree object , Then it can be called xpath
We open the link and press F12 Enter developer mode 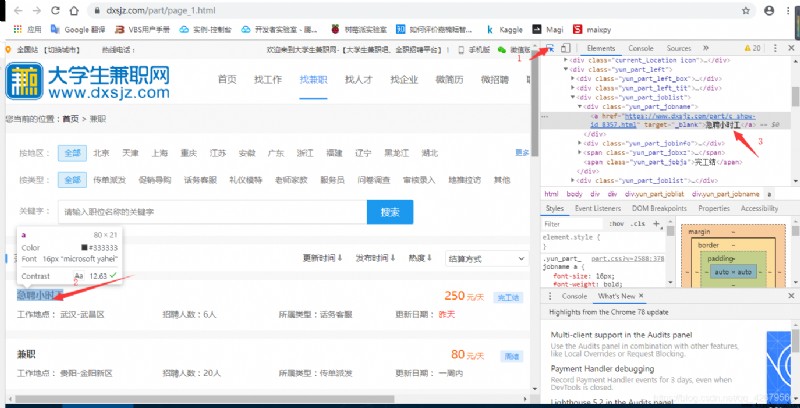
Click the mouse icon in the upper left corner of the developer mode, and then click the content to be crawled to see the content on the right html Corresponding positioning 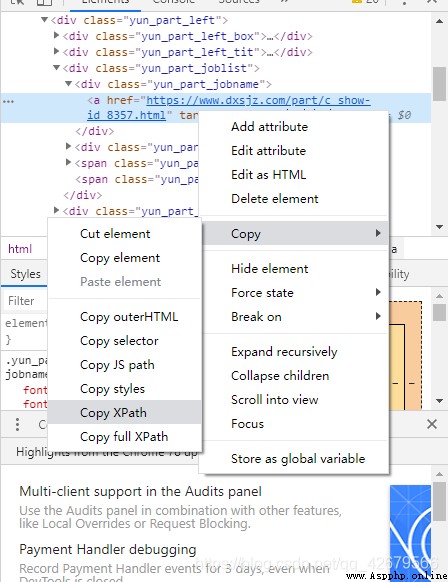
Right click the location to select Copy Xpath You can copy xpath route
html.xpath("/html/body/div[5]/div[2]/div[3]/div[1]/a"))
From this line you can extract a list , There is an object in the list , We take it out by index and pass it through .text Property to get the content
html.xpath("/html/body/div[5]/div[2]/div[3]/div[1]/a"))[0].text
Then through other xpath We can find rules
To write the final program 、
import requests
from lxml import etree
for num in range(100):
r = requests.get("https://www.dxsjz.com/part/page_%d.html"%(num))
html = etree.HTML(r.text)
with open(" Part time job network for college students %d.txt"%(num),'w') as f:
for i in range(10):
try:
html.xpath("/html/body/div[5]/div[2]/div[%d]/div[1]/span"%(i+3))[0].text
except:
f.write(html.xpath("/html/body/div[5]/div[2]/div[%d]/div[1]/a"%(i+3))[0].text)
f.write('\n')
f.write(html.xpath("/html/body/div[5]/div[2]/div[%d]/div[2]/span[1]"%(i+3))[0].text)
f.write('\n')
f.write(html.xpath("/html/body/div[5]/div[2]/div[%d]/div[2]/span[2]"%(i+3))[0].text)
f.write('\n')
else:
f.write(html.xpath("/html/body/div[5]/div[2]/div[%d]/div[2]/a"%(i+3))[0].text)
f.write('\n')
f.write(html.xpath("/html/body/div[5]/div[2]/div[%d]/div[3]/span[1]"%(i+3))[0].text)
f.write('\n')
f.write(html.xpath("/html/body/div[5]/div[2]/div[%d]/div[3]/span[2]"%(i+3))[0].text)
f.write('\n')