CDA數據分析師 出品
作者:CDALevel Ⅰ持證人
崗位:數據分析師
行業:大數據
背景
電子商務行業在近幾年發展得極為迅猛,很多在傳統行業就業但是薪資不理想的都在網電子商務行業去轉。這種趨勢造就了越來越多老百姓使用電子商務價值下的產品,不言而喻,比如網購等行為。換句話說,大量的網購會帶來的結果就是數據量的增大。面對這種大數據,且時非結構化的數據如商品評論,怎麼處理呢?怎麼從中提取有用的信息呢?自然語言處理技術給出了答案,從規則提取到統計建模到如今非常火熱的深度學習,都能從文本中提取到有用的商業價值,無論時為商家還是買家。本文就某電商平台上AirPods智能耳機產品的售賣情況及相關商品信息進行情感分析與快速詞雲圖搭建。情感分析也是自然語言處理中的一個方向
除了對文本進行挖掘以外,本文還欲搭建一個網頁APP。Python是目前比較流行的編程語言,利用Python搭建一個網頁APP常用的是Python結合Flask或者Django框架來貫穿前後端來搭建網頁。利用這個方法一般需要一定的前端經驗,來修改CSS、HTML、JAVASCRIPT這些文件。而對於沒有前端經驗的coder,讀者這裡推薦一款友好的全程基於Python的庫streamlit,也就是本文所用到的庫。利用streamlit可以輕松快速的搭建一個網頁APP,再加入文本挖掘功能。這樣,就做出了一個小產品。下面,進入正題。
本文采用Anaconda進行Python編譯,主要涉及的Python模塊:
streamlit
pandas
cnsenti
stylecloud
time
本章分為三部分講解:
1.數據探索性分析與商品評論文本提取
2.商品評論詞雲圖可視化與情感分析
3.網頁結構設計與實現
4.功能整合與效果呈現
01、數據探索性分析與商品評論文本提取
本文采取的數據為某寧電商平台上的商品評論數據。數據字段有商品標題、價格、評價內容。其中,價格為近期4月份的實時價格。評價內容是按時間順序從近到遠的展現。下面為前五行的展示:
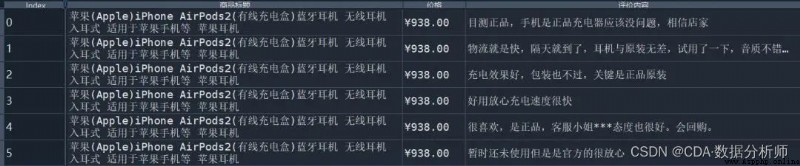
需要注意的是,上面五行顯示的是AirPods第2代的商品信息。原因是數據原本分為3張表,每張表的字段都是一樣的,總共3個,2個維度字段和1個度量字段(這個在CDA I課程中的數據結構會有提及)。因此,這份數據是3張表通過縱向合並方式對記錄進行拼接。最後生成的Index是新表生成的主鍵。
接著可以對數據進行適當的探索性分析,首先習慣性的觀察數據形狀、數據類型以及有沒有缺失值、異常值、重復值。缺失值利用pandas庫的isnull().sum()函數即可查閱。重復值利用duplicated().sum()即可。而重復由於本文探索的是商品評論文本且數據量較少,因此本文忽略不做。下面為各部分結果
數據形狀為(1020,3),這很好理解,就是1020條記錄行,3個字段。數據類型利用info()函數即可,結果如下:

上面結果解析:Non-NULL Count為各個字段的非空數值和。可以看到,評價內容這個維度字段有2個空值。右邊Dtype表明三個字段都是字符串object類型。memory usage為這張上商品信息表格的占用字節空間,有24kb。這裡額外提醒一下,如果一張表格有5G以上,也就是Excel軟件都較難打開時,可以換一種實現方式,使用dask庫,是一種分布式的數據處理package。
從上圖info信息中可以知道,這張商品信息表的空處有2個,也就是缺失值為2。而重復值計算得到為19個。接下來就是解決缺失值和重復值的方法,考慮到重復值多次出現會影響到後續詞頻統計的結果,本文考慮將重復值剔除。而缺失值會影響後面對評價內容分詞的步驟,因此這裡選擇用空格進行替換。整段代碼如下,剛開始轉用Python的小伙伴可以牢記這段代碼,這幾乎是每次數據分析必用的。
import pandas as pd
df = pd.read_excel(‘蘇寧易購_airpods系列.xlsx’)
df.isnull().sum() # 缺失值匯總
df.duplicated().sum() # 重復值匯總
df.info() # 表格信息abstract
df.dtypes #數據類型
df[‘評價內容’] = df[‘評價內容’].fillna(’ ') # 空格填充
df = df.drop_duplicates() # 剔除重復值
在3個字段中,最需要提取的是評價內容,因為本文的目的是建立一個商品評論文本信息挖掘系統,功能包括情感分析、詞雲圖可視化。而每個用戶ID的評價內容都是不一致的,因此,需要去做聚合運算。整合所有評價內容,同時去除停用詞,最後形成一句話,雖然這句話是不通順,但是對後面的詞頻統計沒有影響。
整合評價內容采用Python的內置函數split()完成,首先利用Pandas庫中的tolist()函數將評價內容字段的記錄變為一個列表,接著將列表轉換為字符串,這裡需要用到split()函數完成。以空格字符串作為連接符,連接列表裡的每一個元素。最終形成的效果截取一部分如下:

之後就是去除停用詞,停用詞無論是中文NLP任務還是英文NLP任務,都需要用到這一步。這一步不僅可以去除大部分噪音,同時也能節省計算資源,更加高效。去除停用詞的算法其實很簡單,就是遍歷需要做統計挖掘的文本,如果文本中有單詞是屬於指定的停用詞的,就剔除。顯然,這裡就需要停用詞庫,停用詞庫有很多,有百度的停用詞表、有哈工大停用詞表、有四川大學機器智能實驗室停用表等。本文選擇哈工大停用詞表,因為此表相較於其他表有對電子商務領域較好的單詞。讀者若是想做一個理想的項目,可以考慮自建電子商務領域的停用詞表。
去除停用詞具體的代碼及做法將在情感分析處講解。
02、商品評論詞雲圖可視化與情感分析
上一部分我們提取了商品信息表格中的每個ID的商品評價內容,同時對其整合進行去停用詞,得到了一份干淨的txt數據集。接下來就可以進行文本挖掘的事情了。首先是商品評論詞雲圖構建。
在Python中詞雲圖構建的庫有很多,常用的就是Wordcloud標准的詞雲圖可視化庫,還有pyecharts的詞雲圖API。前者在構建詞雲圖時,新手使用者往往會出現一大堆問題,比如pip安裝失敗、編碼錯誤、字體使用錯誤等,除此之外,其使用難度其實也是蠻大的。而後者則是常用於浏覽器上的交互式圖表,其以代碼量,封裝性高所出名,聽起來是比較切合本文這個主題的,但是本文卻沒有考慮,原因是後面所用到的網頁開發庫streamlit要顯示交互式圖表通常不用pyecharts。
因此,這裡本文引出新興的詞雲圖可視化庫stylecloud,這個庫是基於wordcloud的。運用這個庫,新手可以以最少的代碼量畫出各色各樣的詞雲圖,支持形狀設置。話不多說,直接上代碼:
start = time.time() #記錄初始時間
stop_words = open(‘哈工大停用詞表.txt’,‘r’,encoding=‘utf8’).readlines() # 讀取停用詞
stylecloud.gen_stylecloud(text=txt, collocations=True, # 是否包括兩個單詞的搭配(二字組)
font_path=r’C:\Windows\Fonts\simkai.ttf’, # 指定字體
icon_name=‘fab fa-jedi-order’,size=(2000,2000), # 指定樣式
output_name=r’img\詞雲圖.png’, #指定輸出圖像文件路徑
custom_stopwords=stop_words) # 指定停用詞表
end = time.time() # 記錄結束時間
spend = end-start # 畫圖時間總長
代碼解析:
首先引入stylecloud庫,而後使用.gen_stylecloud()對象來初始化畫圖對象(類)。
text參數代表著目標文本,即我們已經處理好的商品評論txt文本。
collocations代表為是否包括兩個單詞的搭配(二字組),默認為True。
font_path為本機自帶的字體,默認位置是C:\Windows\Fonts\這個文件夾,使用者可以根據喜好選擇這個文件夾裡面任何一種字體,也可以額外下載。
icon_name這個參數可以說是stylecloud庫的靈魂之處,它可以設置蒙版圖的形式。當然,這個參數不能亂寫。創作過詞雲圖的朋友都知道,自己設置蒙版圖樣式是有趣但是會出現分辨率極低的問題。為解決這個問題,Font Awesome實現了絕佳的方案,即構造一套以矢量形式存放圖標字體庫與CSS框架,供使用者調用。使用者不僅可以調出高清的圖標,並且可以自定義其中的CSS文件,加入或者修改到合自己胃口的樣式。而stylecloud這個庫就是調用這個網站的所用內容,使用者可以在stylecloud\static文件夾中找到fontawesome.min.cssCSS文件,這裡面包含了很多矢量圖標。
讀者會問,怎麼知道這些圖標的name?下面提供兩個網站:
https://fontawesome.dashgame.com/。這裡面就是存放各種矢量圖標的名稱,使用者可以使用不同類別的圖標樣式,其中手勢相關樣式如下圖:
size為圖片大小。
output_name為輸出圖片的所在路徑及名字
custom_stopwords為引用我們自定義的停用詞庫,即一開始用open函數代碼調出哈工大停用詞表,下面截取停用詞表一部分作為展示,可以看到一開始都是去除無用的標點負號
除此之外,本文還設置了時間間隔,因為眾說周知詞雲圖的刻畫需要較長時間,如果文本較長,一分鐘也有可能。所以加上時間的概念,對使用者進行數據調入也會友好一些。
這樣,我們就構建好了詞雲圖,將在下一部分網頁端應用,這裡以Airpods第二代舉例,先上效果圖

詞雲圖構建完以後就是輪到情感分析,對干淨的商品評論信息做情感分析是非常有用的。對商家而言可以清楚知道買方使用此產品的感覺與評價,以便後面優化產品,而對想要買此產品的人更加有借鑒。本文將對AirPods商品評論進行情感詞正負情感詞統計。
利用到的庫是cnsenti,這個庫是中文情感分析庫。在NLP任務領域中,大多庫與例子都是英文的,因此這個中文庫對於經常對中文文本進行挖掘的人是個好消息!
首先先介紹下這個庫把吧,cnsenti模塊中分為兩大部分,一個是本文用到的情感分析對象Sentiment,另一個是沒有用到的情緒分析對象Emotion。情感分析使用的詞典是知網Hownet,支持自定義。情緒分析使用的是大連理工大學情感本體庫,可以計算文本中的七大情緒詞分布。由於本文只使用情感分析對象類,因此感興趣的讀者可以自行學習情緒分析類。
對AirPods商品評論信息進行情感分析,在默認條件下,只用2句代碼即可。是的,就是那麼方便!
senti = Sentiment()
result = senti.sentiment_count(txt)
txt為我們的目標文本,首先需要調用情感分析類Sentiment(),如果不設置任何參數,即表明以默認條件初始化。接著使用sentiment_count()函數計算正負情感詞統計,以AirPods第二代舉例,實現結果如下:

上面結果說明:總共單詞有18128個,句子有625句。積極的情感詞語有2221,消極的情感詞語有322個。
在情感分析類中,除了sentiment_count()函數,還有sentiment_calculate()函數,有什麼區別呢?這個可更加精准的計算文本的情感信息。相比於sentiment_count只統計文本正負情感詞個數,sentiment_calculate還考慮了情感詞前後是否強度副詞去修飾,情感詞前後是否有否定詞的情感語義反轉作用。同樣以AirPods產品舉例,使用這個函數,得到的結果為

可以看到,識別出來的積極詞匯應該是使用了加權的手段將頻率升維到數值。
03、網頁結構設計與實現
接下來就是網頁結構設計,做網頁首先就是構造出一個思路圖,確定功能是什麼,有哪些控件,控件擺放位置如何。對於功能,本文的主題是商品評論信息文本挖掘,先對商品評論初始文本進行整合於去停用詞。而後利用stylecloud庫進行詞雲圖構建,最後進行情感分析。除此之外,作者還希望完成一下功能:
各類產品(3代AirPods智能耳機)分開進行分析,即不同於上面部分步驟,不需要通過字段進行記錄縱向合並。
可以在網頁端顯示原本的表結構類型數據。
加入一些由markdown編寫的簡介
通過一個dataframe原表格和文本挖掘結果分開顯示
確定功能就是以上這些了。通過上面的功能,本文可以確定有哪寫控件:
文本控件,用來存儲簡介、正負情感詞數值比、詞雲圖構建花費時間second。
圖像(graph)控件,用來存儲本地存儲好的詞雲圖,以在web 端展示。
dataframe控件,用來顯示原始表結構類型數據
sidebar側邊欄控件,相當於平時我們在各大網站看到的側邊欄目錄一樣,不過本文在側邊欄的功能是不一樣的。
側邊欄下的文本控件。
selectbox單項下拉選擇框控件,存儲AirPods各型號,相當於完成分類型分析的功能
radio單選按鈕控件,存儲顯示類型:原表結構數據類型或者文本挖掘結果顯示。
按照常規的網頁構建,控件位置的空間擺設是一定要設計的。但是對於新手來說,接下來講的超級web app建設streamlit則不需要考慮了。
streamlit的官方(https://streamlit.io/)簡介如下:
以最快的方式建立於分享數據app,將數據顯示在可分享的web app上,以python編程語言實現,無需前端經驗。Streamlit是第一個專門針對機器學習和數據科學團隊的應用程序開發框架,它是開發自定義機器學習工具的最快的方法,可以幫助機器學習工程師快速開發用戶交互工具。同時它是基於tornado框架,封裝了大量互動組件,同時也支持大量表格、圖表、數據表等對象的渲染,並且支持柵格化響應式布局。Streamlit的默認渲染語言就是markdown;除此以外,Streamlit也支持html文本的渲染,這意味著你也可以將任何html代碼嵌入到streamlit應用裡。
讀者可能會疑惑做網站,以為前後端都用Python+streamlit是一件普通的事情。其實不然,在streamlit建立之前,web creator with python一般采用的是前端使用html、css、JavaScript,後端使用python、Flask、Django。如果不用Python,則是前後端都使用D3。
因此,本文所使用的Python+streamlit前後端貫穿創建web app對新手是多麼的友好!
接著,先展示streamlit的快速使用方法:
首先pip install streamlit安裝這個庫,而後在命令行輸入streamlit hello。這時會彈出一個窗口,這個是內置的打開幫助文檔,裡面有各種實例,下面為一部分截圖:
首先是,記錄著幫助信息的頁面,裡面存放著各種連接

而後在下拉框選擇plotting demo,點擊後顯示如下:
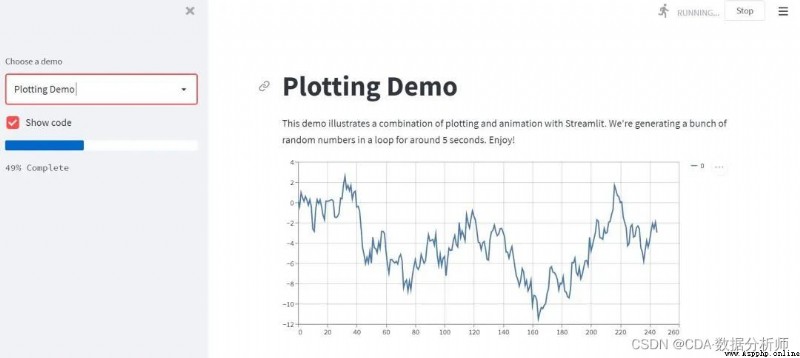
這是一個加載了記錄條的畫圖程序,可以是交互式的。
綜上,就可以發現,運行streamlit不是在anaconda等python編譯器裡面運行的,而是在命令框cmd中輸入streamlit run .py文件來運行程序的。
有興趣的讀者可以多泡一下streamlit的官網,可以學習到很多東西。
04、功能整合與效果呈現
最後就是本文的web app構建與功能整合部分。先上代碼
import streamlit as st
import pandas as pd
from cnsenti import Sentiment
import stylecloud
import time
st.title(‘AirPods智能耳機商品評論分析系統’)
st.markdown(‘這個數據分析系統將以可視化形式挖掘某電商公司下蘋果三種AirPods型號的商品評論信息’)
st.markdown(‘Apple AirPods是蘋果品牌的無線耳機。目前有市場上銷售主流是3中機型:AirPods2代、Airpods pro、AirPods三代。這款耳機的主要特點是:耳機內置紅外傳感器能夠自動識別耳機是否在耳朵當中進行自動播放,通過雙擊可以控制Siri控制。帶上耳機自動播放音樂,波束的麥克風效果更好,雙擊耳機開啟Siri,充電盒支持長時間續航,連接非常簡單,只需要打開就可以讓iPhone自動識別。’)
st.sidebar.title(‘數據分析系統控件’)
st.sidebar.markdown(‘選擇一款型號/可視化類型:’)
DATA_URL=(‘蘇寧易購_airpods系列.xlsx’)
def load_data():
data=pd.read_excel(DATA_URL)
return data
df = load_data()
df[‘評價內容’] = df[‘評價內容’].fillna(’ ') # 填充缺失值
select = st.sidebar.selectbox(‘選擇一款型號’,df[‘商品標題’].unique())
state_data = df[df[‘商品標題’] == select]
select_status = st.sidebar.radio(“可視化類型”, (‘表結構數據’,‘文本挖掘’))
if select_status == ‘表結構數據’:
st.text(‘該電商公司近期售賣產品的相關數據(以表結構化顯示)’)
st.dataframe(state_data)
if select_status == ‘評論可視化’:
# 判斷商品正負情感值
txt_list = state_data['評價內容'].tolist()
txt = ' '.join(txt_list)
senti = Sentiment()
result = senti.sentiment_count(txt)
start = time.time()
# 先在內部畫出詞雲圖並保存到image文件夾
stop_words = open('哈工大停用詞表.txt','r',encoding='utf8').readlines()
stylecloud.gen_stylecloud(text=txt, collocations=True,
font_path=r'C:\Windows\Fonts\simkai.ttf',
icon_name='fab fa-jedi-order',size=(2000,2000),
output_name=r'img\詞雲圖.png',
custom_stopwords=stop_words)
end = time.time()
spend = end-start
# 顯示情感正負值在網頁端
if result['pos'] > result['neg']:
st.markdown("#### 該商品的正負情感值比為{}:{},呈積極信號".format(result['pos'],result['neg']))
if result['pos'] < result['neg']:
st.markdown("#### 該商品的正負情感值比為{}:{},呈消極信號".format(result['pos'],result['neg']))
# 顯示詞雲圖
st.image(r'img\詞雲圖.png',caption = '詞雲圖')
st.text('運行時長:{} s'.format(spend))
代碼解析:
首先引入包之後的前五行,是設置這個web app的標題,為AirPods智能耳機商品評論分析系統。然後下面為記錄該程序的簡要信息作為副標題。同時存儲一些AirPods這款蘋果公司旗下的智能手機簡介與它的功能獨特之處。除此之外,st.sidebar()這個函數是將目標從主頁面轉到側邊欄中,在側邊欄填入需要填入的信息。
之後就是第一部分講解的加載數據、數據探索性分析,去除重復值,填充缺失值等操作。
select = st.sidebar.selectbox(‘選擇一款型號’,df[‘商品標題’].unique())這句話就是將商品信息表中的去重商品標題,即AirPods三代的機型作為下拉框單選選擇的值。選擇這個值後,就可以利用pandas進行條件篩選,最後用st.dataframe()函數將這個表結構類型進行顯示。
select_status = st.sidebar.radio(“可視化類型”, (‘表結構數據’,‘文本挖掘’))代表的是設置單選選擇按鈕的值,即主頁面顯示哪種頁面,是表格類型數據,還是文本挖掘結果:詞雲圖與情感分析結果。
if語句的設定如下:根據state_data結果,抽取的數據為為AirPods三代中的一代,那麼記下來主頁顯示的表格數據類型或是情感分析都是基於這一代機型的相關商品信息。接著if語句是判定select_status是表結構數據還是文本挖掘,因為在本文的初始設定中,主頁面上是只顯示兩種可視化的。
而後一個if語句時提供給文本挖掘,也即情感分析用的。在第二部分中有講到,本文時計算正負情感詞的比例。如果正面情感詞(積極情感詞匯),則運行st.markdown(“#### 該商品的正負情感值比為{}:{},呈積極信號”.format(result[‘pos’],result[‘neg’])),顯示積極信號。反之,為消極信號。
這裡有一個time模塊引用,這個引用時計算詞雲圖構建的時間,大約在30s左右。這種性能測試與評估在工作中也是經常用到,因為工作中的數據可不像本文實例中的大小一般。
詞雲圖構建的代碼在第二部分也提及到,這裡直接嵌入到裡面即可。同時利用st.image函數進行本地圖片讀取與顯示。
除此之外,streamlit還有一個友好的點就是,可以支持寫markdown代碼,上面的文本控件大部分都是用markdown編寫,常使用markdown的讀者可以研究一波。
 Simple excel reading and writing problems in Python, similar solutions on the Internet are not well understood
Simple excel reading and writing problems in Python, similar solutions on the Internet are not well understood
The procedure is as follows ,
 pyspark報錯 org.apache.spark.SparkException: Python worker failed to connect back.
pyspark報錯 org.apache.spark.SparkException: Python worker failed to connect back.
解決方法pycharm配置環境變量:PYTHONUNBUFF